360 Repositories
Python pre-trained Libraries

A Pytorch implementation of MoveNet from Google. Include training code and pre-train model.
Movenet.Pytorch Intro MoveNet is an ultra fast and accurate model that detects 17 keypoints of a body. This is A Pytorch implementation of MoveNet fro
 241 Dec 26, 2022
241 Dec 26, 2022

TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning
TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning Authors: Yixuan Su, Fangyu Liu, Zaiqiao Meng, Lei Shu, Ehsan Shareghi, and Nig
 79 Nov 4, 2022
79 Nov 4, 2022

A set of tools to pre-calibrate and calibrate (multi-focus) plenoptic cameras (e.g., a Raytrix R12) based on the libpleno.
COMPOTE: Calibration Of Multi-focus PlenOpTic camEra. COMPOTE is a set of tools to pre-calibrate and calibrate (multifocus) plenoptic cameras (e.g., a
 4 May 10, 2022
4 May 10, 2022
TaCL: Improve BERT Pre-training with Token-aware Contrastive Learning
TaCL: Improve BERT Pre-training with Token-aware Contrastive Learning
26 Oct 17, 2022

Pre-1.0 door/chest sound injector for Minecraft
doorjector Pre-1.0 door/chest sound injector for Minecraft. While the game is running, doorjector hotswaps the new sounds for the old right before the
 1 Nov 20, 2021
1 Nov 20, 2021
[ICCV 2021 Oral] Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Just Ask: Learning to Answer Questions from Millions of Narrated Videos Webpage • Demo • Paper This repository provides the code for our paper, includ
 87 Jan 5, 2023
87 Jan 5, 2023
![[ICCV' 21]](https://github.com/hansen7/OcCo/raw/master/assets/teaser.png)
[ICCV' 21] "Unsupervised Point Cloud Pre-training via Occlusion Completion"
OcCo: Unsupervised Point Cloud Pre-training via Occlusion Completion This repository is the official implementation of paper: "Unsupervised Point Clou
 204 Dec 24, 2022
204 Dec 24, 2022
Tool for automatically reordering python imports. Similar to isort but uses static analysis more.
reorder_python_imports Tool for automatically reordering python imports. Similar to isort but uses static analysis more. Installation pip install reor
 589 Dec 26, 2022
589 Dec 26, 2022
In this Repo a simple Sklearn Model will be trained and pushed to MLFlow
SKlearn_to_MLFLow In this Repo a simple Sklearn Model will be trained and pushed to MLFlow Install This Repo is based on poetry python3 -m venv .venv
 1 Dec 13, 2021
1 Dec 13, 2021
PyTorch implementation of Spiking Neural Networks trained on surrogate gradient & BPTT using snntorch.
snn-localization repo PyTorch implementation of Spiking Neural Networks trained on surrogate gradient & BPTT using snntorch. Install Dependencies Orig
 1 Jan 6, 2022
1 Jan 6, 2022
Chinese Pre-Trained Language Models (CPM-LM) Version-I
CPM-Generate 为了促进中文自然语言处理研究的发展,本项目提供了 CPM-LM (2.6B) 模型的文本生成代码,可用于文本生成的本地测试,并以此为基础进一步研究零次学习/少次学习等场景。[项目首页] [模型下载] [技术报告] 若您想使用CPM-1进行推理,我们建议使用高效推理工具BMI
 1.4k Jan 3, 2023
1.4k Jan 3, 2023
A method to perform unsupervised cross-region adaptation of crop classifiers trained with satellite image time series.
TimeMatch Official source code of TimeMatch: Unsupervised Cross-region Adaptation by Temporal Shift Estimation by Joachim Nyborg, Charlotte Pelletier,
 17 Nov 1, 2022
17 Nov 1, 2022
A Simple Framwork for CV Pre-training Model (SOCO, VirTex, BEiT)
A Simple Framwork for CV Pre-training Model (SOCO, VirTex, BEiT)
 14 Jul 7, 2022
14 Jul 7, 2022
Code for EMNLP2021 paper "Allocating Large Vocabulary Capacity for Cross-lingual Language Model Pre-training"
VoCapXLM Code for EMNLP2021 paper Allocating Large Vocabulary Capacity for Cross-lingual Language Model Pre-training Environment DockerFile: dancingso
 15 Jul 28, 2022
15 Jul 28, 2022
An Open-Source Toolkit for Prompt-Learning.
An Open-Source Framework for Prompt-learning. Overview • Installation • How To Use • Docs • Paper • Citation • What's New? Nov 2021: Now we have relea
 2.3k Jan 7, 2023
2.3k Jan 7, 2023
DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models
DSEE Codes for [Preprint] DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models Xuxi Chen, Tianlong Chen, Yu Cheng, Weizhu Ch
 4 Dec 27, 2021
4 Dec 27, 2021
PyTorch implementation of a Real-ESRGAN model trained on custom dataset
Real-ESRGAN PyTorch implementation of a Real-ESRGAN model trained on custom dataset. This model shows better results on faces compared to the original
 160 Jan 4, 2023
160 Jan 4, 2023
Face recognition with trained classifiers for detecting objects using OpenCV
Face_Detector Face recognition with trained classifiers for detecting objects using OpenCV Libraries required to be installed using pip Command: cv2 n
 0 Oct 31, 2021
0 Oct 31, 2021
a reccurrent neural netowrk that when trained on a peice of text and fed a starting prompt will write its on 250 character text using LSTM layers
RNN-Playwrite a reccurrent neural netowrk that when trained on a peice of text and fed a starting prompt will write its on 250 character text using LS
 1 Oct 29, 2021
1 Oct 29, 2021
With this package, you can generate mixed-integer linear programming (MIP) models of trained artificial neural networks (ANNs) using the rectified linear unit (ReLU) activation function
With this package, you can generate mixed-integer linear programming (MIP) models of trained artificial neural networks (ANNs) using the rectified linear unit (ReLU) activation function. At the moment, only TensorFlow sequential models are supported. Interfaces to either the Pyomo or Gurobi modeling environments are offered.
 40 Dec 27, 2022
40 Dec 27, 2022
A pre-trained model with multi-exit transformer architecture.
ElasticBERT This repository contains finetuning code and checkpoints for ElasticBERT. Towards Efficient NLP: A Standard Evaluation and A Strong Baseli
 48 Dec 14, 2022
48 Dec 14, 2022
ElasticBERT: A pre-trained model with multi-exit transformer architecture.
This repository contains finetuning code and checkpoints for ElasticBERT. Towards Efficient NLP: A Standard Evaluation and A Strong Baseli
48 Dec 14, 2022

Convolutional neural network web app trained to track our infant’s sleep schedule using our Google Nest camera.
Machine Learning Sleep Schedule Tracker What is it? Convolutional neural network web app trained to track our infant’s sleep schedule using our Google
 7 Jul 15, 2022
7 Jul 15, 2022

PyTorch implementation of Octave Convolution with pre-trained Oct-ResNet and Oct-MobileNet models
octconv.pytorch PyTorch implementation of Octave Convolution in Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octa
 273 Dec 18, 2022
273 Dec 18, 2022
Official code for the paper Inverse Problems Leveraging Pre-trained Contrastive Representations.
The official code for the paper "Inverse Problems Leveraging Pre-trained Contrastive Representations" (to appear in NeurIPS 2021).
 16 Oct 24, 2021
16 Oct 24, 2021

This repository contains all source code, pre-trained models related to the paper "An Empirical Study on GANs with Margin Cosine Loss and Relativistic Discriminator"
An Empirical Study on GANs with Margin Cosine Loss and Relativistic Discriminator This is a Pytorch implementation for the paper "An Empirical Study o
 3 Nov 15, 2021
3 Nov 15, 2021

Implementation of CVAE. Trained CVAE on faces from UTKFace Dataset to produce synthetic faces with a given degree of happiness/smileyness.
Conditional Smiles! (SmileCVAE) About Implementation of AE, VAE and CVAE. Trained CVAE on faces from UTKFace Dataset. Using an encoding of the Smile-s
 3 Jan 9, 2022
3 Jan 9, 2022
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
 114 Jan 6, 2023
114 Jan 6, 2023
Implementation of Natural Language Code Search in the project CodeBERT: A Pre-Trained Model for Programming and Natural Languages.
CodeBERT-Implementation In this repo we have replicated the paper CodeBERT: A Pre-Trained Model for Programming and Natural Languages. We are interest
 4 Jul 1, 2022
4 Jul 1, 2022
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
 197 Nov 26, 2022
197 Nov 26, 2022

An NLP library with Awesome pre-trained Transformer models and easy-to-use interface, supporting wide-range of NLP tasks from research to industrial applications.
简体中文 | English News [2021-10-12] PaddleNLP 2.1版本已发布!新增开箱即用的NLP任务能力、Prompt Tuning应用示例与生成任务的高性能推理! 🎉 更多详细升级信息请查看Release Note。 [2021-08-22]《千言:面向事实一致性的生
 6.9k Jan 1, 2023
6.9k Jan 1, 2023
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
111 Dec 18, 2022

Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System Authors: Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai
 123 Dec 23, 2022
123 Dec 23, 2022
SciBERT is a BERT model trained on scientific text.
SciBERT is a BERT model trained on scientific text.
1.2k Dec 24, 2022
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System Authors: Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai
124 Jan 3, 2023

Use PaddlePaddle to reproduce the paper:mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer
MT5_paddle Use PaddlePaddle to reproduce the paper:mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer English | 简体中文 mT5: A Massively
 2 Oct 17, 2021
2 Oct 17, 2021

Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
DeCLIP Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm. Our paper is available in arxiv Updates ** Ou
470 Dec 30, 2022
Self-Supervised Speech Pre-training and Representation Learning Toolkit.
What's New Sep 2021: We host a challenge in AAAI workshop: The 2nd Self-supervised Learning for Audio and Speech Processing! See SUPERB official site
 1.6k Jan 8, 2023
1.6k Jan 8, 2023

Trained on Simulated Data, Tested in the Real World
Trained on Simulated Data, Tested in the Real World
 43 Nov 18, 2022
43 Nov 18, 2022
ImageNet-CoG is a benchmark for concept generalization. It provides a full evaluation framework for pre-trained visual representations which measure how well they generalize to unseen concepts.
The ImageNet-CoG Benchmark Project Website Paper (arXiv) Code repository for the ImageNet-CoG Benchmark introduced in the paper "Concept Generalizatio
 23 Oct 9, 2022
23 Oct 9, 2022
A cross-document event and entity coreference resolution system, trained and evaluated on the ECB+ corpus.
A Comprehensive Comparison of Word Embeddings in Event & Entity Coreference Resolution. Introduction This repo contains experimental code derived from
 2 May 9, 2022
2 May 9, 2022
Code repository for the paper "Doubly-Trained Adversarial Data Augmentation for Neural Machine Translation" with instructions to reproduce the results.
Doubly Trained Neural Machine Translation System for Adversarial Attack and Data Augmentation Languages Experimented: Data Overview: Source Target Tra
 1 Aug 18, 2022
1 Aug 18, 2022

Making self-supervised learning work on molecules by using their 3D geometry to pre-train GNNs. Implemented in DGL and Pytorch Geometric.
3D Infomax improves GNNs for Molecular Property Prediction Video | Paper We pre-train GNNs to understand the geometry of molecules given only their 2D
 95 Dec 30, 2022
95 Dec 30, 2022
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR
UniSpeech The family of UniSpeech: UniSpeech (ICML 2021): Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR UniSpeech-
 282 Jan 9, 2023
282 Jan 9, 2023
Pre-training BERT masked language models with custom vocabulary
Pre-training BERT Masked Language Models (MLM) This repository contains the method to pre-train a BERT model using custom vocabulary. It was used to p
 14 Nov 2, 2022
14 Nov 2, 2022

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023
ICLR 2021: Pre-Training for Context Representation in Conversational Semantic Parsing
SCoRe: Pre-Training for Context Representation in Conversational Semantic Parsing This repository contains code for the ICLR 2021 paper "SCoRE: Pre-Tr
28 Oct 2, 2022

DziriBERT: a Pre-trained Language Model for the Algerian Dialect
DziriBERT DziriBERT is the first Transformer-based Language Model that has been pre-trained specifically for the Algerian Dialect. It handles Algerian
 117 Jan 7, 2023
117 Jan 7, 2023
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modifies the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. OpenPrompt supports loading PLMs directly from huggingface transformers. In the future, we will also support PLMs implemented by other libraries.
2.3k Jan 8, 2023

Google and Stanford University released a new pre-trained model called ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants. For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA. ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
Pre-trained BERT Models for Ancient and Medieval Greek, and associated code for LaTeCH 2021 paper titled - "A Pilot Study for BERT Language Modelling and Morphological Analysis for Ancient and Medieval Greek"
Ancient Greek BERT The first and only available Ancient Greek sub-word BERT model! State-of-the-art post fine-tuning on Part-of-Speech Tagging and Mor
 22 Dec 8, 2022
22 Dec 8, 2022
DziriBERT: a Pre-trained Language Model for the Algerian Dialect
DziriBERT is the first Transformer-based Language Model that has been pre-trained specifically for the Algerian Dialect.
117 Jan 7, 2023
![A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]](https://user-images.githubusercontent.com/33194443/104581604-2592cb00-56a2-11eb-9610-5eaa0afb6e1f.png)
A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]
PINTO_model_zoo Please read the contents of the LICENSE file located directly under each folder before using the model. My model conversion scripts ar
 2.4k Jan 5, 2023
2.4k Jan 5, 2023
PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization using Augmented-Self Reference and Dense Semantic Correspondence) and pre-trained model on ImageNet dataset
Reference-Based-Sketch-Image-Colorization-ImageNet This is a PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization usin
 11 Jul 28, 2022
11 Jul 28, 2022
fastgradio is a python library to quickly build and share gradio interfaces of your trained fastai models.
fastgradio is a python library to quickly build and share gradio interfaces of your trained fastai models.
 34 Jan 5, 2023
34 Jan 5, 2023

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
Git Hooks Tutorial.
Git Hooks Tutorial My public talk about this project at Sberloga: Git Hooks Is All You Need 1. Git Hooks 101 Init git repo: mkdir git_repo cd git_repo
 17 Oct 12, 2022
17 Oct 12, 2022

High level network definitions with pre-trained weights in TensorFlow
TensorNets High level network definitions with pre-trained weights in TensorFlow (tested with 2.1.0 = TF = 1.4.0). Guiding principles Applicability.
 1k Dec 13, 2022
1k Dec 13, 2022
The uncompromising Python code formatter
The Uncompromising Code Formatter “Any color you like.” Black is the uncompromising Python code formatter. By using it, you agree to cede control over
 30.7k Jan 3, 2023
30.7k Jan 3, 2023
The code for the NSDI'21 paper "BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing".
BMC The code for the NSDI'21 paper "BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing". BibTex entry available here. B
 383 Dec 16, 2022
383 Dec 16, 2022
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
1.3k Dec 30, 2022
The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models
Graformer The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models Graformer (also named BridgeTransformer in t
 22 Dec 14, 2022
22 Dec 14, 2022
Code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition"
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
341 Dec 29, 2022
Must-read papers on improving efficiency for pre-trained language models.
Must-read papers on improving efficiency for pre-trained language models.
 89 Jan 3, 2023
89 Jan 3, 2023
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022

A stock information collector and parser for Taiwan and US market. Automatically send LINE message if the pre-defined rules are triggered.
agastock 開發動機 就在海運飆漲的2021年7月,差點跪在地上喜迎財富自由的當下,EPS超高好消息不斷的長榮竟然套在202元一去不回,有圖有真相(哭) 忽然體會到追高殺低不是辦法,魯蛇我得靠邏輯分析也能出頭天,經過三個月無數個不出門的周末,產出簡單的爬蟲和分析工具。 上過金融研訓院的量化交易
 12 Nov 16, 2022
12 Nov 16, 2022
NLPIR tutorial: pretrain for IR. pre-train on raw textual corpus, fine-tune on MS MARCO Document Ranking
pretrain4ir_tutorial NLPIR tutorial: pretrain for IR. pre-train on raw textual corpus, fine-tune on MS MARCO Document Ranking 用作NLPIR实验室, Pre-training
 12 Apr 7, 2022
12 Apr 7, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
7.6k Jan 1, 2023

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023

CVE-2021-26084 - Confluence Pre-Auth RCE OGNL injection
CVE-2021-26084 - Confluence Pre-Auth RCE OGNL injection Usage usage: cve-2021-26084_confluence_rce.py [-h] --url URL [--cmd CMD] [--shell] CVE-2021-2
 92 Jul 20, 2022
92 Jul 20, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
This repo uses a combination of logits and feature distillation method to teach the PSPNet model of ResNet18 backbone with the PSPNet model of ResNet50 backbone. All the models are trained and tested on the PASCAL-VOC2012 dataset.
PSPNet-logits and feature-distillation Introduction This repository is based on PSPNet and modified from semseg and Pixelwise_Knowledge_Distillation_P
 6 Dec 1, 2022
6 Dec 1, 2022
TAPEX: Table Pre-training via Learning a Neural SQL Executor
TAPEX: Table Pre-training via Learning a Neural SQL Executor The official repository which contains the code and pre-trained models for our paper TAPE
157 Dec 28, 2022
Codes to pre-train Japanese T5 models
t5-japanese Codes to pre-train a T5 (Text-to-Text Transfer Transformer) model pre-trained on Japanese web texts. The model is available at https://hug
 37 Dec 25, 2022
37 Dec 25, 2022
This Telegram bot allows you to create direct links with pre-filled text to WhatsApp Chats
WhatsApp API Bot Telegram bot to create direct links with pre-filled text for WhatsApp Chats You can check our bot here. The bot is based on the API p
 17 Aug 20, 2022
17 Aug 20, 2022
Official implementation for ICDAR 2021 paper "Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer"
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer Description Convert offline handwritten mathematical expressi
 87 Dec 27, 2022
87 Dec 27, 2022

Pre-Trained Image Processing Transformer (IPT)
Pre-Trained Image Processing Transformer (IPT) By Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Cha
 332 Dec 18, 2022
332 Dec 18, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023
Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training.
Updates (2020/06/21) Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training. Pyr
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
PyTorch implementation of the Transformer in Post-LN (Post-LayerNorm) and Pre-LN (Pre-LayerNorm).
Transformer-PyTorch A PyTorch implementation of the Transformer from the paper Attention is All You Need in both Post-LN (Post-LayerNorm) and Pre-LN (
 22 Feb 27, 2022
22 Feb 27, 2022
Universal End2End Training Platform, including pre-training, classification tasks, machine translation, and etc.
背景 安装教程 快速上手 (一)预训练模型 (二)机器翻译 (三)文本分类 TenTrans 进阶 1. 多语言机器翻译 2. 跨语言预训练 背景 TrenTrans是一个统一的端到端的多语言多任务预训练平台,支持多种预训练方式,以及序列生成和自然语言理解任务。 安装教程 git clone git
 42 Dec 20, 2022
42 Dec 20, 2022

MASS: Masked Sequence to Sequence Pre-training for Language Generation
MASS: Masked Sequence to Sequence Pre-training for Language Generation
1.1k Dec 17, 2022
Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files
Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files. Mdformat is a Unix-style command-line tool as well as a Python library.
 180 Jan 6, 2023
180 Jan 6, 2023

🐥A PyTorch implementation of OpenAI's finetuned transformer language model with a script to import the weights pre-trained by OpenAI
PyTorch implementation of OpenAI's Finetuned Transformer Language Model This is a PyTorch implementation of the TensorFlow code provided with OpenAI's
 1.4k Jan 5, 2023
1.4k Jan 5, 2023
Implementation of PyTorch-based multi-task pre-trained models
mtdp Library containing implementation related to the research paper "Multi-task pre-training of deep neural networks for digital pathology" (Mormont
 27 Oct 14, 2022
27 Oct 14, 2022

The Hailo Model Zoo includes pre-trained models and a full building and evaluation environment
Hailo Model Zoo The Hailo Model Zoo provides pre-trained models for high-performance deep learning applications. Using the Hailo Model Zoo you can mea
 50 Dec 7, 2022
50 Dec 7, 2022

RoBERTa Marathi Language model trained from scratch during huggingface 🤗 x flax community week
RoBERTa base model for Marathi Language (मराठी भाषा) Pretrained model on Marathi language using a masked language modeling (MLM) objective. RoBERTa wa
 23 Oct 19, 2022
23 Oct 19, 2022

MicRank is a Learning to Rank neural channel selection framework where a DNN is trained to rank microphone channels.
MicRank: Learning to Rank Microphones for Distant Speech Recognition Application Scenario Many applications nowadays envision the presence of multiple
 20 Nov 10, 2022
20 Nov 10, 2022

Official repository for the paper, MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding.
MidiBERT-Piano Authors: Yi-Hui (Sophia) Chou, I-Chun (Bronwin) Chen Introduction This is the official repository for the paper, MidiBERT-Piano: Large-
 137 Dec 15, 2022
137 Dec 15, 2022

Semantic Segmentation of images using PixelLib with help of Pascalvoc dataset trained with Deeplabv3+ framework.
CARscan- Approach 1 - Segmentation of images by detecting contours. It failed because in images with elements along with cars were also getting detect
 5 Jul 29, 2021
5 Jul 29, 2021
Cross-platform .NET Core pre-commit hooks
dotnet-core-pre-commit Cross-platform .NET Core pre-commit hooks How to use Add this to your .pre-commit-config.yaml - repo: https://github.com/juan
 5 Jul 20, 2021
5 Jul 20, 2021
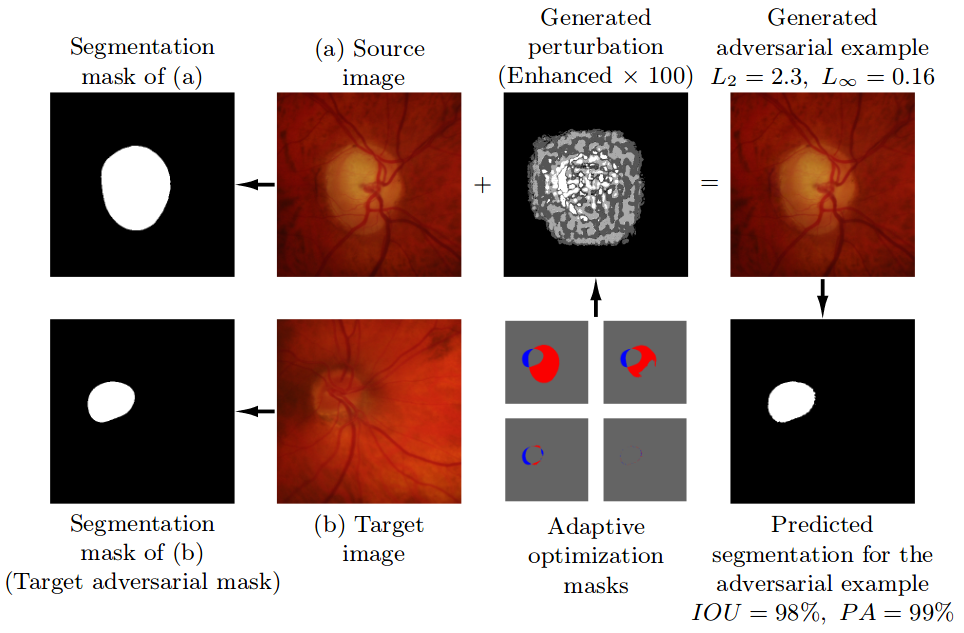
Pre-trained model, code, and materials from the paper "Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation" (MICCAI 2019).
Adaptive Segmentation Mask Attack This repository contains the implementation of the Adaptive Segmentation Mask Attack (ASMA), a targeted adversarial
 53 Jul 4, 2022
53 Jul 4, 2022
A simple pygame dino game which can also be trained and played by a NEAT KI
Dino Game AI Game The game itself was developed with the Pygame module pip install pygame You can also play it yourself by making the dino jump with t
 7 Dec 5, 2022
7 Dec 5, 2022
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
197 Nov 26, 2022

Source code for paper: Knowledge Inheritance for Pre-trained Language Models
Knowledge-Inheritance Source code paper: Knowledge Inheritance for Pre-trained Language Models (preprint). The trained model parameters (in Fairseq fo
31 Nov 19, 2022
The (extremely) naive sentiment classification function based on NBSVM trained on wisesight_sentiment
thai_sentiment The naive sentiment classification function based on NBSVM trained on wisesight_sentiment วิธีติดตั้ง pip install thai_sentiment==0.1.3
 7 Dec 8, 2022
7 Dec 8, 2022