627 Repositories
Python reproducible-science Libraries

Labelling platform for text using distant supervision
With DataQA, you can label unstructured text documents using rule-based distant supervision.
 245 Aug 5, 2022
245 Aug 5, 2022
Model Agnostic Confidence Estimator (MACEST) - A Python library for calibrating Machine Learning models' confidence scores
Model Agnostic Confidence Estimator (MACEST) - A Python library for calibrating Machine Learning models' confidence scores
 95 Dec 28, 2022
95 Dec 28, 2022
collection of interesting Computer Science resources
collection of interesting Computer Science resources
 137 Dec 22, 2022
137 Dec 22, 2022
Obsidian tools - a Python package for analysing an Obsidian.md vault
obsidiantools is a Python package for getting structured metadata about your Obsidian.md notes and analysing your vault.
 153 Jan 4, 2023
153 Jan 4, 2023
A demo of a data science project using Kedro
iris Overview This is your new Kedro project, which was generated using Kedro 0.17.4. Take a look at the Kedro documentation to get started. Rules and
 14 Oct 14, 2022
14 Oct 14, 2022

Rafael Project- Classifying rockets to different types using data science algorithms.
Rocket-Classify Rafael Project- Classifying rockets to different types using data science algorithms. In this project we received data base with data
 5 Sep 18, 2021
5 Sep 18, 2021

Scitizen - Help scientific research for the benefit of mankind and humanity 🔬
Scitizen - Help scientific research for the benefit of mankind and humanity 🔬 Scitizen has been built from the ground up to give everyone the possibi
 21 Mar 8, 2022
21 Mar 8, 2022
CS 506 - Computational Tools for Data Science
CS 506 - Computational Tools for Data Science Code, slides, and notes for Boston University CS506 Fall 2021 The Final Project Repository can be found
 14 Mar 23, 2022
14 Mar 23, 2022
Learn how to responsibly deliver value with ML.
Made With ML Applied ML · MLOps · Production Join 30K+ developers in learning how to responsibly deliver value with ML. 🔥 Among the top MLOps reposit
 32k Dec 30, 2022
32k Dec 30, 2022

Visions provides an extensible suite of tools to support common data analysis operations
Visions And these visions of data types, they kept us up past the dawn. Visions provides an extensible suite of tools to support common data analysis
 168 Dec 28, 2022
168 Dec 28, 2022
An open-source Python project series where beginners can contribute and practice coding.
Python Mini Projects A collection of easy Python small projects to help you improve your programming skills. Table Of Contents Aim Of The Project Cont
 491 Jan 4, 2023
491 Jan 4, 2023

Kedro is an open-source Python framework for creating reproducible, maintainable and modular data science code
A Python framework for creating reproducible, maintainable and modular data science code.
 7.9k Jan 1, 2023
7.9k Jan 1, 2023

Fully reproducible, Dockerized, step-by-step, tutorial on how to mock a "real-time" Kafka data stream from a timestamped csv file. Detailed blog post published on Towards Data Science.
time-series-kafka-demo Mock stream producer for time series data using Kafka. I walk through this tutorial and others here on GitHub and on my Medium
 26 Nov 15, 2022
26 Nov 15, 2022

Lux Academy & Data Science East Africa Python Boot Camp, Building and Deploying Flask Application Using Docker Demo App.
Flask and Docker Application Demo A Docker image is a read-only, inert template that comes with instructions for deploying containers. In Docker, ever
 11 Oct 29, 2022
11 Oct 29, 2022
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

FLAML is a lightweight Python library that finds accurate machine learning models automatically, efficiently and economically
FLAML - Fast and Lightweight AutoML
 2.2k Jan 9, 2023
2.2k Jan 9, 2023

skimpy is a light weight tool that provides summary statistics about variables in data frames within the console.
skimpy Welcome Welcome to skimpy! skimpy is a light weight tool that provides summary statistics about variables in data frames within the console. Th
 267 Dec 29, 2022
267 Dec 29, 2022
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
65 Sep 13, 2022

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
235 Dec 22, 2022

Slack bot for monitoring your Metaflow flows!
Metaflowbot - Slack Bot for your Metaflow flows! Metaflowbot makes it fun and easy to monitor your Metaflow runs, past and present. Imagine starting a
 21 Dec 7, 2022
21 Dec 7, 2022
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark We propose a benchmark to evaluate different quantization algorithms on vari
 494 Dec 29, 2022
494 Dec 29, 2022

A Python package implementing various colour checker detection algorithms and related utilities.
A Python package implementing various colour checker detection algorithms and related utilities.
 147 Dec 29, 2022
147 Dec 29, 2022

Evidently helps analyze machine learning models during validation or production monitoring
Evidently helps analyze machine learning models during validation or production monitoring. The tool generates interactive visual reports and JSON profiles from pandas DataFrame or csv files. Currently 6 reports are available.
 3.1k Jan 7, 2023
3.1k Jan 7, 2023
Write reproducible code for getting and processing ChEMBL
chembl_downloader Don't worry about downloading/extracting ChEMBL or versioning - just use chembl_downloader to write code that knows how to download
 34 Dec 25, 2022
34 Dec 25, 2022

Rubrix is a free and open-source tool for exploring and iterating on data for artificial intelligence projects.
Open-source tool for exploring, labeling, and monitoring data for AI projects
1.5k Jan 7, 2023
MachineLearningStocks is designed to be an intuitive and highly extensible template project applying machine learning to making stock predictions.
Using python and scikit-learn to make stock predictions
 1.3k Jan 3, 2023
1.3k Jan 3, 2023

The MLOps platform for innovators 🚀
DS2.ai is an integrated AI operation solution that supports all stages from custom AI development to deployment. It is an AI-specialized platform service that collects data, builds a training dataset through data labeling, and enables automatic development of artificial intelligence and easy deployment and operation.
 9 Jan 3, 2023
9 Jan 3, 2023

A community run, 5-day PyTorch Deep Learning Bootcamp
Deep Learning Winter School, November 2107. Tel Aviv Deep Learning Bootcamp : http://deep-ml.com. About Tel-Aviv Deep Learning Bootcamp is an intensiv
 1.3k Sep 4, 2021
1.3k Sep 4, 2021
🛠 All-in-one web-based IDE specialized for machine learning and data science.
All-in-one web-based development environment for machine learning Getting Started • Features & Screenshots • Support • Report a Bug • FAQ • Known Issu
 2.9k Jan 9, 2023
2.9k Jan 9, 2023
XGBoost-Ray is a distributed backend for XGBoost, built on top of distributed computing framework Ray.
XGBoost-Ray is a distributed backend for XGBoost, built on top of distributed computing framework Ray.
 92 Dec 14, 2022
92 Dec 14, 2022

A mindmap summarising Machine Learning concepts, from Data Analysis to Deep Learning.
A mindmap summarising Machine Learning concepts, from Data Analysis to Deep Learning.
 5.7k Dec 30, 2022
5.7k Dec 30, 2022

Spectral Tensor Train Parameterization of Deep Learning Layers
Spectral Tensor Train Parameterization of Deep Learning Layers This repository is the official implementation of our AISTATS 2021 paper titled "Spectr
 12 Oct 23, 2022
12 Oct 23, 2022

Azure Cloud Advocates at Microsoft are pleased to offer a 12-week, 24-lesson curriculum all about Machine Learning
Azure Cloud Advocates at Microsoft are pleased to offer a 12-week, 24-lesson curriculum all about Machine Learning
43.4k Jan 4, 2023
Tuplex is a parallel big data processing framework that runs data science pipelines written in Python at the speed of compiled code
Tuplex is a parallel big data processing framework that runs data science pipelines written in Python at the speed of compiled code. Tuplex has similar Python APIs to Apache Spark or Dask, but rather than invoking the Python interpreter, Tuplex generates optimized LLVM bytecode for the given pipeline and input data set.
 791 Jan 4, 2023
791 Jan 4, 2023
A data preprocessing package for time series data. Design for machine learning and deep learning.
A data preprocessing package for time series data. Design for machine learning and deep learning.
 152 Jan 7, 2023
152 Jan 7, 2023

Meerkat provides fast and flexible data structures for working with complex machine learning datasets.
Meerkat makes it easier for ML practitioners to interact with high-dimensional, multi-modal data. It provides simple abstractions for data inspection, model evaluation and model training supported by efficient and robust IO under the hood.
 115 Dec 12, 2022
115 Dec 12, 2022

An intelligent, flexible grammar of machine learning.
An english representation of machine learning. Modify what you want, let us handle the rest. Overview Nylon is a python library that lets you customiz
 79 Dec 2, 2022
79 Dec 2, 2022
flexible time-series processing & feature extraction
tsflex is a toolkit for flexible time-series processing & feature extraction, making few assumptions about input data. Useful links Documentation Exam
 206 Dec 28, 2022
206 Dec 28, 2022

fds is a tool for Data Scientists made by DAGsHub to version control data and code at once.
Fast Data Science, AKA fds, is a CLI for Data Scientists to version control data and code at once, by conveniently wrapping git and dvc
 359 Dec 22, 2022
359 Dec 22, 2022

🧪 Panel-Chemistry - exploratory data analysis and build powerful data and viz tools within the domain of Chemistry using Python and HoloViz Panel.
🧪📈 🐍. The purpose of the panel-chemistry project is to make it really easy for you to do DATA ANALYSIS and build powerful DATA AND VIZ APPLICATIONS within the domain of Chemistry using using Python and HoloViz Panel.
 97 Dec 8, 2022
97 Dec 8, 2022
A site devoted to celebrating to matching books with readers and readers with books. Inspired by the Readers' Advisory process in library science, Literati, and Stitch Fix.
Welcome to Readers' Advisory Greetings, fellow book enthusiasts! Visit Readers' Advisory! Menu Technologies Key Features Database Schema Front End Rou
 6 Dec 12, 2021
6 Dec 12, 2021

A Curated Collection of Awesome Python Scripts
A Curated Collection of Awesome Python Scripts that will make you go wow. This repository will help you in getting those green squares. Hop in and enjoy the journey of open source. 🚀
 248 Dec 31, 2022
248 Dec 31, 2022

A New, Interactive Approach to Learning Python
This is the repository for The Python Workshop, published by Packt. It contains all the supporting project files necessary to work through the course from start to finish.
 231 Dec 26, 2022
231 Dec 26, 2022
pyprobables is a pure-python library for probabilistic data structures
pyprobables is a pure-python library for probabilistic data structures. The goal is to provide the developer with a pure-python implementation of common probabilistic data-structures to use in their work.
 86 Dec 25, 2022
86 Dec 25, 2022
leafmap - A Python package for geospatial analysis and interactive mapping in a Jupyter environment.
A Python package for geospatial analysis and interactive mapping with minimal coding in a Jupyter environment
 1.4k Jan 2, 2023
1.4k Jan 2, 2023

Bachelor's Thesis in Computer Science: Privacy-Preserving Federated Learning Applied to Decentralized Data
federated is the source code for the Bachelor's Thesis Privacy-Preserving Federated Learning Applied to Decentralized Data (Spring 2021, NTNU) Federat
 25 Nov 30, 2022
25 Nov 30, 2022
Orchest is a browser based IDE for Data Science.
Orchest is a browser based IDE for Data Science. It integrates your favorite Data Science tools out of the box, so you don’t have to. The application is easy to use and can run on your laptop as well as on a large scale cloud cluster.
 3.6k Jan 9, 2023
3.6k Jan 9, 2023
An Unsupervised Graph-based Toolbox for Fraud Detection
An Unsupervised Graph-based Toolbox for Fraud Detection Introduction: UGFraud is an unsupervised graph-based fraud detection toolbox that integrates s
 99 Dec 11, 2022
99 Dec 11, 2022
Apache Liminal is an end-to-end platform for data engineers & scientists, allowing them to build, train and deploy machine learning models in a robust and agile way
Apache Liminals goal is to operationalise the machine learning process, allowing data scientists to quickly transition from a successful experiment to an automated pipeline of model training, validation, deployment and inference in production. Liminal provides a Domain Specific Language to build ML workflows on top of Apache Airflow.
 121 Dec 28, 2022
121 Dec 28, 2022
A Lucid Framework for Transparent and Interpretable Machine Learning Models.
Currently a Beta-Version lucidmode is an open-source, low-code and lightweight Python framework for transparent and interpretable machine learning mod
 15 Aug 12, 2022
15 Aug 12, 2022
This repository describes our reproducible framework for assessing self-supervised representation learning from speech
LeBenchmark: a reproducible framework for assessing SSL from speech Self-Supervised Learning (SSL) using huge unlabeled data has been successfully exp
 49 Aug 24, 2022
49 Aug 24, 2022
A computer algebra system written in pure Python
SymPy See the AUTHORS file for the list of authors. And many more people helped on the SymPy mailing list, reported bugs, helped organize SymPy's part
 9.9k Jan 8, 2023
9.9k Jan 8, 2023

Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs (CIKM 2020)
Karate Club is an unsupervised machine learning extension library for NetworkX. Please look at the Documentation, relevant Paper, Promo Video, and Ext
 1.8k Dec 31, 2022
1.8k Dec 31, 2022
Ray provides a simple, universal API for building distributed applications.
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
23.5k Jan 5, 2023
hyppo is an open-source software package for multivariate hypothesis testing.
hyppo (HYPothesis Testing in PythOn, pronounced "Hippo") is an open-source software package for multivariate hypothesis testing.
 137 Dec 18, 2022
137 Dec 18, 2022

A scikit-learn-compatible module for estimating prediction intervals.
|Anaconda|_ MAPIE - Model Agnostic Prediction Interval Estimator MAPIE allows you to easily estimate prediction intervals using your favourite sklearn
 584 Dec 27, 2022
584 Dec 27, 2022
🏅 The Most Comprehensive List of Kaggle Solutions and Ideas 🏅
🏅 Collection of Kaggle Solutions and Ideas 🏅
 2.3k Jan 8, 2023
2.3k Jan 8, 2023
skweak: A software toolkit for weak supervision applied to NLP tasks
Labelled data remains a scarce resource in many practical NLP scenarios. This is especially the case when working with resource-poor languages (or text domains), or when using task-specific labels without pre-existing datasets. The only available option is often to collect and annotate texts by hand, which is expensive and time-consuming.
 850 Dec 28, 2022
850 Dec 28, 2022

Diffgram - Supervised Learning Data Platform
Data Annotation, Data Labeling, Annotation Tooling, Training Data for Machine Learning
 1.6k Jan 7, 2023
1.6k Jan 7, 2023
A Pythonic introduction to methods for scaling your data science and machine learning work to larger datasets and larger models, using the tools and APIs you know and love from the PyData stack (such as numpy, pandas, and scikit-learn).
This tutorial's purpose is to introduce Pythonistas to methods for scaling their data science and machine learning work to larger datasets and larger models, using the tools and APIs they know and love from the PyData stack (such as numpy, pandas, and scikit-learn).
 102 Nov 10, 2022
102 Nov 10, 2022

Algorithmic trading using machine learning.
Algorithmic Trading This machine learning algorithm was built using Python 3 and scikit-learn with a Decision Tree Classifier. The program gathers sto
 101 Nov 10, 2022
101 Nov 10, 2022
Introducing neural networks to predict stock prices
IntroNeuralNetworks in Python: A Template Project IntroNeuralNetworks is a project that introduces neural networks and illustrates an example of how o
 637 Jan 4, 2023
637 Jan 4, 2023

Providing the solutions for high-frequency trading (HFT) strategies using data science approaches (Machine Learning) on Full Orderbook Tick Data.
Modeling High-Frequency Limit Order Book Dynamics Using Machine Learning Framework to capture the dynamics of high-frequency limit order books. Overvi
 1.3k Jan 7, 2023
1.3k Jan 7, 2023
Using python and scikit-learn to make stock predictions
MachineLearningStocks in python: a starter project and guide EDIT as of Feb 2021: MachineLearningStocks is no longer actively maintained MachineLearni
1.3k Dec 29, 2022
Satellite imagery for dummies.
felicette Satellite imagery for dummies. What can you do with this tool? TL;DR: Generate JPEG earth imagery from coordinates/location name with public
 1.8k Jan 3, 2023
1.8k Jan 3, 2023

Processing and interpolating spatial data with a twist of machine learning
Documentation | Documentation (dev version) | Contact | Part of the Fatiando a Terra project About Verde is a Python library for processing spatial da
 468 Dec 20, 2022
468 Dec 20, 2022

Apache Superset is a Data Visualization and Data Exploration Platform
Apache Superset is a Data Visualization and Data Exploration Platform
49.9k Jan 2, 2023
IPython: Productive Interactive Computing
IPython: Productive Interactive Computing Overview Welcome to IPython. Our full documentation is available on ipython.readthedocs.io and contains info
 15.6k Dec 31, 2022
15.6k Dec 31, 2022
🔩 Like builtins, but boltons. 250+ constructs, recipes, and snippets which extend (and rely on nothing but) the Python standard library. Nothing like Michael Bolton.
Boltons boltons should be builtins. Boltons is a set of over 230 BSD-licensed, pure-Python utilities in the same spirit as — and yet conspicuously mis
 6k Jan 4, 2023
6k Jan 4, 2023

Viewflow is an Airflow-based framework that allows data scientists to create data models without writing Airflow code.
Viewflow Viewflow is a framework built on the top of Airflow that enables data scientists to create materialized views. It allows data scientists to f
 114 Oct 12, 2022
114 Oct 12, 2022

Automated Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning
The mljar-supervised is an Automated Machine Learning Python package that works with tabular data. I
 2.4k Jan 2, 2023
2.4k Jan 2, 2023
A probabilistic programming language in TensorFlow. Deep generative models, variational inference.
Edward is a Python library for probabilistic modeling, inference, and criticism. It is a testbed for fast experimentation and research with probabilis
 4.7k Jan 9, 2023
4.7k Jan 9, 2023
Probabilistic reasoning and statistical analysis in TensorFlow
TensorFlow Probability TensorFlow Probability is a library for probabilistic reasoning and statistical analysis in TensorFlow. As part of the TensorFl
 3.8k Jan 5, 2023
3.8k Jan 5, 2023
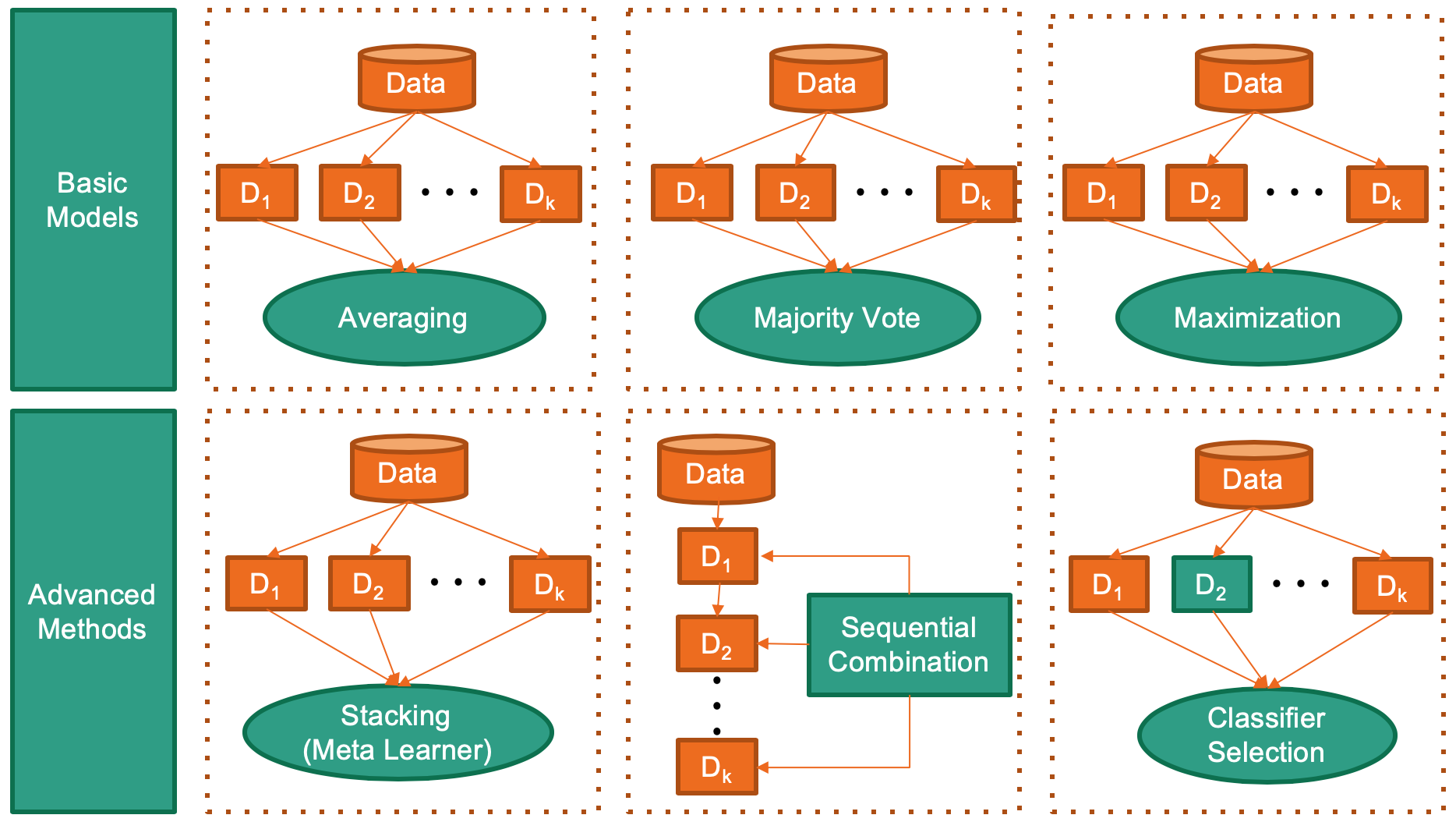
(AAAI' 20) A Python Toolbox for Machine Learning Model Combination
combo: A Python Toolbox for Machine Learning Model Combination Deployment & Documentation & Stats Build Status & Coverage & Maintainability & License
 606 Dec 21, 2022
606 Dec 21, 2022
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2021 Links Doc
 4.2k Dec 28, 2022
4.2k Dec 28, 2022
A Python Package to Tackle the Curse of Imbalanced Datasets in Machine Learning
imbalanced-learn imbalanced-learn is a python package offering a number of re-sampling techniques commonly used in datasets showing strong between-cla
 6.2k Jan 1, 2023
6.2k Jan 1, 2023

A simplified framework and utilities for PyTorch
Here is Poutyne. Poutyne is a simplified framework for PyTorch and handles much of the boilerplating code needed to train neural networks. Use Poutyne
 534 Dec 17, 2022
534 Dec 17, 2022
BlazingSQL is a lightweight, GPU accelerated, SQL engine for Python. Built on RAPIDS cuDF.
A lightweight, GPU accelerated, SQL engine built on the RAPIDS.ai ecosystem. Get Started on app.blazingsql.com Getting Started | Documentation | Examp
 1.8k Jan 2, 2023
1.8k Jan 2, 2023

Distributed scikit-learn meta-estimators in PySpark
sk-dist: Distributed scikit-learn meta-estimators in PySpark What is it? sk-dist is a Python package for machine learning built on top of scikit-learn
 282 Dec 9, 2022
282 Dec 9, 2022
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
Ray provides a simple, universal API for building distributed applications. Ray is packaged with the following libraries for accelerating machine lear
23.3k Dec 31, 2022

A Python library for detecting patterns and anomalies in massive datasets using the Matrix Profile
matrixprofile-ts matrixprofile-ts is a Python 2 and 3 library for evaluating time series data using the Matrix Profile algorithms developed by the Keo
 696 Dec 26, 2022
696 Dec 26, 2022
Python module for machine learning time series:
seglearn Seglearn is a python package for machine learning time series or sequences. It provides an integrated pipeline for segmentation, feature extr
 536 Dec 29, 2022
536 Dec 29, 2022
STUMPY is a powerful and scalable Python library for computing a Matrix Profile, which can be used for a variety of time series data mining tasks
STUMPY STUMPY is a powerful and scalable library that efficiently computes something called the matrix profile, which can be used for a variety of tim
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
A unified framework for machine learning with time series
Welcome to sktime A unified framework for machine learning with time series We provide specialized time series algorithms and scikit-learn compatible
 6k Jan 6, 2023
6k Jan 6, 2023

Automatic extraction of relevant features from time series:
tsfresh This repository contains the TSFRESH python package. The abbreviation stands for "Time Series Feature extraction based on scalable hypothesis
 7k Jan 6, 2023
7k Jan 6, 2023
Documentation and samples for ArcGIS API for Python
ArcGIS API for Python ArcGIS API for Python is a Python library for working with maps and geospatial data, powered by web GIS. It provides simple and
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

Open-L2O: A Comprehensive and Reproducible Benchmark for Learning to Optimize Algorithms
Open-L2O This repository establishes the first comprehensive benchmark efforts of existing learning to optimize (L2O) approaches on a number of proble
 161 Jan 2, 2023
161 Jan 2, 2023
"Very simple but works well" Computer Vision based ID verification solution provided by LibraX.
ID Verification by LibraX.ai This is the first free Identity verification in the market. LibraX.ai is an identity verification platform for developers
 46 Dec 6, 2022
46 Dec 6, 2022

A collection of full-stack resources for programmers.
A collection of full-stack resources for programmers.
 22.3k Dec 30, 2022
22.3k Dec 30, 2022
TorchMetrics is a collection of 25+ PyTorch metrics implementations and an easy-to-use API to create custom metrics.
Machine learning metrics for distributed, scalable PyTorch applications.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
🦉Data Version Control | Git for Data & Models
Website • Docs • Blog • Twitter • Chat (Community & Support) • Tutorial • Mailing List Data Version Control or DVC is an open-source tool for data sci
 10.9k Jan 9, 2023
10.9k Jan 9, 2023

Capture all information throughout your model's development in a reproducible way and tie results directly to the model code!
Rubicon Purpose Rubicon is a data science tool that captures and stores model training and execution information, like parameters and outcomes, in a r
 97 Jan 3, 2023
97 Jan 3, 2023
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
 10k Jan 1, 2023
10k Jan 1, 2023
An extension to pandas dataframes describe function.
pandas_summary An extension to pandas dataframes describe function. The module contains DataFrameSummary object that extend describe() with: propertie
 450 Dec 30, 2022
450 Dec 30, 2022
Supervised domain-agnostic prediction framework for probabilistic modelling
A supervised domain-agnostic framework that allows for probabilistic modelling, namely the prediction of probability distributions for individual data
112 Oct 23, 2022
A fork of OpenAI Baselines, implementations of reinforcement learning algorithms
Stable Baselines Stable Baselines is a set of improved implementations of reinforcement learning algorithms based on OpenAI Baselines. You can read a
 3.7k Jan 1, 2023
3.7k Jan 1, 2023
A scikit-learn-compatible Python implementation of ReBATE, a suite of Relief-based feature selection algorithms for Machine Learning.
Master status: Development status: Package information: scikit-rebate This package includes a scikit-learn-compatible Python implementation of ReBATE,
 374 Dec 15, 2022
374 Dec 15, 2022
A fast xgboost feature selection algorithm
BoostARoota A Fast XGBoost Feature Selection Algorithm (plus other sklearn tree-based classifiers) Why Create Another Algorithm? Automated processes l
 187 Dec 22, 2022
187 Dec 22, 2022
Automatic extraction of relevant features from time series:
tsfresh This repository contains the TSFRESH python package. The abbreviation stands for "Time Series Feature extraction based on scalable hypothesis
7k Jan 3, 2023