627 Repositories
Python reproducible-science Libraries
Artificial Conversational Entity for queries in Eulogio "Amang" Rodriguez Institute of Science and Technology (EARIST)
🤖 Coeus - EARIST A.C.E 💬 Coeus is an Artificial Conversational Entity for queries in Eulogio "Amang" Rodriguez Institute of Science and Technology,
 3 Oct 14, 2022
3 Oct 14, 2022

Python Jupyter kernel using Poetry for reproducible notebooks
Poetry Kernel Use per-directory Poetry environments to run Jupyter kernels. No need to install a Jupyter kernel per Python virtual environment! The id
 204 Jan 4, 2023
204 Jan 4, 2023
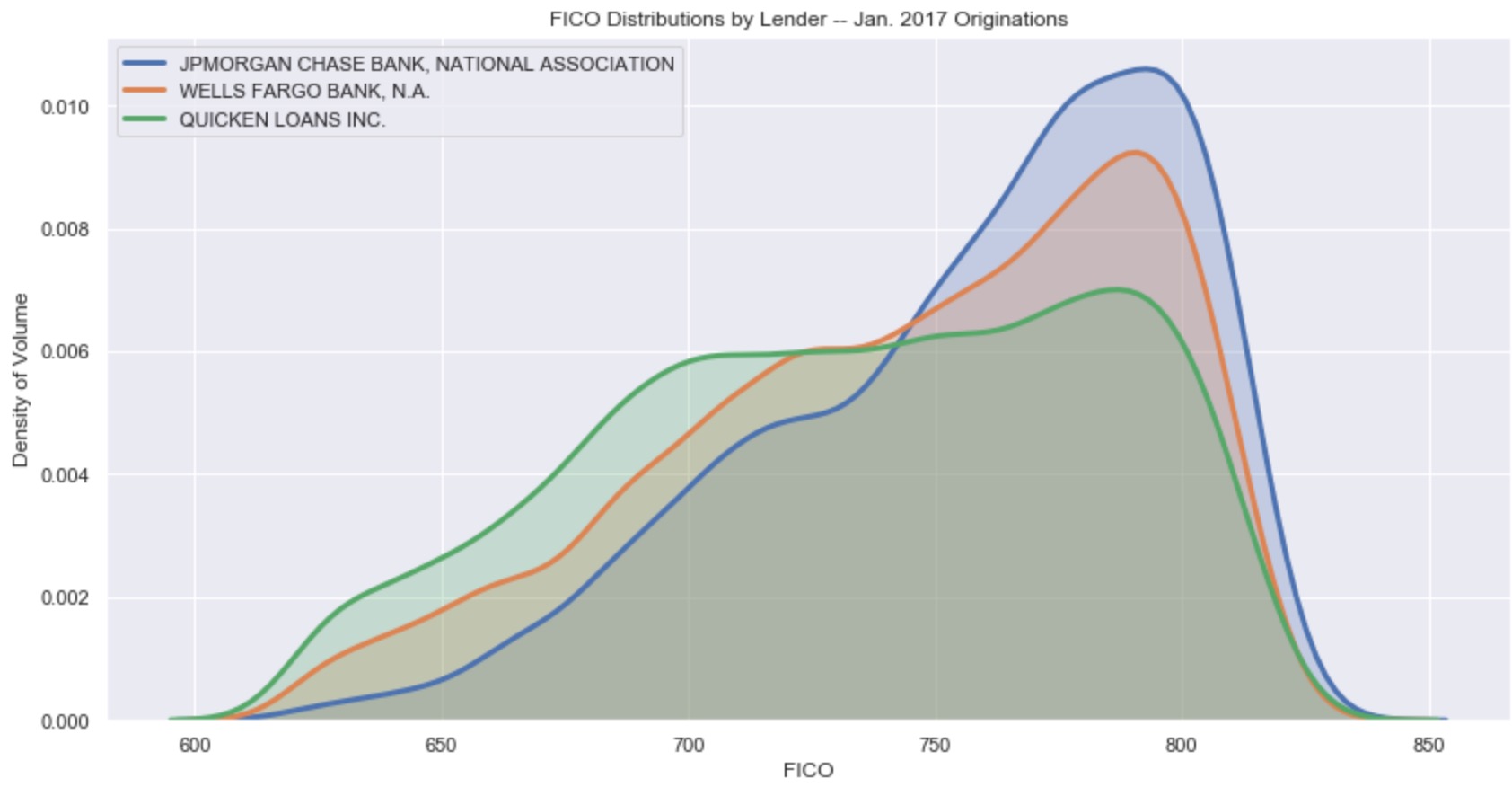
Resources for teaching & learning practical data visualization with python.
Practical Data Visualization with Python Overview All views expressed on this site are my own and do not represent the opinions of any entity with whi
 98 Sep 24, 2022
98 Sep 24, 2022
This library is a location of the LegacyLogger for PyTorch Lightning.
neptune-contrib Documentation See neptune-contrib documentation site Installation Get prerequisites python versions 3.5.6/3.6 are supported Install li
 26 Oct 7, 2021
26 Oct 7, 2021

Example Code Notebooks for Data Visualization in Python
This repository contains sample code scripts for creating awesome data visualizations from scratch using different python libraries (such as matplotli
 27 Jan 4, 2023
27 Jan 4, 2023
A Boilerplate repo for Scientific Python Open Science projects
A Boilerplate repo for Scientific Python Open Science projects Installation Clone this repo If you need a fresh python environment, run $ conda env cr
 2 Dec 23, 2021
2 Dec 23, 2021
AKShare is an elegant and simple financial data interface library for Python, built for human beings
AKShare is an elegant and simple financial data interface library for Python, built for human beings
 5.8k Dec 30, 2022
5.8k Dec 30, 2022
Monitor the stability of a pandas or spark dataframe ⚙︎
Population Shift Monitoring popmon is a package that allows one to check the stability of a dataset. popmon works with both pandas and spark datasets.
 403 Dec 7, 2022
403 Dec 7, 2022
CleverCSV is a Python package for handling messy CSV files.
CleverCSV is a Python package for handling messy CSV files. It provides a drop-in replacement for the builtin CSV module with improved dialect detection, and comes with a handy command line application for working with CSV files.
 1k Dec 19, 2022
1k Dec 19, 2022
A Python wrapper API for operating and working with the Neo4j Graph Data Science (GDS) library
gdsclient NOTE: This is a work in progress and many GDS features are known to be missing or not working properly. This repo hosts the sources for gdsc
 100 Dec 20, 2022
100 Dec 20, 2022
All course materials for the Zero to Mastery Machine Learning and Data Science course.
Zero to Mastery Machine Learning Welcome! This repository contains all of the code, notebooks, images and other materials related to the Zero to Maste
 1.6k Jan 8, 2023
1.6k Jan 8, 2023
🔮 A usefull set of scripts to dig into your Discord data package.
Discord DataExtractor 🔮 Discord DataExtractor is a set of scripts that allows you to dig into your Discord Data package. Repository guide ☕ Coffee_Ga
 3 Dec 29, 2021
3 Dec 29, 2021
A Python wrapper API for operating and working with the Neo4j Graph Data Science (GDS) library
gdsclient This repo hosts the sources for gdsclient, a Python wrapper API for operating and working with the Neo4j Graph Data Science (GDS) library. g
 101 Jan 5, 2023
101 Jan 5, 2023
The aim is to contain multiple models for materials discovery under a common interface
Aviary The aviary contains: - roost, - wren, cgcnn. The aim is to contain multiple models for materials discovery under a common interface Environment
 20 Jan 6, 2023
20 Jan 6, 2023
Feature Store for Machine Learning
Overview Feast is an open source feature store for machine learning. Feast is the fastest path to productionizing analytic data for model training and
 3.8k Dec 30, 2022
3.8k Dec 30, 2022
Python wrappers to the C++ library SymEngine, a fast C++ symbolic manipulation library.
SymEngine Python Wrappers Python wrappers to the C++ library SymEngine, a fast C++ symbolic manipulation library. Installation Pip See License section
 136 Dec 28, 2022
136 Dec 28, 2022
Political elections, appointment, analysis and visualization in Python
Political elections, appointment, analysis and visualization in Python poli-sci-kit is a Python package for political science appointment and election
 9 Dec 1, 2022
9 Dec 1, 2022
BERT, LDA, and TFIDF based keyword extraction in Python
BERT, LDA, and TFIDF based keyword extraction in Python kwx is a toolkit for multilingual keyword extraction based on Google's BERT and Latent Dirichl
41 Dec 27, 2022
Functions for easily making publication-quality figures with matplotlib.
Data-viz utils 📈 Functions for data visualization in matplotlib 📚 API Can be installed using pip install dvu and then imported with import dvu. You
 16 Sep 15, 2022
16 Sep 15, 2022
A Streamlit web-app for a data-science project that aims to evaluate if the answer to a question is helpful.
How useful is the aswer? A Streamlit web-app for a data-science project that aims to evaluate if the answer to a question is helpful. If you want to l
 1 Dec 17, 2021
1 Dec 17, 2021
Fit models to your data in Python with Sherpa.
Table of Contents Sherpa License How To Install Sherpa Using Anaconda Using pip Building from source History Release History Sherpa Sherpa is a modeli
 134 Jan 7, 2023
134 Jan 7, 2023
A hackerank problems, solution repository
This is a repository for all hackerank challenges kindly note this is for learning purposes and if you wish to contribute, dont hesitate all submision
 1 Dec 20, 2021
1 Dec 20, 2021

A high-performance distributed deep learning system targeting large-scale and automated distributed training.
HETU Documentation | Examples Hetu is a high-performance distributed deep learning system targeting trillions of parameters DL model training, develop
 150 Dec 21, 2022
150 Dec 21, 2022
A configurable, tunable, and reproducible library for CTR prediction
FuxiCTR This repo is the community dev version of the official release at huawei-noah/benchmark/FuxiCTR. Click-through rate (CTR) prediction is an cri
 397 Dec 30, 2022
397 Dec 30, 2022
Simulation and Parameter Estimation in Geophysics
Simulation and Parameter Estimation in Geophysics - A python package for simulation and gradient based parameter estimation in the context of geophysical applications.
 390 Dec 15, 2022
390 Dec 15, 2022
MLReef is an open source ML-Ops platform that helps you collaborate, reproduce and share your Machine Learning work with thousands of other users.
The collaboration platform for Machine Learning MLReef is an open source ML-Ops platform that helps you collaborate, reproduce and share your Machine
 1.4k Dec 27, 2022
1.4k Dec 27, 2022

Predicting Baseball Metric Clusters: Clustering Application in Python Using scikit-learn
Clustering Clustering Application in Python Using scikit-learn This repository contains the prediction of baseball metric clusters using MLB Statcast
 2 Apr 18, 2022
2 Apr 18, 2022

A Django app that creates automatic web UIs for Python scripts.
Wooey is a simple web interface to run command line Python scripts. Think of it as an easy way to get your scripts up on the web for routine data anal
 1.9k Jan 8, 2023
1.9k Jan 8, 2023
Random dataframe and database table generator
Random database/dataframe generator Authored and maintained by Dr. Tirthajyoti Sarkar, Fremont, USA Introduction Often, beginners in SQL or data scien
 249 Jan 8, 2023
249 Jan 8, 2023

easyNeuron is a simple way to create powerful machine learning models, analyze data and research cutting-edge AI.
easyNeuron is a simple way to create powerful machine learning models, analyze data and research cutting-edge AI.
 5 Jun 18, 2022
5 Jun 18, 2022
A system for quickly generating training data with weak supervision
Programmatically Build and Manage Training Data Announcement The Snorkel team is now focusing their efforts on Snorkel Flow, an end-to-end AI applicat
 5.4k Jan 2, 2023
5.4k Jan 2, 2023
Flexible HDF5 saving/loading and other data science tools from the University of Chicago
deepdish Flexible HDF5 saving/loading and other data science tools from the University of Chicago. This repository also host a Deep Learning blog: htt
 255 Dec 10, 2022
255 Dec 10, 2022
A common, beautiful interface to tabular data, no matter the format
rows No matter in which format your tabular data is: rows will import it, automatically detect types and give you high-level Python objects so you can
 834 Jan 3, 2023
834 Jan 3, 2023
MDAnalysis is a Python library to analyze molecular dynamics simulations.
MDAnalysis Repository README [*] MDAnalysis is a Python library for the analysis of computer simulations of many-body systems at the molecular scale,
 933 Dec 28, 2022
933 Dec 28, 2022
A setup script to generate ITK Python Wheels
ITK Python Package This project provides a setup.py script to build ITK Python binary packages and infrastructure to build ITK external module Python
 59 Dec 14, 2022
59 Dec 14, 2022
Python Data Structures and Algorithms
No non-sense and no BS repo for how data structure code should be in Python - simple and elegant.
 1.9k Jan 8, 2023
1.9k Jan 8, 2023

 9.3k Jan 7, 2023
9.3k Jan 7, 2023
Machine Learning automation and tracking
The Open-Source MLOps Orchestration Framework MLRun is an open-source MLOps framework that offers an integrative approach to managing your machine-lea
 873 Jan 4, 2023
873 Jan 4, 2023
ZenML 🙏: MLOps framework to create reproducible ML pipelines for production machine learning.
ZenML is an extensible, open-source MLOps framework to create production-ready machine learning pipelines. It has a simple, flexible syntax, is cloud and tool agnostic, and has interfaces/abstractions that are catered towards ML workflows.
 2.6k Dec 27, 2022
2.6k Dec 27, 2022

Kubernetes-native workflow automation platform for complex, mission-critical data and ML processes at scale. It has been battle-tested at Lyft, Spotify, Freenome, and others and is truly open-source.
Flyte Flyte is a workflow automation platform for complex, mission-critical data, and ML processes at scale Home Page · Quick Start · Documentation ·
 3k Jan 1, 2023
3k Jan 1, 2023

Reproducible Data Science at Scale!
Pachyderm: The Data Foundation for Machine Learning Pachyderm provides the data layer that allows machine learning teams to productionize and scale th
 5.7k Dec 29, 2022
5.7k Dec 29, 2022
A simple and lightweight genetic algorithm for optimization of any machine learning model
geneticml This package contains a simple and lightweight genetic algorithm for optimization of any machine learning model. Installation Use pip to ins
 8 Aug 10, 2022
8 Aug 10, 2022
Model Validation Toolkit is a collection of tools to assist with validating machine learning models prior to deploying them to production and monitoring them after deployment to production.
Model Validation Toolkit is a collection of tools to assist with validating machine learning models prior to deploying them to production and monitoring them after deployment to production.
 25 Dec 28, 2022
25 Dec 28, 2022
Applied Machine Learning for Graduate Program in Computer Science (PPGCC)
Applied Machine Learning for Graduate Program in Computer Science (PPGCC) - Federal University of Santa Catarina
 1 Dec 22, 2021
1 Dec 22, 2021
Rapid experimentation and scaling of deep learning models on molecular and crystal graphs.
LitMatter A template for rapid experimentation and scaling deep learning models on molecular and crystal graphs. How to use Clone this repository and
 32 Dec 6, 2022
32 Dec 6, 2022
Projeto job insights - Projeto avaliativo da Trybe do Bloco 32: Introdução à Python
Termos e acordos Ao iniciar este projeto, você concorda com as diretrizes do Código de Ética e Conduta e do Manual da Pessoa Estudante da Trybe. Boas
 1 Dec 9, 2021
1 Dec 9, 2021
A simple and lightweight genetic algorithm for optimization of any machine learning model
geneticml This package contains a simple and lightweight genetic algorithm for optimization of any machine learning model. Installation Use pip to ins
8 Aug 10, 2022
RoadMap and preparation material for Machine Learning and Data Science - From beginner to expert.
ML-and-DataScience-preparation This repository has the goal to create a learning and preparation roadMap for Machine Learning Engineers and Data Scien
 33 Dec 29, 2022
33 Dec 29, 2022
Data Visualizer Web-Application
Viz-It Data Visualizer Web-Application If I ask you where most of the data wrangler looses their time ? It is Data Overview and EDA. Presenting "Viz-I
 17 Nov 20, 2022
17 Nov 20, 2022
UF3: a python library for generating ultra-fast interatomic potentials
Ultra-Fast Force Fields (UF3) S. R. Xie, M. Rupp, and R. G. Hennig, "Ultra-fast interpretable machine-learning potentials", preprint arXiv:2110.00624
 24 Nov 13, 2022
24 Nov 13, 2022
A website for courses of Major Computer Science, NKU
A website for courses of Major Computer Science, NKU
 0 Oct 6, 2022
0 Oct 6, 2022

Sacred is a tool to help you configure, organize, log and reproduce experiments developed at IDSIA.
Sacred Every experiment is sacred Every experiment is great If an experiment is wasted God gets quite irate Sacred is a tool to help you configure, or
 4k Jan 2, 2023
4k Jan 2, 2023

Machine learning model evaluation made easy: plots, tables, HTML reports, experiment tracking and Jupyter notebook analysis.
sklearn-evaluation Machine learning model evaluation made easy: plots, tables, HTML reports, experiment tracking, and Jupyter notebook analysis. Suppo
 354 Dec 31, 2022
354 Dec 31, 2022
Visualize large time-series data in plotly
plotly_resampler enables visualizing large sequential data by adding resampling functionality to Plotly figures. In this Plotly-Resampler demo over 11
 604 Dec 28, 2022
604 Dec 28, 2022

Simple API for UCI Machine Learning Dataset Repository (search, download, analyze)
A simple API for working with University of California, Irvine (UCI) Machine Learning (ML) repository Table of Contents Introduction About Page of the
223 Dec 5, 2022

MS in Data Science capstone project. Studying attacks on autonomous vehicles.
Surveying Attack Models for CAVs Guide to Installing CARLA and Collecting Data Our project focuses on surveying attack models for Connveced Autonomous
 1 Dec 9, 2021
1 Dec 9, 2021
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022
Learn to code in any language. If
Learn to Code It is an intiiative undertaken by Student Ambassadors Club, Jamshoro for students who are absolute begineers in programming and want to
 15 Oct 19, 2022
15 Oct 19, 2022
Multiple Imputation with Random Forests in Python
miceforest: Fast, Memory Efficient Imputation with lightgbm Fast, memory efficient Multiple Imputation by Chained Equations (MICE) with lightgbm. The
 202 Dec 31, 2022
202 Dec 31, 2022
Code for "On Memorization in Probabilistic Deep Generative Models"
On Memorization in Probabilistic Deep Generative Models This repository contains the code necessary to reproduce the experiments in On Memorization in
3 Jun 9, 2022
A Python 3 library making time series data mining tasks, utilizing matrix profile algorithms
MatrixProfile MatrixProfile is a Python 3 library, brought to you by the Matrix Profile Foundation, for mining time series data. The Matrix Profile is
 302 Dec 29, 2022
302 Dec 29, 2022
Primitives for machine learning and data science.
An Open Source Project from the Data to AI Lab, at MIT MLPrimitives Pipelines and primitives for machine learning and data science. Documentation: htt
 65 Dec 29, 2022
65 Dec 29, 2022
This is an example of a reproducible modelling project
An example of a reproducible modelling project What are we doing? This example was created for the 2021 fall lecture series of Stanford's Center for O
 2 Oct 26, 2021
2 Oct 26, 2021

A benchmark dataset for emulating atmospheric radiative transfer in weather and climate models with machine learning (NeurIPS 2021 Datasets and Benchmarks Track)
ClimART - A Benchmark Dataset for Emulating Atmospheric Radiative Transfer in Weather and Climate Models Official PyTorch Implementation Using deep le
 21 Dec 31, 2022
21 Dec 31, 2022
Flexible time series feature extraction & processing
tsflex is a toolkit for flexible time series processing & feature extraction, that is efficient and makes few assumptions about sequence data. Useful
206 Dec 28, 2022

IMBENS: class-imbalanced ensemble learning in Python.
IMBENS: class-imbalanced ensemble learning in Python. Links: [Documentation] [Gallery] [PyPI] [Changelog] [Source] [Download] [知乎/Zhihu] [中文README] [a
 176 Jan 4, 2023
176 Jan 4, 2023
Research code for the paper "Variational Gibbs inference for statistical estimation from incomplete data".
Variational Gibbs inference (VGI) This repository contains the research code for Simkus, V., Rhodes, B., Gutmann, M. U., 2021. Variational Gibbs infer
 1 Apr 8, 2022
1 Apr 8, 2022
Empresas do Brasil (CNPJs)
Biblioteca em Python que coleta informações cadastrais de empresas do Brasil (CNPJ) obtidas de fontes oficiais (Receita Federal) e exporta para um formato legível por humanos (CSV ou JSON).
 8 Aug 17, 2022
8 Aug 17, 2022
Open source platform for Data Science Management automation
Hydrosphere examples This repo contains demo scenarios and pre-trained models to show Hydrosphere capabilities. Data and artifacts management Some mod
 6 Aug 10, 2021
6 Aug 10, 2021
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate.
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate. Website • Key Features • How To Use • Docs •
 21.1k Jan 8, 2023
21.1k Jan 8, 2023
Simple and Distributed Machine Learning
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
Pyserini is a Python toolkit for reproducible information retrieval research with sparse and dense representations.
Pyserini Pyserini is a Python toolkit for reproducible information retrieval research with sparse and dense representations. Retrieval using sparse re
 706 Dec 29, 2022
706 Dec 29, 2022

A collection of online resources to help you on your Tech journey.
Everything Tech Resources & Projects About The Project Coming from an engineering background and looking to up skill yourself on a new field can be di
 396 Dec 31, 2022
396 Dec 31, 2022
A logical, reasonably standardized, but flexible project structure for doing and sharing data science work.
Cookiecutter Data Science A logical, reasonably standardized, but flexible project structure for doing and sharing data science work. Project homepage
 6.4k Jan 2, 2023
6.4k Jan 2, 2023
Advanced Pandas Vault — Utilities, Functions and Snippets (by @firmai).
PandasVault — Advanced Pandas Functions and Code Snippets The only Pandas utility package you would ever need. It has no exotic external dependencies
 374 Jan 7, 2023
374 Jan 7, 2023

PandaPy has the speed of NumPy and the usability of Pandas 10x to 50x faster (by @firmai)
PandaPy "I came across PandaPy last week and have already used it in my current project. It is a fascinating Python library with a lot of potential to
527 Jan 2, 2023
Automatically visualize your pandas dataframe via a single print! 📊 💡
A Python API for Intelligent Visual Discovery Lux is a Python library that facilitate fast and easy data exploration by automating the visualization a
 4.3k Dec 28, 2022
4.3k Dec 28, 2022
Finding project directories in Python (data science) projects, just like there R rprojroot and here packages
Find relative paths from a project root directory Finding project directories in Python (data science) projects, just like there R here and rprojroot
 102 Nov 16, 2022
102 Nov 16, 2022

A DSL for data-driven computational pipelines
"Dataflow variables are spectacularly expressive in concurrent programming" Henri E. Bal , Jennifer G. Steiner , Andrew S. Tanenbaum Quick overview Ne
 1.9k Jan 3, 2023
1.9k Jan 3, 2023

Maze generator and solver with python
Procedural-Maze-Generator-Algorithms Check out my youtube channel : Auctux Ressources Thanks to Jamis Buck Book : Mazes for programmers Requirements P
 19 Dec 7, 2022
19 Dec 7, 2022

Helping you manage your data science projects sanely.
PyDS CLI Helping you manage your data science projects sanely. Requirements Anaconda/Miniconda/Miniforge/Mambaforge (Mambaforge recommended!) git on y
 16 Apr 25, 2022
16 Apr 25, 2022

This repository contains part of the code used to make the images visible in the article "How does an AI Imagine the Universe?" published on Towards Data Science.
Generative Adversarial Network - Generating Universe This repository contains part of the code used to make the images visible in the article "How doe
 9 Dec 18, 2022
9 Dec 18, 2022
eBay's TSV Utilities: Command line tools for large, tabular data files. Filtering, statistics, sampling, joins and more.
Command line utilities for tabular data files This is a set of command line utilities for manipulating large tabular data files. Files of numeric and
 1.4k Jan 9, 2023
1.4k Jan 9, 2023
The fastai book, published as Jupyter Notebooks
English / Spanish / Korean / Chinese / Bengali / Indonesian The fastai book These notebooks cover an introduction to deep learning, fastai, and PyTorc
 17k Jan 7, 2023
17k Jan 7, 2023

Compare MLOps Platforms. Breakdowns of SageMaker, VertexAI, AzureML, Dataiku, Databricks, h2o, kubeflow, mlflow...
Compare MLOps Platforms. Breakdowns of SageMaker, VertexAI, AzureML, Dataiku, Databricks, h2o, kubeflow, mlflow...
 318 Jan 2, 2023
318 Jan 2, 2023
Epidemiology analysis package
zEpid zEpid is an epidemiology analysis package, providing easy to use tools for epidemiologists coding in Python 3.5+. The purpose of this library is
 111 Jan 8, 2023
111 Jan 8, 2023
Skoot is a lightweight python library of machine learning transformer classes that interact with scikit-learn and pandas.
Skoot is a lightweight python library of machine learning transformer classes that interact with scikit-learn and pandas. Its objective is to ex
 54 Aug 20, 2022
54 Aug 20, 2022
dirty_cat is a Python module for machine-learning on dirty categorical variables.
dirty_cat dirty_cat is a Python module for machine-learning on dirty categorical variables.
 637 Dec 29, 2022
637 Dec 29, 2022
apricot implements submodular optimization for the purpose of selecting subsets of massive data sets to train machine learning models quickly.
Please consider citing the manuscript if you use apricot in your academic work! You can find more thorough documentation here. apricot implements subm
 457 Dec 20, 2022
457 Dec 20, 2022

Python+Numpy+OpenGL: fast, scalable and beautiful scientific visualization
Python+Numpy+OpenGL: fast, scalable and beautiful scientific visualization
 1.1k Jan 5, 2023
1.1k Jan 5, 2023
An optimization and data collection toolbox for convenient and fast prototyping of computationally expensive models.
An optimization and data collection toolbox for convenient and fast prototyping of computationally expensive models. Hyperactive: is very easy to lear
 422 Jan 4, 2023
422 Jan 4, 2023
Single-Cell Analysis in Python. Scales to 1M cells.
Scanpy – Single-Cell Analysis in Python Scanpy is a scalable toolkit for analyzing single-cell gene expression data built jointly with anndata. It inc
 1.4k Jan 5, 2023
1.4k Jan 5, 2023

Streamlit — The fastest way to build data apps in Python
Welcome to Streamlit 👋 The fastest way to build and share data apps. Streamlit lets you turn data scripts into sharable web apps in minutes, not week
 22k Jan 6, 2023
22k Jan 6, 2023
The purpose of this project is to share knowledge on how awesome Streamlit is and can be
Awesome Streamlit The fastest way to build Awesome Tools and Apps! Powered by Python! The purpose of this project is to share knowledge on how Awesome
 1.5k Jan 7, 2023
1.5k Jan 7, 2023
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows.
An open-source, low-code machine learning library in Python 🚀 Version 2.3.5 out now! Check out the release notes here. Official • Docs • Install • Tu
 6.7k Jan 8, 2023
6.7k Jan 8, 2023

Visualization ideas for data science
Nuance I use Nuance to curate varied visualization thoughts during my data scientist career. It is not yet a package but a list of small ideas. Welcom
 16 Nov 3, 2022
16 Nov 3, 2022
Python module for data science and machine learning users.
dsnk-distributions package dsnk distribution is a Python module for data science and machine learning that was created with the goal of reducing calcu
 1 Nov 23, 2021
1 Nov 23, 2021
Deep Learning with PyTorch made easy 🚀 !
Deep Learning with PyTorch made easy 🚀 ! Carefree? carefree-learn aims to provide CAREFREE usages for both users and developers. It also provides a c
 381 Dec 22, 2022
381 Dec 22, 2022

BookNLP, a natural language processing pipeline for books
BookNLP BookNLP is a natural language processing pipeline that scales to books and other long documents (in English), including: Part-of-speech taggin
 654 Jan 2, 2023
654 Jan 2, 2023
How to use TensorLayer
How to use TensorLayer While research in Deep Learning continues to improve the world, we use a bunch of tricks to implement algorithms with TensorLay
 349 Dec 7, 2022
349 Dec 7, 2022