1774 Repositories
Python text-summarization-dataset Libraries
Hierarchical Attentive Recurrent Tracking
Hierarchical Attentive Recurrent Tracking This is an official Tensorflow implementation of single object tracking in videos by using hierarchical atte
 147 Aug 7, 2021
147 Aug 7, 2021
Train and use generative text models in a few lines of code.
blather Train and use generative text models in a few lines of code. To see blather in action check out the colab notebook! Installation Use the packa
 16 Nov 7, 2022
16 Nov 7, 2022

A little but useful tool to explore OCR data extracted with `pytesseract` and `opencv`
Screenshot OCR Tool Extracting data from screen time screenshots in iOS and Android. We are exploring 3 options: Simple OCR with no text position usin
 1 Dec 7, 2021
1 Dec 7, 2021
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
 76 Dec 30, 2022
76 Dec 30, 2022

FuseDream: Training-Free Text-to-Image Generationwith Improved CLIP+GAN Space OptimizationFuseDream: Training-Free Text-to-Image Generationwith Improved CLIP+GAN Space Optimization
FuseDream This repo contains code for our paper (paper link): FuseDream: Training-Free Text-to-Image Generation with Improved CLIP+GAN Space Optimizat
 191 Dec 31, 2022
191 Dec 31, 2022

A mini command line tool to spellcheck text files using tadqeek.alsharekh.org
tadqeek_sakhr A mini command line tool to spellcheck text files using tadqeek.alsharekh.org Usage usage: python tadqeek_sakhr.py [-h] -i INPUT [-o OUT
 5 Dec 11, 2022
5 Dec 11, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 0 Mar 20, 2022
0 Mar 20, 2022
Source code and dataset of the paper "Contrastive Adaptive Propagation Graph Neural Networks forEfficient Graph Learning"
CAPGNN Source code and dataset of the paper "Contrastive Adaptive Propagation Graph Neural Networks forEfficient Graph Learning" Paper URL: https://ar
 1 Mar 12, 2022
1 Mar 12, 2022
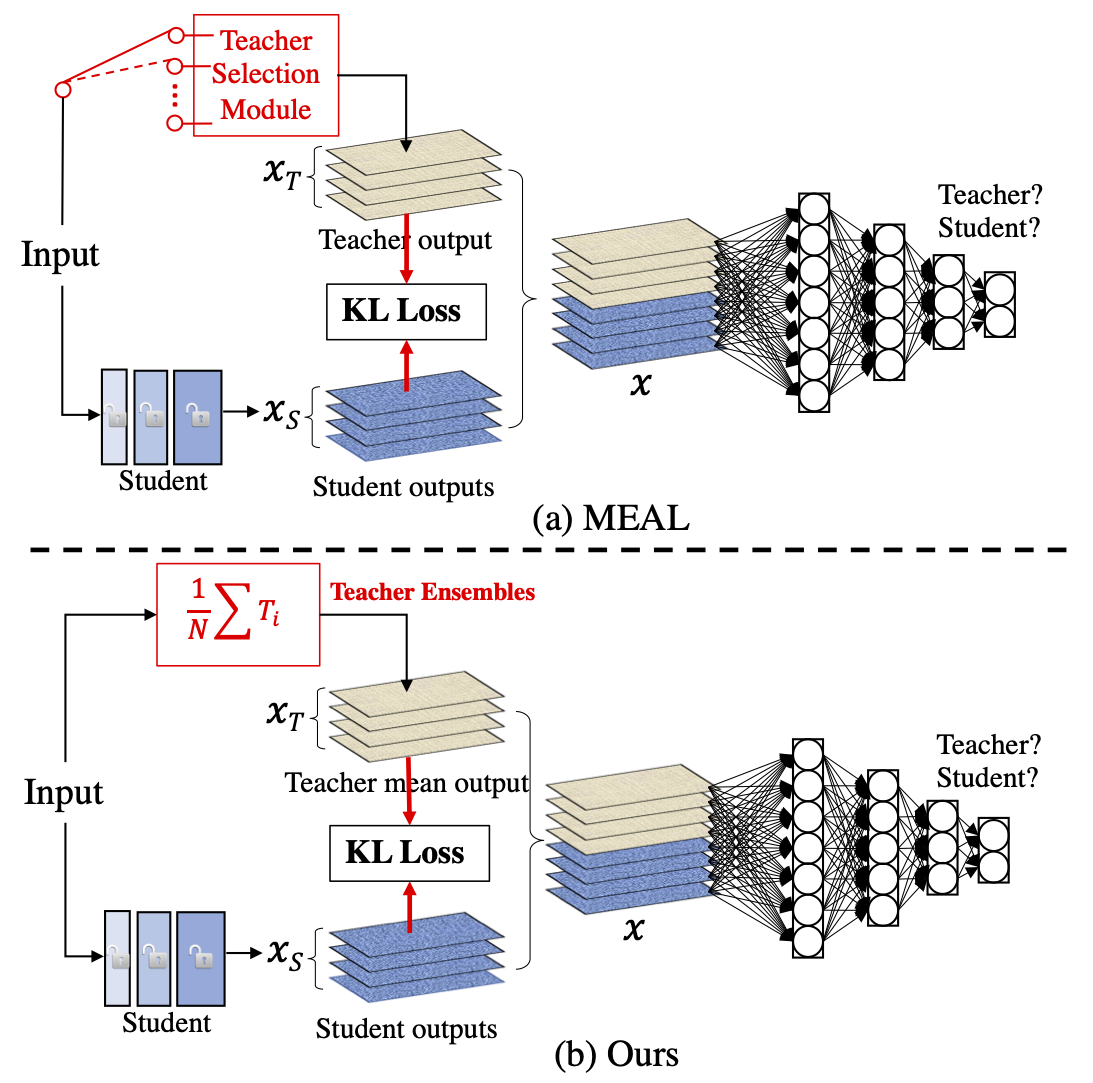
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
MEAL-V2 This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tric
 653 Dec 19, 2022
653 Dec 19, 2022
DaReCzech is a dataset for text relevance ranking in Czech
Dataset DaReCzech is a dataset for text relevance ranking in Czech. The dataset consists of more than 1.6M annotated query-documents pairs,
 8 Jul 26, 2022
8 Jul 26, 2022
This repository contains scripts to control a RGB text fan attached to a Raspberry Pi.
RGB Text Fan Controller This repository contains scripts to control a RGB text fan attached to a Raspberry Pi. Setup The Raspberry Pi and RGB text fan
 1 Oct 1, 2021
1 Oct 1, 2021

Implementation of NÜWA, state of the art attention network for text to video synthesis, in Pytorch
NÜWA - Pytorch (wip) Implementation of NÜWA, state of the art attention network for text to video synthesis, in Pytorch. This repository will be popul
 463 Dec 28, 2022
463 Dec 28, 2022

Implementation of Google Brain's WaveGrad high-fidelity vocoder
WaveGrad Implementation (PyTorch) of Google Brain's high-fidelity WaveGrad vocoder (paper). First implementation on GitHub with high-quality generatio
 363 Dec 27, 2022
363 Dec 27, 2022
DiffWave is a fast, high-quality neural vocoder and waveform synthesizer.
DiffWave DiffWave is a fast, high-quality neural vocoder and waveform synthesizer. It starts with Gaussian noise and converts it into speech via itera
 498 Jan 3, 2023
498 Jan 3, 2023
Neural HMMs are all you need (for high-quality attention-free TTS)
Neural HMMs are all you need (for high-quality attention-free TTS) Shivam Mehta, Éva Székely, Jonas Beskow, and Gustav Eje Henter This is the official
 0 Oct 28, 2022
0 Oct 28, 2022

Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition"
CLIPstyler Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition" Environment Pytorch 1.7.1, Python 3.6 $ c
 201 Dec 29, 2022
201 Dec 29, 2022
public repo for ESTER dataset and modeling (EMNLP'21)
Project / Paper Introduction This is the project repo for our EMNLP'21 paper: https://arxiv.org/abs/2104.08350 Here, we provide brief descriptions of
 19 Oct 27, 2022
19 Oct 27, 2022

Answering Open-Domain Questions of Varying Reasoning Steps from Text
This repository contains the authors' implementation of the Iterative Retriever, Reader, and Reranker (IRRR) model in the EMNLP 2021 paper "Answering Open-Domain Questions of Varying Reasoning Steps from Text".
 26 Dec 22, 2022
26 Dec 22, 2022

3D mesh stylization driven by a text input in PyTorch
Text2Mesh [Project Page] Text2Mesh is a method for text-driven stylization of a 3D mesh, as described in "Text2Mesh: Text-Driven Neural Stylization fo
 649 Dec 27, 2022
649 Dec 27, 2022
A Python script which randomly chooses and prints a file from a directory.
___ ____ ____ _ __ ___ / _ \ | _ \ | _ \ ___ _ __ | '__| / _ \ | |_| || | | || | | | / _ \| '__| | | | __/ | _ || |_| || |_| || __
 0 Aug 6, 2021
0 Aug 6, 2021

A Python script that creates subtitles of a given length from text paragraphs that can be easily imported into any Video Editing software such as FinalCut Pro for further adjustments.
Text to Subtitles - Python This python file creates subtitles of a given length from text paragraphs that can be easily imported into any Video Editin
 9 Dec 24, 2022
9 Dec 24, 2022
Parse Any Text With Python
ParseAnyText A small package to parse strings. What is the work of it? Well It's a module to creates parser that helps to parse a text easily with les
 1 Jan 11, 2022
1 Jan 11, 2022

Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU
GPU Docker NLP Application Deployment Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU, to setup the enviroment on
 9 Oct 14, 2022
9 Oct 14, 2022

Korean extractive summarization. 2021 AI 텍스트 요약 온라인 해커톤 화성갈끄니까팀 코드
korean extractive summarization 2021 AI 텍스트 요약 온라인 해커톤 화성갈끄니까팀 코드 Leaderboard Notice Text Summarization with Pretrained Encoders에 나오는 bertsumext모델(ext
 3 Aug 10, 2022
3 Aug 10, 2022
Encriptificator is a text editor app developed by me as a personal project.
Encriptificator is a text editor app developed by me as a personal project. It provides all basic features of a text editor with the additional feature of encrypting your files. To know more about how to use the encryption features , please read the readme file.
 1 May 9, 2022
1 May 9, 2022
The official homepage of the (outdated) COCO-Stuff 10K dataset.
COCO-Stuff 10K dataset v1.1 (outdated) Holger Caesar, Jasper Uijlings, Vittorio Ferrari Overview Welcome to official homepage of the COCO-Stuff [1] da
 263 Dec 11, 2022
263 Dec 11, 2022

Simple API for UCI Machine Learning Dataset Repository (search, download, analyze)
A simple API for working with University of California, Irvine (UCI) Machine Learning (ML) repository Table of Contents Introduction About Page of the
 223 Dec 5, 2022
223 Dec 5, 2022

Joint Detection and Identification Feature Learning for Person Search
Person Search Project This repository hosts the code for our paper Joint Detection and Identification Feature Learning for Person Search. The code is
 712 Dec 17, 2022
712 Dec 17, 2022

Tensorflow implementation of Semi-supervised Sequence Learning (https://arxiv.org/abs/1511.01432)
Transfer Learning for Text Classification with Tensorflow Tensorflow implementation of Semi-supervised Sequence Learning(https://arxiv.org/abs/1511.01
 82 Oct 22, 2022
82 Oct 22, 2022
TextWorld is a sandbox learning environment for the training and evaluation of reinforcement learning (RL) agents on text-based games.
TextWorld A text-based game generator and extensible sandbox learning environment for training and testing reinforcement learning (RL) agents. Also ch
 983 Dec 23, 2022
983 Dec 23, 2022

End-2-end speech synthesis with recurrent neural networks
Introduction New: Interactive demo using Google Colaboratory can be found here TTS-Cube is an end-2-end speech synthesis system that provides a full p
 214 Dec 7, 2022
214 Dec 7, 2022

Text to speech for Vietnamese, ez to use, ez to update
Chào mọi người, đây là dự án mở nhằm giúp việc đọc được trở nên dễ dàng hơn. Rất cảm ơn đội ngũ Zalo đã cung cấp hạ tầng để mình có thể tạo ra app này
 32 Jul 29, 2022
32 Jul 29, 2022
Simple GUI where you can enter an article and get a crisp summarized version.
Text-Summarization-using-TextRank-BART Simple GUI where you can enter an article and get a crisp summarized version. How to run: Clone the repo Instal
 4 Sep 28, 2022
4 Sep 28, 2022
Source code and dataset for ACL 2019 paper "ERNIE: Enhanced Language Representation with Informative Entities"
ERNIE Source code and dataset for "ERNIE: Enhanced Language Representation with Informative Entities" Reqirements: Pytorch=0.4.1 Python3 tqdm boto3 r
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
UNITER: UNiversal Image-TExt Representation Learning This is the official repository of UNITER (ECCV 2020). This repository currently supports finetun
 680 Dec 24, 2022
680 Dec 24, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
938 Dec 26, 2022
![[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations](https://github.com/kdexd/virtex/raw/master/docs/_static/system_figure.jpg)
[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations
VirTex: Learning Visual Representations from Textual Annotations Karan Desai and Justin Johnson University of Michigan CVPR 2021 arxiv.org/abs/2006.06
 533 Dec 24, 2022
533 Dec 24, 2022
Simple Python library, distributed via binary wheels with few direct dependencies, for easily using wav2vec 2.0 models for speech recognition
Wav2Vec2 STT Python Beta Software Simple Python library, distributed via binary wheels with few direct dependencies, for easily using wav2vec 2.0 mode
 22 Dec 29, 2022
22 Dec 29, 2022

CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer
CSAW-M This repository contains code for CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer. Source code for tr
 7 Oct 11, 2022
7 Oct 11, 2022

PartImageNet is a large, high-quality dataset with part segmentation annotations
PartImageNet: A Large, High-Quality Dataset of Parts We will release our dataset and scripts soon after cleaning and approval. Introduction PartImageN
 77 Nov 30, 2022
77 Nov 30, 2022
A PyTorch Implementation of PGL-SUM from "Combining Global and Local Attention with Positional Encoding for Video Summarization", Proc. IEEE ISM 2021
PGL-SUM: Combining Global and Local Attention with Positional Encoding for Video Summarization PyTorch Implementation of PGL-SUM From "PGL-SUM: Combin
 35 Dec 22, 2022
35 Dec 22, 2022
This is the code for our paper "Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text"
Iconary This is the code for our paper "Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text". It includes the
 6 May 24, 2022
6 May 24, 2022

Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
 2 Dec 2, 2021
2 Dec 2, 2021
Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation
Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation Woncheol Shin1, Gyubok Lee1, Jiyoung Lee1, Joonseok Lee2,3, Edward Ch
 7 Sep 26, 2022
7 Sep 26, 2022
Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition"
CLIPstyler Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition" Environment Pytorch 1.7.1, Python 3.6 $ c
203 Dec 30, 2022
The Malware Open-source Threat Intelligence Family dataset contains 3,095 disarmed PE malware samples from 454 families
MOTIF Dataset The Malware Open-source Threat Intelligence Family (MOTIF) dataset contains 3,095 disarmed PE malware samples from 454 families, labeled
 112 Dec 13, 2022
112 Dec 13, 2022

Artstation-Artistic-face-HQ Dataset (AAHQ)
Artstation-Artistic-face-HQ Dataset (AAHQ) Artstation-Artistic-face-HQ (AAHQ) is a high-quality image dataset of artistic-face images. It is proposed
 105 Dec 16, 2022
105 Dec 16, 2022

This program ingests a Cisco "sh ip arp" as a text file and produces the list of vendors seen in the file
IP-ARP-Vendor_lookup This program ingests a Cisco "sh ip arp" as a text file and produces the list of vendors seen in the file Why? Answers the questi
 1 Dec 24, 2022
1 Dec 24, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
A Model for Natural Language Attack on Text Classification and Inference
TextFooler A Model for Natural Language Attack on Text Classification and Inference This is the source code for the paper: Jin, Di, et al. "Is BERT Re
 418 Dec 16, 2022
418 Dec 16, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
 2.1k Dec 28, 2022
2.1k Dec 28, 2022
This repository contains the code for "Exploiting Cloze Questions for Few-Shot Text Classification and Natural Language Inference"
Pattern-Exploiting Training (PET) This repository contains the code for Exploiting Cloze Questions for Few-Shot Text Classification and Natural Langua
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022

Cooperative Driving Dataset: a dataset for multi-agent driving scenarios
Cooperative Driving Dataset (CODD) The Cooperative Driving dataset is a synthetic dataset generated using CARLA that contains lidar data from multiple
 124 Dec 28, 2022
124 Dec 28, 2022

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023
Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
8 Oct 6, 2022
This is used to convert a string to an Image with Handwritten Characters.
Text-to-Handwriting-using-python This is used to convert a string to an Image with Handwritten Characters. text_to_handwriting(string: str, save_to: s
 3 Aug 15, 2022
3 Aug 15, 2022
A set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI.
Overview This is a set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI. Make TFRecords To run t
 8 Nov 1, 2022
8 Nov 1, 2022

Searches for MAC addresses in a text file of a Cisco "show IP arp" in any address format
show-ip-arp-mac-lookup Searches for MAC addresses in a text file of a Cisco "show IP arp" in any address format What it does: Takes a text file with t
0 Dec 24, 2022
The official homepage of the COCO-Stuff dataset.
The COCO-Stuff dataset Holger Caesar, Jasper Uijlings, Vittorio Ferrari Welcome to official homepage of the COCO-Stuff [1] dataset. COCO-Stuff augment
715 Dec 31, 2022
Python script to download the celebA-HQ dataset from google drive
download-celebA-HQ Python script to download and create the celebA-HQ dataset. WARNING from the author. I believe this script is broken since a few mo
 133 Dec 21, 2022
133 Dec 21, 2022
Line-level Handwritten Text Recognition (HTR) system implemented with TensorFlow.
Line-level Handwritten Text Recognition with TensorFlow This model is an extended version of the Simple HTR system implemented by @Harald Scheidl and
 72 May 7, 2022
72 May 7, 2022
FOTS Pytorch Implementation
News!!! Recognition branch now is added into model. The whole project has beed optimized and refactored. ICDAR Dataset SynthText 800K Dataset detectio
 599 Dec 19, 2022
599 Dec 19, 2022
[3DV 2021] A Dataset-Dispersion Perspective on Reconstruction Versus Recognition in Single-View 3D Reconstruction Networks
dispersion-score Official implementation of 3DV 2021 Paper A Dataset-dispersion Perspective on Reconstruction versus Recognition in Single-view 3D Rec
 7 May 28, 2022
7 May 28, 2022

Dataset for the Research2Clinics @ NeurIPS 2021 Paper: What Do You See in this Patient? Behavioral Testing of Clinical NLP Models
Behavioral Testing of Clinical NLP Models This repository contains code for testing the behavior of clinical prediction models based on patient letter
 2 Sep 20, 2022
2 Sep 20, 2022
Dataset and codebase for NeurIPS 2021 paper: Exploring Forensic Dental Identification with Deep Learning
Repository under construction. Example dataset, checkpoints, and training/testing scripts will be avaible soon! 💡 Collated best practices from most p
 4 Jun 26, 2022
4 Jun 26, 2022
Info and sample codes for "NTU RGB+D Action Recognition Dataset"
"NTU RGB+D" Action Recognition Dataset "NTU RGB+D 120" Action Recognition Dataset "NTU RGB+D" is a large-scale dataset for human action recognition. I
 578 Dec 30, 2022
578 Dec 30, 2022

DALLE-tools provided useful dataset utilities to improve you workflow with WebDatasets.
DALLE tools DALLE-tools is a github repository with useful tools to categorize, annotate or check the sanity of your datasets. Installation Just clone
 11 Dec 25, 2022
11 Dec 25, 2022
Various Algorithms for Short Text Mining
Short Text Mining in Python Introduction This package shorttext is a Python package that facilitates supervised and unsupervised learning for short te
 466 Dec 6, 2022
466 Dec 6, 2022
CCPD: a diverse and well-annotated dataset for license plate detection and recognition
CCPD (Chinese City Parking Dataset, ECCV) UPdate on 10/03/2019. CCPD Dataset is now updated. We are confident that images in subsets of CCPD is much m
 1.8k Dec 30, 2022
1.8k Dec 30, 2022

Tightness-aware Evaluation Protocol for Scene Text Detection
TIoU-metric Release on 27/03/2019. This repository is built on the ICDAR 2015 evaluation code. If you propose a better metric and require further eval
 206 Nov 18, 2022
206 Nov 18, 2022
Cluttered MNIST Dataset
Cluttered MNIST Dataset A setup script will download MNIST and produce mnist/*.t7 files: luajit download_mnist.lua Example usage: local mnist_clutter
 50 Jul 12, 2022
50 Jul 12, 2022
A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset
xwrf A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset. The primary objective of
 43 Nov 29, 2022
43 Nov 29, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022
Long Expressive Memory (LEM)
Long Expressive Memory for Sequence Modeling This repository contains the implementation to reproduce the numerical experiments of the paper Long Expr
 47 Dec 17, 2022
47 Dec 17, 2022

Project to deploy a machine learning model based on Titanic dataset from Kaggle
kaggle_titanic_deploy Project to deploy a machine learning model based on Titanic dataset from Kaggle In this project we used the Titanic dataset from
 8 May 23, 2022
8 May 23, 2022
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset This repository contains links to data and code to fetch and reproduce
 19 Dec 16, 2022
19 Dec 16, 2022

Official implementation of VQ-Diffusion: Vector Quantized Diffusion Model for Text-to-Image Synthesis
Official implementation of VQ-Diffusion: Vector Quantized Diffusion Model for Text-to-Image Synthesis
66 Dec 1, 2021

Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic [Paper] [Colab is coming soon] Approach Example Usage To r
 6 Dec 1, 2021
6 Dec 1, 2021
A leetcode scraper to compile all questions in leetcode free tier to text file. pdf also available.
A leetcode scraper to compile all questions in leetcode free tier to text file, pdf also available. if new questions get added, run again to get new questions.
 3 Dec 7, 2021
3 Dec 7, 2021
COIN the currently largest dataset for comprehensive instruction video analysis.
COIN Dataset COIN is the currently largest dataset for comprehensive instruction video analysis. It contains 11,827 videos of 180 different tasks (i.e
 86 Dec 28, 2022
86 Dec 28, 2022
Dataset and Source code of paper 'Enhancing Keyphrase Extraction from Academic Articles with their Reference Information'.
Enhancing Keyphrase Extraction from Academic Articles with their Reference Information Overview Dataset and code for paper "Enhancing Keyphrase Extrac
 15 Nov 24, 2022
15 Nov 24, 2022

A benchmark dataset for emulating atmospheric radiative transfer in weather and climate models with machine learning (NeurIPS 2021 Datasets and Benchmarks Track)
ClimART - A Benchmark Dataset for Emulating Atmospheric Radiative Transfer in Weather and Climate Models Official PyTorch Implementation Using deep le
 21 Dec 31, 2022
21 Dec 31, 2022
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic [Paper] [Colab is coming soon] Approach Example Usage To r
170 Jan 3, 2023

Official implementation for: Blended Diffusion for Text-driven Editing of Natural Images.
Blended Diffusion for Text-driven Editing of Natural Images Blended Diffusion for Text-driven Editing of Natural Images Omri Avrahami, Dani Lischinski
 328 Dec 30, 2022
328 Dec 30, 2022
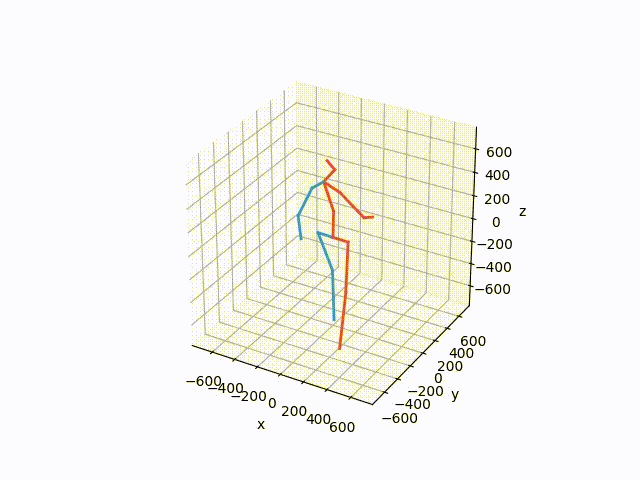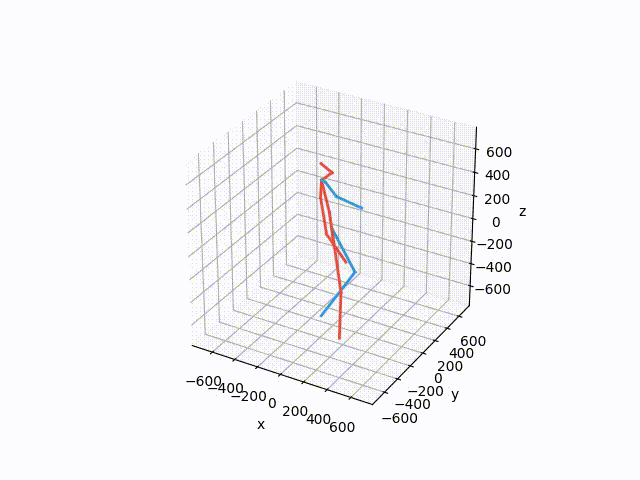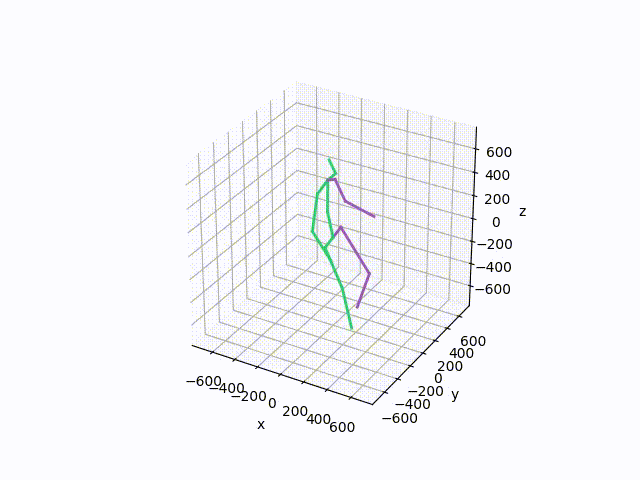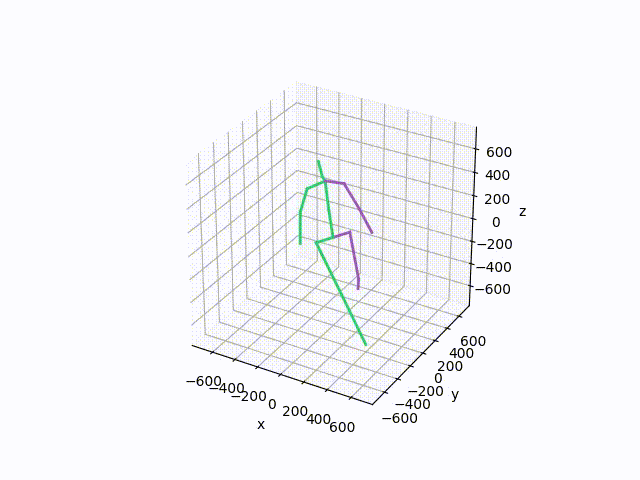
Plot and save the ground truth and predicted results of human 3.6 M and CMU mocap dataset.
Visualization-of-Human3.6M-Dataset Plot and save the ground truth and predicted results of human 3.6 M and CMU mocap dataset. human-motion-prediction
 5 Nov 18, 2022
5 Nov 18, 2022
A benchmark dataset for mesh multi-label-classification based on cube engravings introduced in MeshCNN
Double Cube Engravings This script creates a dataset for multi-label mesh clasification, with an intentionally difficult setup for point cloud classif
 1 Nov 30, 2021
1 Nov 30, 2021
A fast, dataset-agnostic, deep visual search engine for digital art history
imgs.ai imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings. It utilizes modern
 5 Dec 14, 2022
5 Dec 14, 2022
Predicting diabetes over a five year period using logistic regression and the Pima First-Nation dataset
Diabetes This script uses the Pima First Nations dataset to create a model to predict whether or not an individual will develop Diabetes Mellitus Type
 1 Mar 28, 2022
1 Mar 28, 2022
Train an imgs.ai model on your own dataset
imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings.
5 Dec 21, 2021

Code for generating synthetic text images as described in "Synthetic Data for Text Localisation in Natural Images", Ankush Gupta, Andrea Vedaldi, Andrew Zisserman, CVPR 2016.
SynthText Code for generating synthetic text images as described in "Synthetic Data for Text Localisation in Natural Images", Ankush Gupta, Andrea Ved
 1.8k Dec 28, 2022
1.8k Dec 28, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

This repository contains the source code of our work on designing efficient CNNs for computer vision
Efficient networks for Computer Vision This repo contains source code of our work on designing efficient networks for different computer vision tasks:
 386 Nov 26, 2022
386 Nov 26, 2022
WSDM‘2022: Knowledge Enhanced Sports Game Summarization
Knowledge Enhanced Sports Game Summarization Cooming Soon! :) Data will be released after approval process. Code will be published once the author of
 14 Jul 13, 2022
14 Jul 13, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
An open-source Kazakh named entity recognition dataset (KazNERD), annotation guidelines, and baseline NER models.
Kazakh Named Entity Recognition This repository contains an open-source Kazakh named entity recognition dataset (KazNERD), named entity annotation gui
 9 Dec 23, 2022
9 Dec 23, 2022
PyTorch implementation of CDistNet: Perceiving Multi-Domain Character Distance for Robust Text Recognition
PyTorch implementation of CDistNet: Perceiving Multi-Domain Character Distance for Robust Text Recognition The unofficial code of CDistNet. Now, we ha
 25 Jul 20, 2022
25 Jul 20, 2022
Text-Based zombie apocalyptic decision-making game in Python
Inspiration We shared university first year game coursework.[to gauge previous experience and start brainstorming] Adapted a particular nuclear fallou
 2 Feb 17, 2022
2 Feb 17, 2022
Combine Tacotron2 and Hifi GAN to generate speech from text
EndToEndTextToSpeech Combine Tacotron2 and Hifi GAN to generate speech from text Download weights Hifi GAN - hifi_gan/checkpoint/ : pretrain 2.5M ste
 1 Dec 18, 2021
1 Dec 18, 2021

A unofficial pytorch implementation of PAN(PSENet2): Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network
Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network Requirements pytorch 1.1+ torchvision 0.3+ pyclipper opencv3 gcc
 400 Dec 26, 2022
400 Dec 26, 2022