2512 Repositories
Python video-to-image-sequence Libraries
![[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation](https://user-images.githubusercontent.com/65257938/145016835-3c4be820-c55d-4eb4-b7f5-b8a012ee0f8c.png)
[AAAI22] Reliable Propagation-Correction Modulation for Video Object Segmentation
Reliable Propagation-Correction Modulation for Video Object Segmentation (AAAI22) Preview version paper of this work is available at: https://arxiv.or
 70 Dec 4, 2022
70 Dec 4, 2022

A simple library that implements CLIP guided loss in PyTorch.
pytorch_clip_guided_loss: Pytorch implementation of the CLIP guided loss for Text-To-Image, Image-To-Image, or Image-To-Text generation. A simple libr
 74 Dec 26, 2022
74 Dec 26, 2022

The code for 'Deep Residual Fourier Transformation for Single Image Deblurring'
Deep Residual Fourier Transformation for Single Image Deblurring Xintian Mao, Yiming Liu, Wei Shen, Qingli Li and Yan Wang News 2021.12.5 Release Deep
 145 Jan 5, 2023
145 Jan 5, 2023
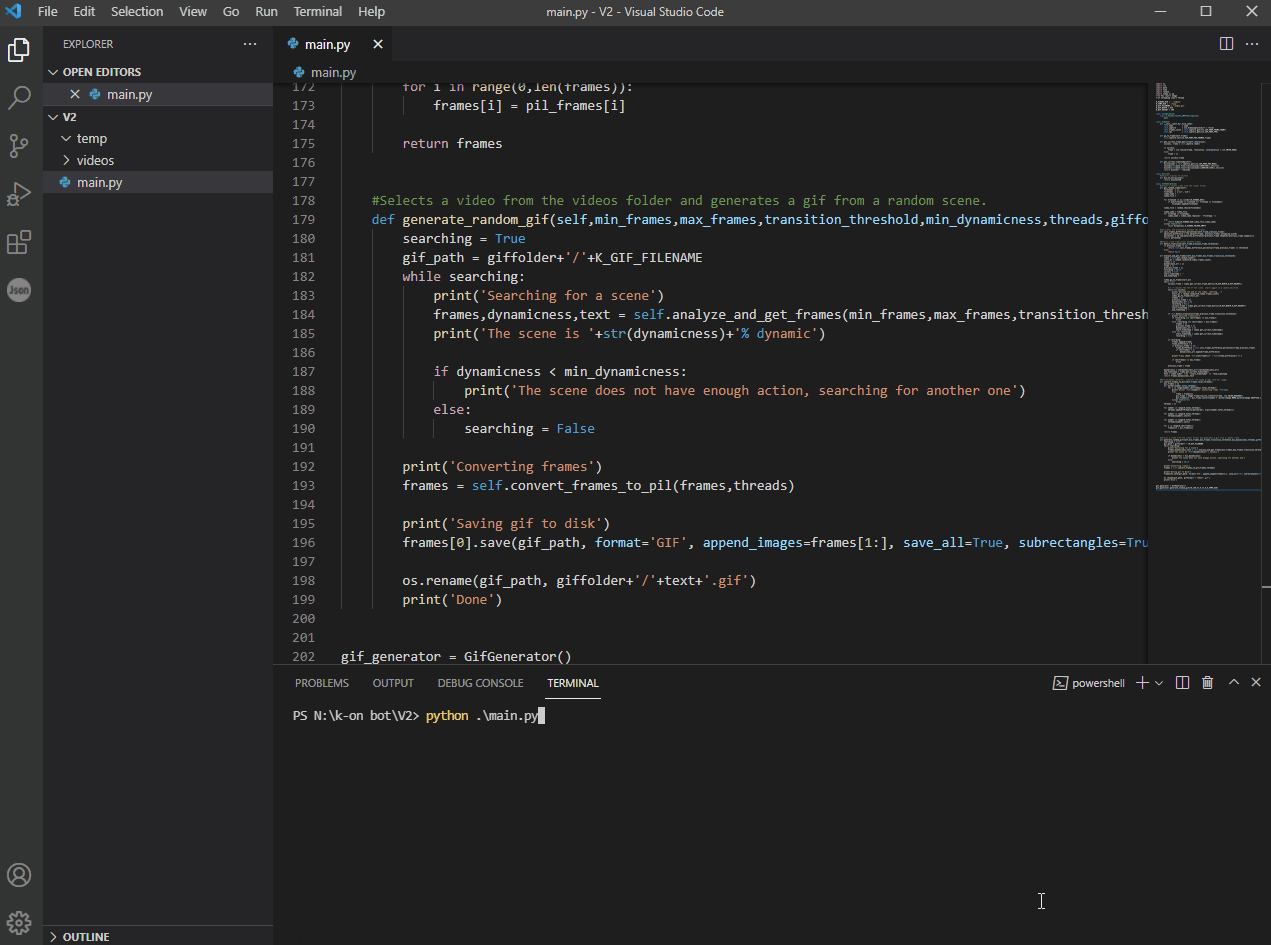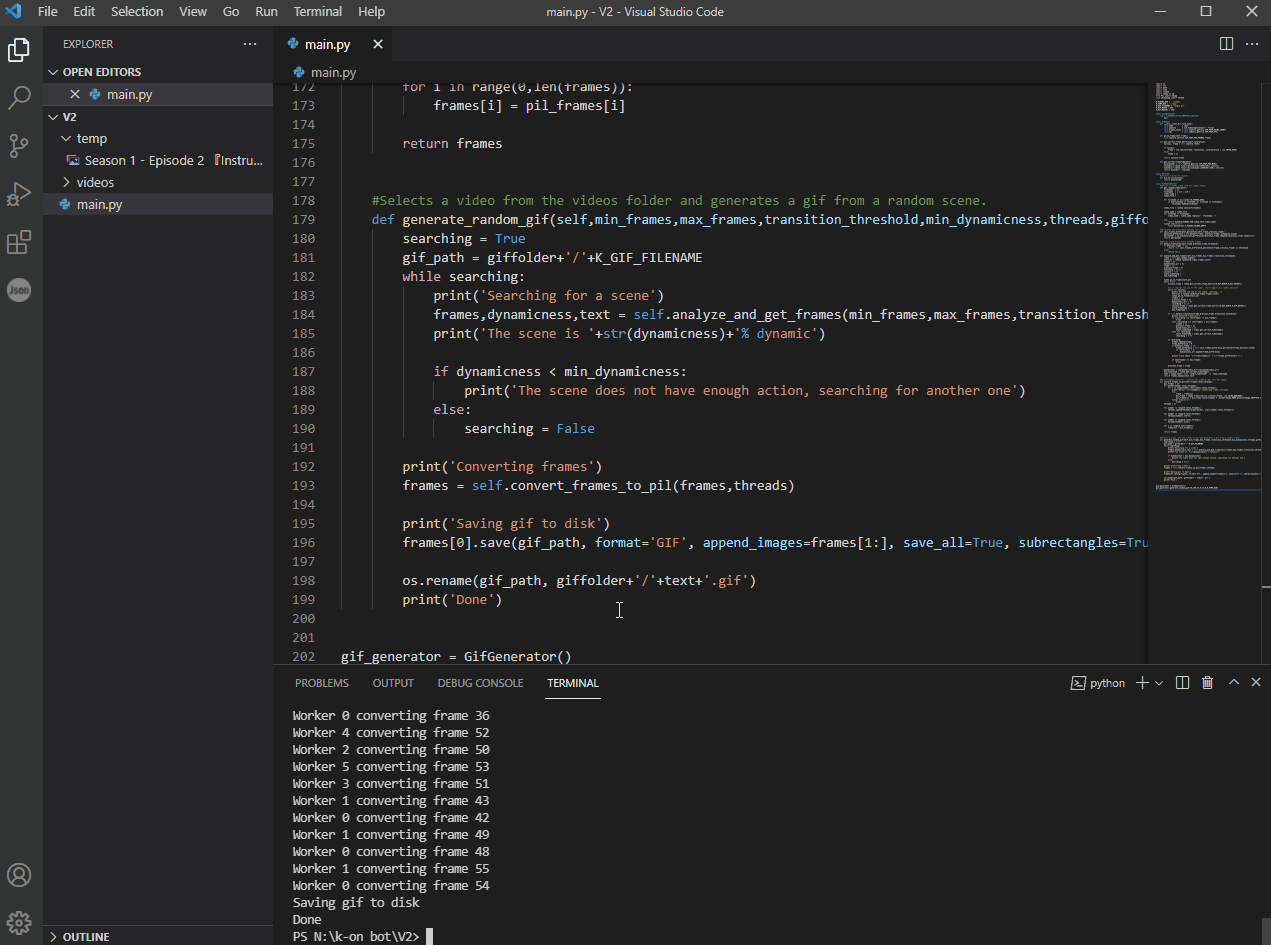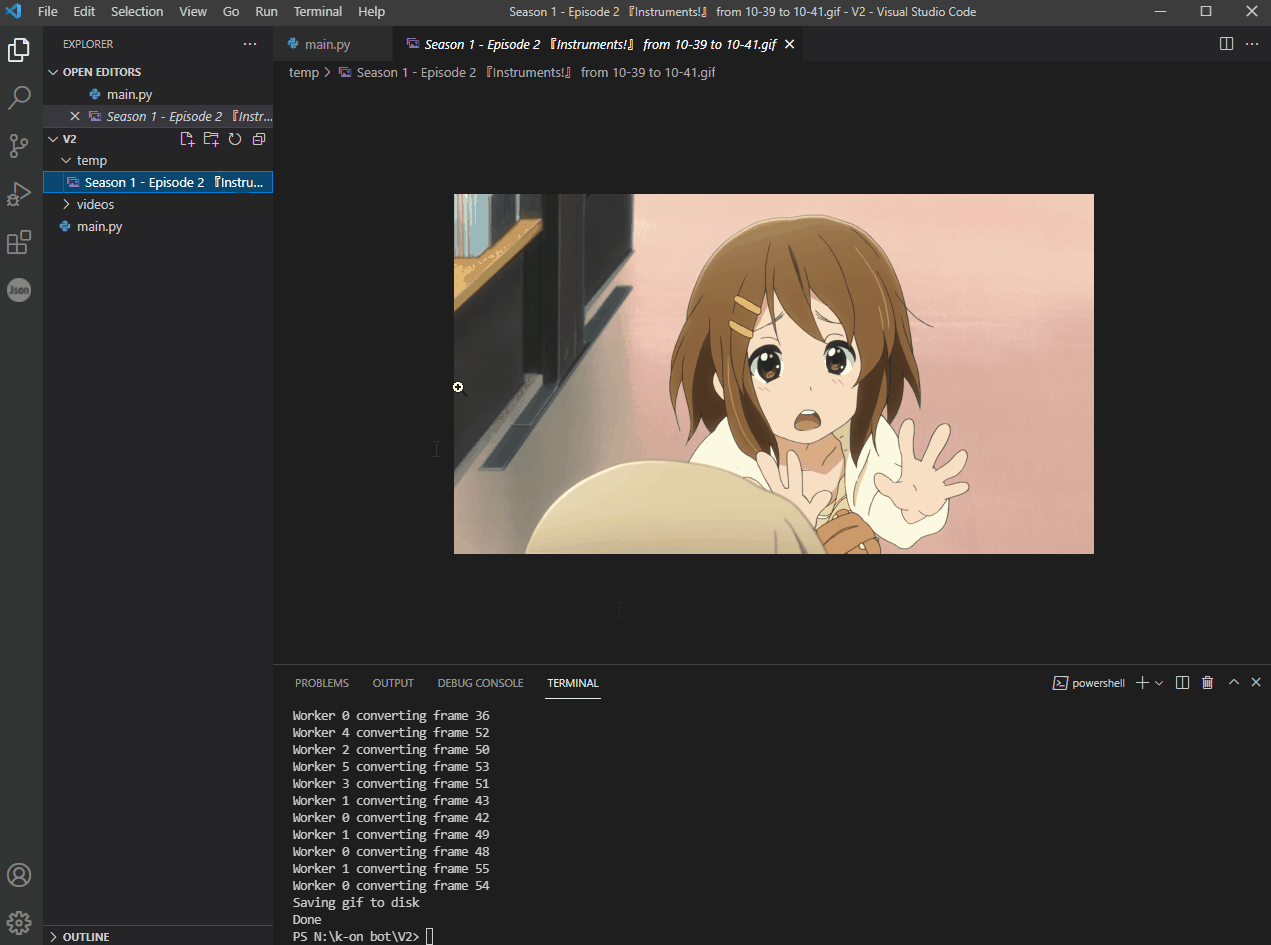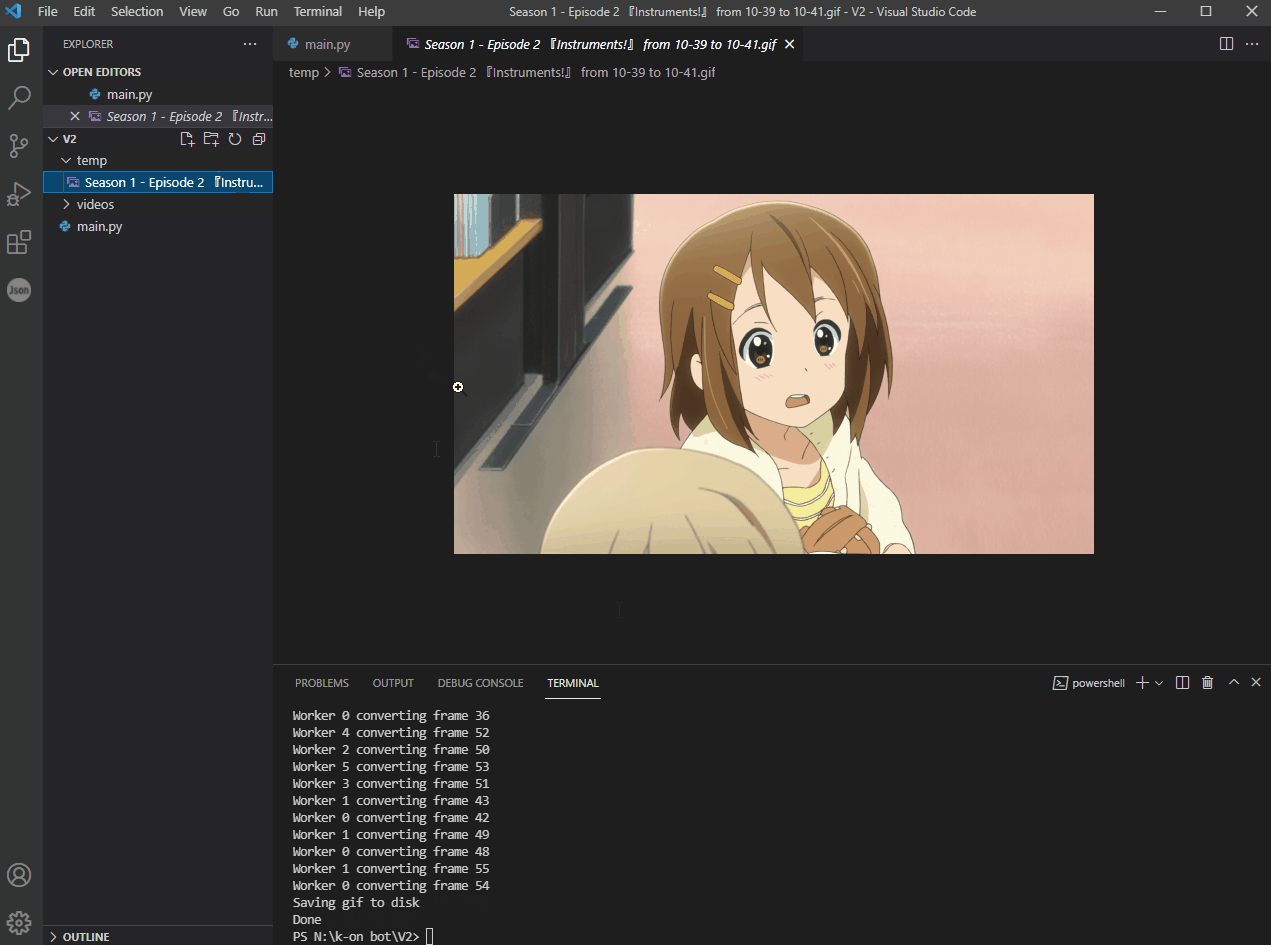
Anime2Gif - an algorithm that detects scenes in a video and generates gifs from it
Anime2Gif Anime2Gif is an algorithm that detects scenes in a video and generates gifs from it. How to use To use it, first, you'll need to install it'
 1 Dec 9, 2021
1 Dec 9, 2021

Simple cross-platform application for DaVinci surgical video frame annotation
About DaVid is a simple cross-platform GUI for annotating robotic and endoscopic surgical actions for use in deep-learning research. Features Simple a
 4 Oct 9, 2021
4 Oct 9, 2021

FuseDream: Training-Free Text-to-Image Generationwith Improved CLIP+GAN Space OptimizationFuseDream: Training-Free Text-to-Image Generationwith Improved CLIP+GAN Space Optimization
FuseDream This repo contains code for our paper (paper link): FuseDream: Training-Free Text-to-Image Generation with Improved CLIP+GAN Space Optimizat
 191 Dec 31, 2022
191 Dec 31, 2022
Telegram bot for stream music or video on telegram
Anonymous VC Bot + Stream Bot Telegram bot for stream music or video on telegram, powered by PyTgCalls and Pyrogram Features Playlist features Multi L
 111 Oct 4, 2022
111 Oct 4, 2022

Object Detection with YOLOv3
Object Detection with YOLOv3 Bu projede YOLOv3-608 modeli kullanılmıştır. Requirements Python 3.8 OpenCV Numpy Documentation Yolo ile ilgili detaylı b
 0 Mar 27, 2022
0 Mar 27, 2022
Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat
WAR MUSIC / VIDEO PLAYER Bot Bot Link: 🧪 Get SESSION_NAME from below: Pyrogram 🎭 Preview ✨ Features Music & Video stream support MultiChat support P
 11 Dec 25, 2022
11 Dec 25, 2022
Takes a video as an input and creates a video which is suitable to upload on Youtube Shorts and Tik Tok (1080x1920 resolution).
Shorts-Tik-Tok-Creator Takes a video as an input and creates a video which is suitable to upload on Youtube Shorts and Tik Tok (1080x1920 resolution).
 5 Nov 9, 2022
5 Nov 9, 2022
Latest Open Source Code for Playing Music in Telegram Video Chat. Made with Pyrogram and Pytgcalls 💖
MusicPlayer_TG Latest Open Source Code for Playing Music in Telegram Video Chat. Made with Pyrogram and Pytgcalls 💖 Requirements 📝 FFmpeg NodeJS nod
 2 Feb 4, 2022
2 Feb 4, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 0 Mar 20, 2022
0 Mar 20, 2022

Code for the TPAMI paper: "Syntax Customized Video Captioning by Imitating Exemplar Sentences"
Syntax-Customized-Video-Captioning Code for the TPAMI paper: "Syntax Customized Video Captioning by Imitating Exemplar Sentences". This is my second w
 3 Dec 5, 2022
3 Dec 5, 2022

Code for the paper "Controllable Video Captioning with an Exemplar Sentence"
SMCG Code for the paper "Controllable Video Captioning with an Exemplar Sentence" Introduction We investigate a novel and challenging task, namely con
10 Dec 4, 2022

PyTorch implementation of MICCAI 2018 paper "Liver Lesion Detection from Weakly-labeled Multi-phase CT Volumes with a Grouped Single Shot MultiBox Detector"
Grouped SSD (GSSD) for liver lesion detection from multi-phase CT Note: the MICCAI 2018 paper only covers the multi-phase lesion detection part of thi
 36 Oct 12, 2022
36 Oct 12, 2022
Official PyTorch implementation of our AAAI22 paper: TransMEF: A Transformer-Based Multi-Exposure Image Fusion Framework via Self-Supervised Multi-Task Learning. Code will be available soon.
Official-PyTorch-Implementation-of-TransMEF Official PyTorch implementation of our AAAI22 paper: TransMEF: A Transformer-Based Multi-Exposure Image Fu
 117 Dec 27, 2022
117 Dec 27, 2022

Official implementation for “Unsupervised Low-Light Image Enhancement via Histogram Equalization Prior”
Unsupervised Low-Light Image Enhancement via Histogram Equalization Prior. The code will release soon. Implementation Python3 PyTorch=1.0 NVIDIA GPU+
 34 Dec 4, 2022
34 Dec 4, 2022

Lama-cleaner: Image inpainting tool powered by LaMa
Lama-cleaner: Image inpainting tool powered by LaMa
 5.8k Jan 5, 2023
5.8k Jan 5, 2023
Userscript qutebrowser for downloading audio / video from youtube using aria2
Yt-Downloader Userscript qutebrowser for downloading video / audio from youtube using aria2 by hint links. Requirements Rofi youtube-dl aria2 dunst In
 0 Dec 11, 2021
0 Dec 11, 2021
Streams video from raspberry pi to desktop T1 - Recognizes Faces on client T2
VideoStreamingServer Completed: Streams video from raspberry pi to desktop T1 - Recognizes Faces on client T2 In progress: Change the transmission Pro
 1 Dec 6, 2021
1 Dec 6, 2021
Royal Music You can play music and video at a time in vc
Royals-Music Royal Music You can play music and video at a time in vc Commands SOON String STRING_SESSION Deployment 🎖 Credits • 🇸ᴏᴍʏᴀ⃝🇯ᴇᴇᴛ • 🇴ғғɪ
 2 Nov 23, 2021
2 Nov 23, 2021

Stenography encryption script
ImageCrypt Project description Installation Usage Project description Project AlexGyver on Python by TheK4n Design by Пашушка Byte packing in decimal
 5 Dec 14, 2022
5 Dec 14, 2022
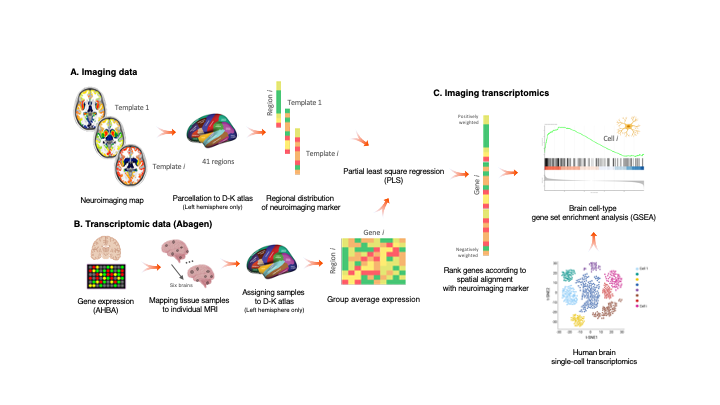
A package, and script, to perform imaging transcriptomics on a neuroimaging scan.
Imaging Transcriptomics Imaging transcriptomics is a methodology that allows to identify patterns of correlation between gene expression and some prop
 10 Dec 27, 2022
10 Dec 27, 2022

Self-Supervised Generative Style Transfer for One-Shot Medical Image Segmentation
Self-Supervised Generative Style Transfer for One-Shot Medical Image Segmentation This repository contains the Pytorch implementation of the proposed
 19 Nov 10, 2022
19 Nov 10, 2022
Blender addon - convert empty image reference to image plane
Reference to image plane Convert reference images to a textured image mesh plane. As if it was imported with import image as plane Use on drag'n'dropp
 6 Nov 25, 2022
6 Nov 25, 2022
Telegram Video Stream
Video Stream An Advanced VC Video Player created for playing video in the voice chats of Telegram Groups And Channel Configs TOKEN - Get bot token fro
 46 Dec 25, 2022
46 Dec 25, 2022

Implementation of NÜWA, state of the art attention network for text to video synthesis, in Pytorch
NÜWA - Pytorch (wip) Implementation of NÜWA, state of the art attention network for text to video synthesis, in Pytorch. This repository will be popul
 463 Dec 28, 2022
463 Dec 28, 2022

Video Stream is an Advanced Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat
Video Stream is an Advanced Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat 📊 Stats 🧪 Get SESSION_NAME from below:
 12 May 8, 2022
12 May 8, 2022

Simple, high-school-leveled sequence library written in Python / 간단한 고등학교 수준 수열 라이브러리 (Python)
Simple, high-school-leveled sequence library written in Python
 1 Dec 8, 2021
1 Dec 8, 2021
Code for paper "Adversarial score matching and improved sampling for image generation"
Adversarial score matching and improved sampling for image generation This repo contains the official implementation for the ICLR 2021 paper Adversari
 114 Dec 11, 2022
114 Dec 11, 2022

MoViNets PyTorch implementation: Mobile Video Networks for Efficient Video Recognition;
MoViNet-pytorch Pytorch unofficial implementation of MoViNets: Mobile Video Networks for Efficient Video Recognition. Authors: Dan Kondratyuk, Liangzh
 189 Dec 20, 2022
189 Dec 20, 2022

Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition"
CLIPstyler Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition" Environment Pytorch 1.7.1, Python 3.6 $ c
 201 Dec 29, 2022
201 Dec 29, 2022
4D Human Body Capture from Egocentric Video via 3D Scene Grounding
4D Human Body Capture from Egocentric Video via 3D Scene Grounding [Project] [Paper] Installation: Our method requires the same dependencies as SMPLif
 37 Nov 8, 2022
37 Nov 8, 2022

A Python script that creates subtitles of a given length from text paragraphs that can be easily imported into any Video Editing software such as FinalCut Pro for further adjustments.
Text to Subtitles - Python This python file creates subtitles of a given length from text paragraphs that can be easily imported into any Video Editin
 9 Dec 24, 2022
9 Dec 24, 2022

Tensorflow implementation of Semi-supervised Sequence Learning (https://arxiv.org/abs/1511.01432)
Transfer Learning for Text Classification with Tensorflow Tensorflow implementation of Semi-supervised Sequence Learning(https://arxiv.org/abs/1511.01
 82 Oct 22, 2022
82 Oct 22, 2022
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022
Vision-Language Pre-training for Image Captioning and Question Answering
VLP This repo hosts the source code for our AAAI2020 work Vision-Language Pre-training (VLP). We have released the pre-trained model on Conceptual Cap
 373 Jan 3, 2023
373 Jan 3, 2023
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
UNITER: UNiversal Image-TExt Representation Learning This is the official repository of UNITER (ECCV 2020). This repository currently supports finetun
 680 Dec 24, 2022
680 Dec 24, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
 938 Dec 26, 2022
938 Dec 26, 2022

Contrastive Language-Image Pretraining
CLIP [Blog] [Paper] [Model Card] [Colab] CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pair
 11.5k Jan 8, 2023
11.5k Jan 8, 2023
![[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations](https://github.com/kdexd/virtex/raw/master/docs/_static/system_figure.jpg)
[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations
VirTex: Learning Visual Representations from Textual Annotations Karan Desai and Justin Johnson University of Michigan CVPR 2021 arxiv.org/abs/2006.06
 533 Dec 24, 2022
533 Dec 24, 2022
Video Frame Interpolation without Temporal Priors (a general method for blurry video interpolation)
Video Frame Interpolation without Temporal Priors (NeurIPS2020) [Paper] [video] How to run Prerequisites NVIDIA GPU + CUDA 9.0 + CuDNN 7.6.5 Pytorch 1
 31 Sep 4, 2022
31 Sep 4, 2022
Code release for "Masked-attention Mask Transformer for Universal Image Segmentation"
Mask2Former: Masked-attention Mask Transformer for Universal Image Segmentation Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Ro
 1.2k Jan 2, 2023
1.2k Jan 2, 2023
Code for the paper "Controllable Video Captioning with an Exemplar Sentence"
SMCG Code for the paper "Controllable Video Captioning with an Exemplar Sentence" Introduction We investigate a novel and challenging task, namely con
10 Dec 4, 2022
A PyTorch Implementation of PGL-SUM from "Combining Global and Local Attention with Positional Encoding for Video Summarization", Proc. IEEE ISM 2021
PGL-SUM: Combining Global and Local Attention with Positional Encoding for Video Summarization PyTorch Implementation of PGL-SUM From "PGL-SUM: Combin
 35 Dec 22, 2022
35 Dec 22, 2022
Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation
Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation Woncheol Shin1, Gyubok Lee1, Jiyoung Lee1, Joonseok Lee2,3, Edward Ch
 7 Sep 26, 2022
7 Sep 26, 2022
[NeurIPS'21 Spotlight] PyTorch code for our paper "Aligned Structured Sparsity Learning for Efficient Image Super-Resolution"
ASSL This repository is for a new network pruning method (Aligned Structured Sparsity Learning, ASSL) for efficient single image super-resolution (SR)
 47 Nov 28, 2022
47 Nov 28, 2022

MonoScene: Monocular 3D Semantic Scene Completion
MonoScene: Monocular 3D Semantic Scene Completion MonoScene: Monocular 3D Semantic Scene Completion] [arXiv + supp] | [Project page] Anh-Quan Cao, Rao
 298 Jan 8, 2023
298 Jan 8, 2023
Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition"
CLIPstyler Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition" Environment Pytorch 1.7.1, Python 3.6 $ c
203 Dec 30, 2022

Code of Adverse Weather Image Translation with Asymmetric and Uncertainty aware GAN
Adverse Weather Image Translation with Asymmetric and Uncertainty-aware GAN (AU-GAN) Official Tensorflow implementation of Adverse Weather Image Trans
 36 Dec 26, 2022
36 Dec 26, 2022
PyTorch trainer and model for Sequence Classification
PyTorch-trainer-and-model-for-Sequence-Classification After cloning the repository, modify your training data so that the training data is a .csv file
 2 Dec 9, 2022
2 Dec 9, 2022
A Telegram Video Watermark Adder Bot
Watermark-Bot A Telegram Video Watermark Adder Bot by @VideosWaterMarkRobot Features: Save Custom Watermark Image. Auto Resize Watermark According to
 5 Jun 17, 2022
5 Jun 17, 2022
Code & Models for Temporal Segment Networks (TSN) in ECCV 2016
Temporal Segment Networks (TSN) We have released MMAction, a full-fledged action understanding toolbox based on PyTorch. It includes implementation fo
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
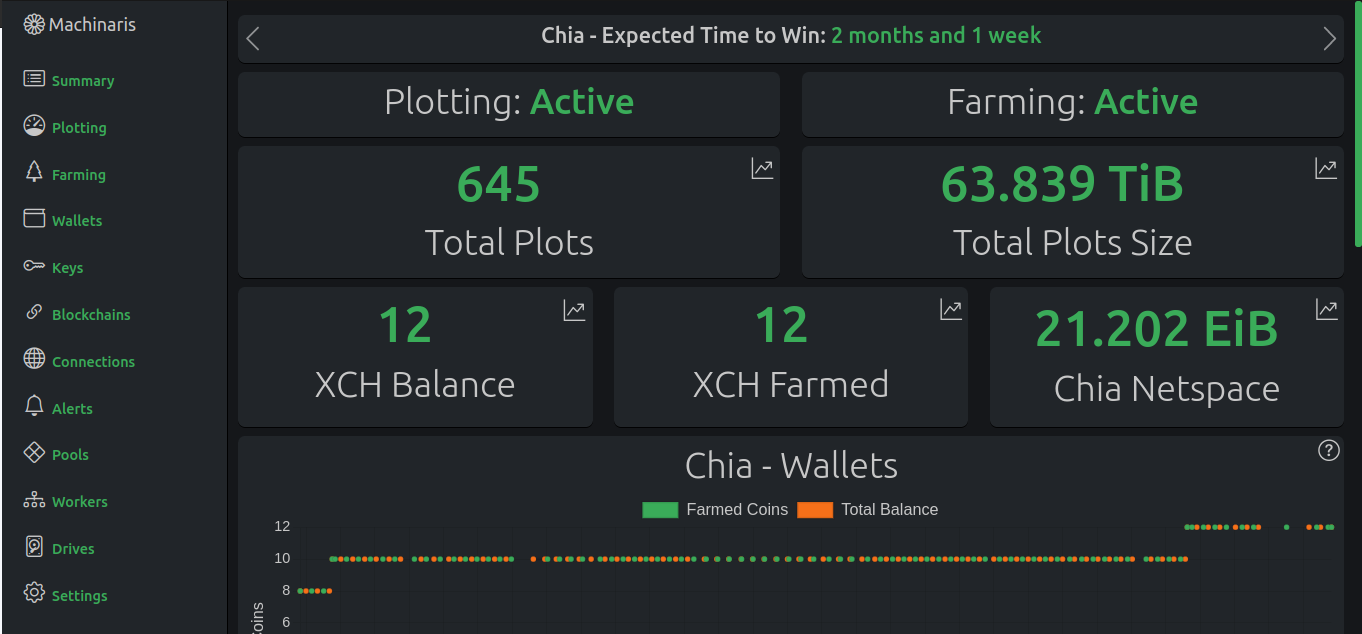
A Docker image for plotting and farming the Chia™ cryptocurrency on one computer or across many.
An easy-to-use WebUI for crypto plotting and farming. Offers Plotman, MadMax, Chiadog, Bladebit, Farmr, and Forktools in a Docker container. Supports Chia, Cactus, Chives, Flax, Flora, HDDCoin, Maize, N-Chain, Staicoin, and Stor among others.
 328 Jan 1, 2023
328 Jan 1, 2023

Training and evaluation codes for the BertGen paper (ACL-IJCNLP 2021)
BERTGEN This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codeb
 9 Oct 26, 2022
9 Oct 26, 2022
Media Replay Engine (MRE) is a framework to build automated video clipping and replay (highlight) generation pipelines for live and video-on-demand content.
Media Replay Engine (MRE) is a framework for building automated video clipping and replay (highlight) generation pipelines using AWS services for live
 30 Nov 29, 2022
30 Nov 29, 2022

clustimage is a python package for unsupervised clustering of images.
clustimage The aim of clustimage is to detect natural groups or clusters of images. Image recognition is a computer vision task for identifying and ve
 52 Jan 2, 2023
52 Jan 2, 2023

DeepFill v1/v2 with Contextual Attention and Gated Convolution, CVPR 2018, and ICCV 2019 Oral
Generative Image Inpainting An open source framework for generative image inpainting task, with the support of Contextual Attention (CVPR 2018) and Ga
 2.9k Dec 16, 2022
2.9k Dec 16, 2022

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023

A simple image-level annotation tool supporting multi-channel images for napari.
napari-labelimg4classification A simple image-level annotation tool supporting multi-channel images for napari. This napari plugin was generated with
 4 May 16, 2022
4 May 16, 2022

Making Structure-from-Motion (COLMAP) more robust to symmetries and duplicated structures
SfM disambiguation with COLMAP About Structure-from-Motion generally fails when the scene exhibits symmetries and duplicated structures. In this repos
 193 Dec 26, 2022
193 Dec 26, 2022
This is used to convert a string to an Image with Handwritten Characters.
Text-to-Handwriting-using-python This is used to convert a string to an Image with Handwritten Characters. text_to_handwriting(string: str, save_to: s
 3 Aug 15, 2022
3 Aug 15, 2022

A Pythonic framework for threat modeling
pytm: A Pythonic framework for threat modeling Introduction Traditional threat modeling too often comes late to the party, or sometimes not at all. In
 644 Dec 20, 2022
644 Dec 20, 2022

Fast and robust clustering of point clouds generated with a Velodyne sensor.
Depth Clustering This is a fast and robust algorithm to segment point clouds taken with Velodyne sensor into objects. It works with all available Velo
 957 Dec 21, 2022
957 Dec 21, 2022

Train the HRNet model on ImageNet
High-resolution networks (HRNets) for Image classification News [2021/01/20] Add some stronger ImageNet pretrained models, e.g., the HRNet_W48_C_ssld_
 866 Jan 4, 2023
866 Jan 4, 2023

On Nonlinear Latent Transformations for GAN-based Image Editing - PyTorch implementation
On Nonlinear Latent Transformations for GAN-based Image Editing - PyTorch implementation On Nonlinear Latent Transformations for GAN-based Image Editi
 22 Oct 24, 2022
22 Oct 24, 2022
Self-Supervised Image Denoising via Iterative Data Refinement
Self-Supervised Image Denoising via Iterative Data Refinement Yi Zhang1, Dasong Li1, Ka Lung Law2, Xiaogang Wang1, Hongwei Qin2, Hongsheng Li1 1CUHK-S
 72 Jan 1, 2023
72 Jan 1, 2023
Revisiting Temporal Alignment for Video Restoration
Revisiting Temporal Alignment for Video Restoration [arXiv] Kun Zhou, Wenbo Li, Liying Lu, Xiaoguang Han, Jiangbo Lu We provide our results at Google
 52 Dec 25, 2022
52 Dec 25, 2022

EdiBERT, a generative model for image editing
EdiBERT, a generative model for image editing EdiBERT is a generative model based on a bi-directional transformer, suited for image manipulation. The
 16 Dec 7, 2022
16 Dec 7, 2022
Camera Distortion-aware 3D Human Pose Estimation in Video with Optimization-based Meta-Learning
Camera Distortion-aware 3D Human Pose Estimation in Video with Optimization-based Meta-Learning This is the official repository of "Camera Distortion-
 12 Oct 6, 2022
12 Oct 6, 2022

Official implementation for "Low-light Image Enhancement via Breaking Down the Darkness"
Low-light Image Enhancement via Breaking Down the Darkness by Qiming Hu, Xiaojie Guo. 1. Dependencies Python3 PyTorch=1.0 OpenCV-Python, TensorboardX
 3 Dec 1, 2021
3 Dec 1, 2021
Interpretable and Generalizable Person Re-Identification with Query-Adaptive Convolution and Temporal Lifting
QAConv Interpretable and Generalizable Person Re-Identification with Query-Adaptive Convolution and Temporal Lifting This PyTorch code is proposed in
 166 Dec 28, 2022
166 Dec 28, 2022
Official implementation of the NeurIPS'21 paper 'Conditional Generation Using Polynomial Expansions'.
Conditional Generation Using Polynomial Expansions Official implementation of the conditional image generation experiments as described on the NeurIPS
 4 Aug 7, 2022
4 Aug 7, 2022
Equivariant layers for RC-complement symmetry in DNA sequence data
Equi-RC Equivariant layers for RC-complement symmetry in DNA sequence data This is a repository that implements the layers as described in "Reverse-Co
 7 May 19, 2022
7 May 19, 2022

StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators [Project Website] [Replicate.ai Project] StyleGAN-NADA: CLIP-Guided Domain Adaptation
 992 Dec 30, 2022
992 Dec 30, 2022

Official Implementation of "Designing an Encoder for StyleGAN Image Manipulation"
Designing an Encoder for StyleGAN Image Manipulation (SIGGRAPH 2021) Recently, there has been a surge of diverse methods for performing image editing
 749 Jan 9, 2023
749 Jan 9, 2023

Official Implementation for Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation We present a generic image-to-image translation framework, pixel2style2pixel (pSp
 2.8k Dec 30, 2022
2.8k Dec 30, 2022

SketchEdit: Mask-Free Local Image Manipulation with Partial Sketches
SketchEdit: Mask-Free Local Image Manipulation with Partial Sketches [Paper] [Project Page] [Interactive Demo] [Supplementary Material] Usag
 215 Dec 25, 2022
215 Dec 25, 2022

Official Implementation for HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing
HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing Yuval Alaluf*, Omer Tov*, Ron Mokady, Rinon Gal, Amit H. Bermano *Denotes equ
 885 Jan 6, 2023
885 Jan 6, 2023

PySlowFast: video understanding codebase from FAIR for reproducing state-of-the-art video models.
PySlowFast PySlowFast is an open source video understanding codebase from FAIR that provides state-of-the-art video classification models with efficie
5.3k Jan 3, 2023
OpenL3: Open-source deep audio and image embeddings
OpenL3 OpenL3 is an open-source Python library for computing deep audio and image embeddings. Please refer to the documentation for detailed instructi
 326 Jan 2, 2023
326 Jan 2, 2023

Memory tests solver with using OpenCV
Human Benchmark project This project is OpenCV based programs which are puzzle solvers for 7 different games for https://humanbenchmark.com/. made as
 24 Dec 27, 2022
24 Dec 27, 2022

Official implementation of Pixel-Level Bijective Matching for Video Object Segmentation
BMVOS This is the official implementation of Pixel-Level Bijective Matching for Video Object Segmentation, to appear in WACV 2022. @article{cho2021pix
 13 Dec 14, 2022
13 Dec 14, 2022
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats
TG-MusicPlayer A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Py
 4 Dec 14, 2022
4 Dec 14, 2022
Official repository of "Investigating Tradeoffs in Real-World Video Super-Resolution"
RealBasicVSR [Paper] This is the official repository of "Investigating Tradeoffs in Real-World Video Super-Resolution, arXiv". This repository contain
 566 Dec 28, 2022
566 Dec 28, 2022

Real-time VIBE: Frame by Frame Inference of VIBE (Video Inference for Human Body Pose and Shape Estimation)
Real-time VIBE Inference VIBE frame-by-frame. Overview This is a frame-by-frame inference fork of VIBE at [https://github.com/mkocabas/VIBE]. Usage: i
 23 Jul 2, 2022
23 Jul 2, 2022

Official implementation of VQ-Diffusion: Vector Quantized Diffusion Model for Text-to-Image Synthesis
Official implementation of VQ-Diffusion: Vector Quantized Diffusion Model for Text-to-Image Synthesis
66 Dec 1, 2021

Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic [Paper] [Colab is coming soon] Approach Example Usage To r
 6 Dec 1, 2021
6 Dec 1, 2021
Swin-Transformer is basically a hierarchical Transformer whose representation is computed with shifted windows.
Swin-Transformer Swin-Transformer is basically a hierarchical Transformer whose representation is computed with shifted windows. For more details, ple
 9 Mar 14, 2022
9 Mar 14, 2022
Code from the 2021 Signal Video Superclass
Twilio Video Demo This is the code written during the live Twilio Video demo during Twilio's Signal 2021 Superclass. It creates a simple Video applica
 2 Oct 21, 2021
2 Oct 21, 2021
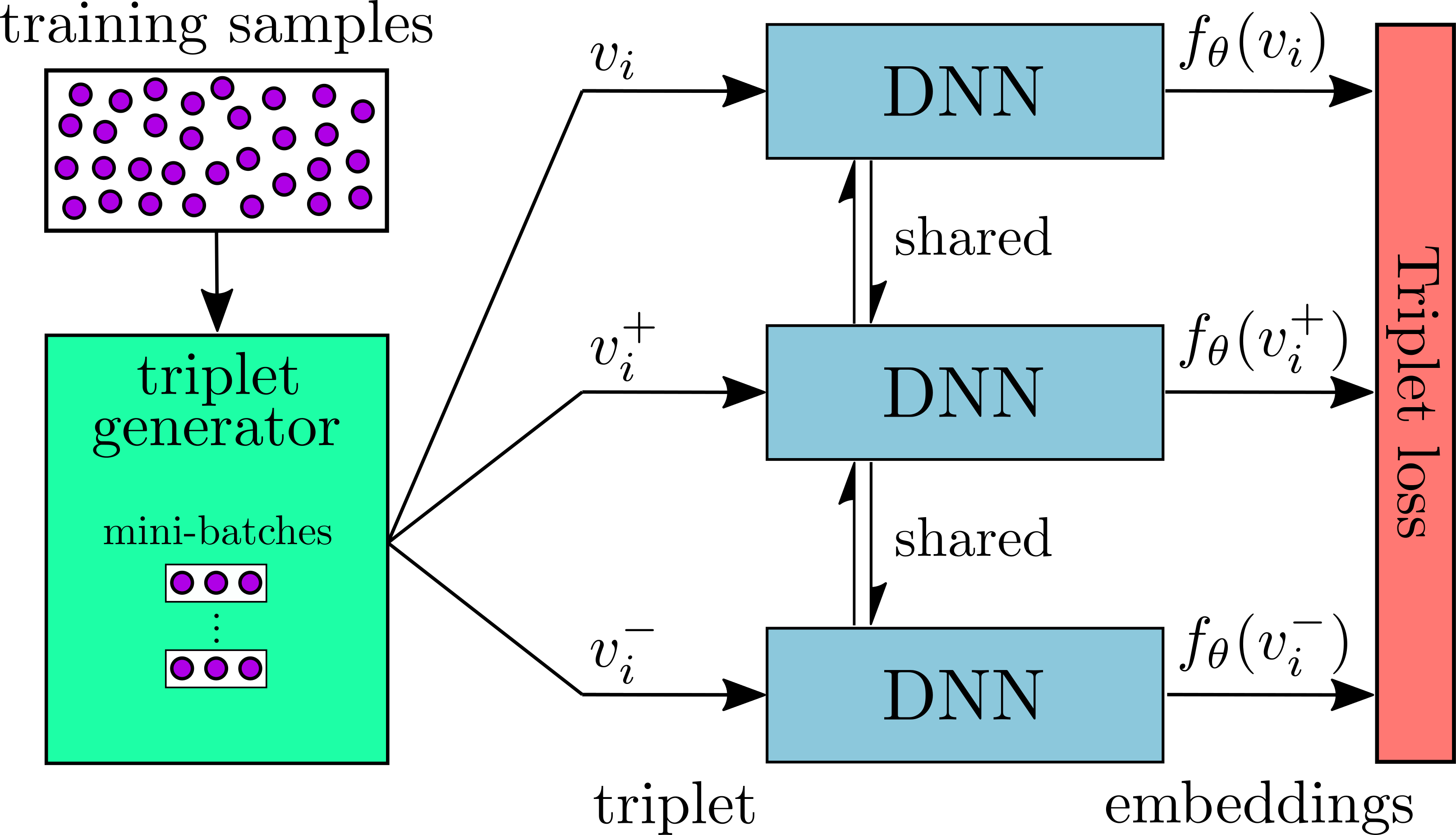
Near-Duplicate Video Retrieval with Deep Metric Learning
Near-Duplicate Video Retrieval with Deep Metric Learning This repository contains the Tensorflow implementation of the paper Near-Duplicate Video Retr
 2 Jan 24, 2022
2 Jan 24, 2022
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository provides the official PyTorch implementation
 155 Nov 30, 2021
155 Nov 30, 2021
This plugin generates json files used by deovr allowing you to play 2d and 3d video's using the player
deovr-plugin This plugin generates json files used by deovr allowing you to play 2d and 3d video's using the player. Deovr looks for an index file /de
 10 Sep 29, 2022
10 Sep 29, 2022
Official implementation for "Low-light Image Enhancement via Breaking Down the Darkness"
Low-light Image Enhancement via Breaking Down the Darkness by Qiming Hu, Xiaojie Guo. 1. Dependencies Python3 PyTorch=1.0 OpenCV-Python, TensorboardX
30 Jan 1, 2023

Official repository of the paper "GPR1200: A Benchmark for General-PurposeContent-Based Image Retrieval"
GPR1200 Dataset GPR1200: A Benchmark for General-Purpose Content-Based Image Retrieval (ArXiv) Konstantin Schall, Kai Uwe Barthel, Nico Hezel, Klaus J
 16 Nov 21, 2022
16 Nov 21, 2022
AdaDM: Enabling Normalization for Image Super-Resolution
AdaDM AdaDM: Enabling Normalization for Image Super-Resolution. You can apply BN, LN or GN in SR networks with our AdaDM. Pretrained models (EDSR*/RDN
 58 Jan 8, 2023
58 Jan 8, 2023
COIN the currently largest dataset for comprehensive instruction video analysis.
COIN Dataset COIN is the currently largest dataset for comprehensive instruction video analysis. It contains 11,827 videos of 180 different tasks (i.e
 86 Dec 28, 2022
86 Dec 28, 2022
Parallel Latent Tree-Induction for Faster Sequence Encoding
FastTrees This repository contains the experimental code supporting the FastTrees paper by Bill Pung. Software Requirements Python 3.6, NLTK and PyTor
 4 Mar 29, 2022
4 Mar 29, 2022

Official Pytorch Implementation of Unsupervised Image Denoising With Frequency Domain Knowledge (BMVC2021 Oral Accepted Paper)
Unsupervised Image Denoising with Frequency Domain Knowledge (BMVC 2021 Oral) : Official Project Page This repository provides the official PyTorch im
 3 Nov 25, 2021
3 Nov 25, 2021
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic [Paper] [Colab is coming soon] Approach Example Usage To r
170 Jan 3, 2023