823 Repositories
Python visual-semantic Libraries

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022
An official implementation of "Exploiting a Joint Embedding Space for Generalized Zero-Shot Semantic Segmentation" (ICCV 2021) in PyTorch.
Exploiting a Joint Embedding Space for Generalized Zero-Shot Semantic Segmentation This is an official implementation of the paper "Exploiting a Joint
 35 Oct 26, 2022
35 Oct 26, 2022
A management system designed for the employees of MIRAS (Art Gallery). It is used to sell/cancel tickets, book/cancel events and keeps track of all upcoming events.
Art-Galleria-Management-System Its a management system designed for the employees of MIRAS (Art Gallery). Backend : Python Frontend : Django Database
 8 Nov 30, 2022
8 Nov 30, 2022

A weakly-supervised scene graph generation codebase. The implementation of our CVPR2021 paper ``Linguistic Structures as Weak Supervision for Visual Scene Graph Generation''
README.md shall be finished soon. WSSGG 0 Overview 1 Installation 1.1 Faster-RCNN 1.2 Language Parser 1.3 GloVe Embeddings 2 Settings 2.1 VG-GT-Graph
 35 Nov 20, 2022
35 Nov 20, 2022
Pytorch Implementation for NeurIPS (oral) paper: Pixel Level Cycle Association: A New Perspective for Domain Adaptive Semantic Segmentation
Pixel-Level Cycle Association This is the Pytorch implementation of our NeurIPS 2020 Oral paper Pixel-Level Cycle Association: A New Perspective for D
 87 Oct 19, 2022
87 Oct 19, 2022

Dynamic Divide-and-Conquer Adversarial Training for Robust Semantic Segmentation (ICCV2021)
Dynamic Divide-and-Conquer Adversarial Training for Robust Semantic Segmentation This is a pytorch project for the paper Dynamic Divide-and-Conquer Ad
 29 Nov 21, 2022
29 Nov 21, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
 41 Jan 3, 2023
41 Jan 3, 2023

Pytorch implementation for Semantic Segmentation/Scene Parsing on MIT ADE20K dataset
Semantic Segmentation on MIT ADE20K dataset in PyTorch This is a PyTorch implementation of semantic segmentation models on MIT ADE20K scene parsing da
 4.5k Jan 8, 2023
4.5k Jan 8, 2023
"Segmenter: Transformer for Semantic Segmentation" reproduced via mmsegmentation
Segmenter-based-on-OpenMMLab "Segmenter: Transformer for Semantic Segmentation, arxiv 2105.05633." reproduced via mmsegmentation. We reproduce Segment
 22 Feb 24, 2022
22 Feb 24, 2022

IAST: Instance Adaptive Self-training for Unsupervised Domain Adaptation (ECCV 2020)
This repo is the official implementation of our paper "Instance Adaptive Self-training for Unsupervised Domain Adaptation". The purpose of this repo is to better communicate with you and respond to your questions. This repo is almost the same with Another-Version, and you can also refer to that version.
 84 Dec 12, 2022
84 Dec 12, 2022

Code release for The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification (TIP 2020)
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification Code release for The Devil is in the Channels: Mutual-Channel
 230 Dec 31, 2022
230 Dec 31, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023

Official code for "Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer. ICCV2021".
Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer. ICCV2021. Introduction We proposed a novel model training paradi
 103 Dec 14, 2022
103 Dec 14, 2022

PyTorch implementation of ShapeConv: Shape-aware Convolutional Layer for RGB-D Indoor Semantic Segmentation.
Shape-aware Convolutional Layer (ShapeConv) PyTorch implementation of ShapeConv: Shape-aware Convolutional Layer for RGB-D Indoor Semantic Segmentatio
 82 Dec 29, 2022
82 Dec 29, 2022

Official PyTorch implementation of Segmenter: Transformer for Semantic Segmentation
Segmenter: Transformer for Semantic Segmentation Segmenter: Transformer for Semantic Segmentation by Robin Strudel*, Ricardo Garcia*, Ivan Laptev and
 594 Jan 6, 2023
594 Jan 6, 2023
Video Visual Relation Detection (VidVRD) tracklets generation. also for ACM MM Visual Relation Understanding Grand Challenge
VidVRD-tracklets This repository contains codes for Video Visual Relation Detection (VidVRD) tracklets generation based on MEGA and deepSORT. These tr
 25 Dec 21, 2022
25 Dec 21, 2022

A Data Annotation Tool for Semantic Segmentation, Object Detection and Lane Line Detection.(In Development Stage)
Data-Annotation-Tool How to Run this Tool? To run this software, follow the steps: git clone https://github.com/Autonomous-Car-Project/Data-Annotation
 13 Aug 18, 2022
13 Aug 18, 2022

Official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers
Visual Parser (ViP) This is the official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers. Key Feature
 117 Dec 11, 2022
117 Dec 11, 2022
DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021)
DPT This repo is the official implementation of DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021). We provide code and model
 111 Dec 21, 2022
111 Dec 21, 2022
![[CVPR 2021] Forecasting the panoptic segmentation of future video frames](https://github.com/nianticlabs/panoptic-forecasting/raw/master/comparison.gif)
[CVPR 2021] Forecasting the panoptic segmentation of future video frames
Panoptic Segmentation Forecasting Colin Graber, Grace Tsai, Michael Firman, Gabriel Brostow, Alexander Schwing - CVPR 2021 [Link to paper] We propose
 44 Nov 29, 2022
44 Nov 29, 2022

Open-World Entity Segmentation
Open-World Entity Segmentation Project Website Lu Qi*, Jason Kuen*, Yi Wang, Jiuxiang Gu, Hengshuang Zhao, Zhe Lin, Philip Torr, Jiaya Jia This projec
410 Jan 3, 2023
This is the code for CVPR 2021 oral paper: Jigsaw Clustering for Unsupervised Visual Representation Learning
JigsawClustering Jigsaw Clustering for Unsupervised Visual Representation Learning Pengguang Chen, Shu Liu, Jiaya Jia Introduction This project provid
73 Sep 18, 2022

Dataset used in "PlantDoc: A Dataset for Visual Plant Disease Detection" accepted in CODS-COMAD 2020
PlantDoc: A Dataset for Visual Plant Disease Detection This repository contains the Cropped-PlantDoc dataset used for benchmarking classification mode
 109 Dec 29, 2022
109 Dec 29, 2022

Segmentation in Style: Unsupervised Semantic Image Segmentation with Stylegan and CLIP
Segmentation in Style: Unsupervised Semantic Image Segmentation with Stylegan and CLIP Abstract: We introduce a method that allows to automatically se
 134 Dec 19, 2022
134 Dec 19, 2022

Recall Loss for Semantic Segmentation (This repo implements the paper: Recall Loss for Semantic Segmentation)
Recall Loss for Semantic Segmentation (This repo implements the paper: Recall Loss for Semantic Segmentation) Download Synthia dataset The model uses
 32 Sep 21, 2022
32 Sep 21, 2022

Implementation of ICCV2021(Oral) paper - VMNet: Voxel-Mesh Network for Geodesic-aware 3D Semantic Segmentation
VMNet: Voxel-Mesh Network for Geodesic-Aware 3D Semantic Segmentation Created by Zeyu HU Introduction This work is based on our paper VMNet: Voxel-Mes
 82 Dec 27, 2022
82 Dec 27, 2022

The code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention.
CrossFormer This repository is the code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention. Introduction Existin
 238 Jan 6, 2023
238 Jan 6, 2023

This's an implementation of deepmind Visual Interaction Networks paper using pytorch
Visual-Interaction-Networks An implementation of Deepmind visual interaction networks in Pytorch. Introduction For the purpose of understanding the ch
 166 Dec 6, 2022
166 Dec 6, 2022

PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs
PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs This code aims to reproduce results obtained in the paper "Visual F
 93 Aug 17, 2022
93 Aug 17, 2022

Photographic Image Synthesis with Cascaded Refinement Networks - Pytorch Implementation
Photographic Image Synthesis with Cascaded Refinement Networks-Pytorch (https://arxiv.org/abs/1707.09405) This is a Pytorch implementation of cascaded
 63 Mar 27, 2022
63 Mar 27, 2022

Bilinear attention networks for visual question answering
Bilinear Attention Networks This repository is the implementation of Bilinear Attention Networks for the visual question answering and Flickr30k Entit
 506 Nov 29, 2022
506 Nov 29, 2022

source code of “Visual Saliency Transformer” (ICCV2021)
Visual Saliency Transformer (VST) source code for our ICCV 2021 paper “Visual Saliency Transformer” by Nian Liu, Ni Zhang, Kaiyuan Wan, Junwei Han, an
 89 Dec 21, 2022
89 Dec 21, 2022

🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
 7.7k Jan 5, 2023
7.7k Jan 5, 2023
A Strong Baseline for Image Semantic Segmentation
A Strong Baseline for Image Semantic Segmentation Introduction This project is an open source semantic segmentation toolbox based on PyTorch. It is ba
 49 Sep 20, 2022
49 Sep 20, 2022

Implementation of CVPR 2020 Dual Super-Resolution Learning for Semantic Segmentation
Dual super-resolution learning for semantic segmentation 2021-01-02 Subpixel Update Happy new year! The 2020-12-29 update of SISR with subpixel conv p
 79 Nov 24, 2022
79 Nov 24, 2022
Official implementation of "DSP: Dual Soft-Paste for Unsupervised Domain Adaptive Semantic Segmentation"
DSP Official implementation of "DSP: Dual Soft-Paste for Unsupervised Domain Adaptive Semantic Segmentation". Accepted by ACM Multimedia 2021. Authors
 20 Oct 24, 2022
20 Oct 24, 2022

Another pytorch implementation of FCN (Fully Convolutional Networks)
FCN-pytorch-easiest Trying to be the easiest FCN pytorch implementation and just in a get and use fashion Here I use a handbag semantic segmentation f
 158 Dec 21, 2022
158 Dec 21, 2022

PyTorch implementation of "Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning"
Transparency-by-Design networks (TbD-nets) This repository contains code for replicating the experiments and visualizations from the paper Transparenc
 351 Nov 18, 2022
351 Nov 18, 2022

FactSeg: Foreground Activation Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery (TGRS)
FactSeg: Foreground Activation Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery by Ailong Ma, Junjue Wang*, Yanfei Zhon
 43 Jan 5, 2023
43 Jan 5, 2023

Nvidia Semantic Segmentation monorepo
Paper | YouTube | Cityscapes Score Pytorch implementation of our paper Hierarchical Multi-Scale Attention for Semantic Segmentation. Please refer to t
 1.6k Jan 4, 2023
1.6k Jan 4, 2023

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022

Implementation of "Bidirectional Projection Network for Cross Dimension Scene Understanding" CVPR 2021 (Oral)
Bidirectional Projection Network for Cross Dimension Scene Understanding CVPR 2021 (Oral) [ Project Webpage ] [ arXiv ] [ Video ] Existing segmentatio
 135 Dec 26, 2022
135 Dec 26, 2022

URIE: Universal Image Enhancementfor Visual Recognition in the Wild
URIE: Universal Image Enhancementfor Visual Recognition in the Wild This is the implementation of the paper "URIE: Universal Image Enhancement for Vis
 43 Sep 12, 2022
43 Sep 12, 2022
improvement of CLIP features over the traditional resnet features on the visual question answering, image captioning, navigation and visual entailment tasks.
CLIP-ViL In our paper "How Much Can CLIP Benefit Vision-and-Language Tasks?", we show the improvement of CLIP features over the traditional resnet fea
 310 Dec 28, 2022
310 Dec 28, 2022
STMTrack: Template-free Visual Tracking with Space-time Memory Networks
STMTrack This is the official implementation of the paper: STMTrack: Template-free Visual Tracking with Space-time Memory Networks. Setup Prepare Anac
 62 Dec 21, 2022
62 Dec 21, 2022
Per-Pixel Classification is Not All You Need for Semantic Segmentation
MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation Bowen Cheng, Alexander G. Schwing, Alexander Kirillov [arXiv] [Proj
 1k Jan 8, 2023
1k Jan 8, 2023

PERIN is Permutation-Invariant Semantic Parser developed for MRP 2020
PERIN: Permutation-invariant Semantic Parsing David Samuel & Milan Straka Charles University Faculty of Mathematics and Physics Institute of Formal an
 40 Jan 4, 2023
40 Jan 4, 2023

Semantic Segmentation of images using PixelLib with help of Pascalvoc dataset trained with Deeplabv3+ framework.
CARscan- Approach 1 - Segmentation of images by detecting contours. It failed because in images with elements along with cars were also getting detect
 5 Jul 29, 2021
5 Jul 29, 2021
![[CVPR 2021] A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts](https://github.com/gyhandy/Visual-Reasoning-eXplanation/raw/main/docs/Fig-1.png)
[CVPR 2021] A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts
Visual-Reasoning-eXplanation [CVPR 2021 A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts] Project Page | Vid
 54 Dec 21, 2022
54 Dec 21, 2022

1st place solution to the Satellite Image Change Detection Challenge hosted by SenseTime
1st place solution to the Satellite Image Change Detection Challenge hosted by SenseTime
 209 Jan 1, 2023
209 Jan 1, 2023
STEAL - Learning Semantic Boundaries from Noisy Annotations (CVPR 2019)
STEAL This is the official inference code for: Devil Is in the Edges: Learning Semantic Boundaries from Noisy Annotations David Acuna, Amlan Kar, Sanj
 469 Dec 26, 2022
469 Dec 26, 2022

IJCAI2020 & IJCV 2020 :city_sunrise: Unsupervised Scene Adaptation with Memory Regularization in vivo
Seg_Uncertainty In this repo, we provide the code for the two papers, i.e., MRNet:Unsupervised Scene Adaptation with Memory Regularization in vivo, IJ
 348 Jan 5, 2023
348 Jan 5, 2023

The Medical Detection Toolkit contains 2D + 3D implementations of prevalent object detectors such as Mask R-CNN, Retina Net, Retina U-Net, as well as a training and inference framework focused on dealing with medical images.
The Medical Detection Toolkit contains 2D + 3D implementations of prevalent object detectors such as Mask R-CNN, Retina Net, Retina U-Net, as well as a training and inference framework focused on dealing with medical images.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
Semantic Scholar's Author Disambiguation Algorithm & Evaluation Suite
S2AND This repository provides access to the S2AND dataset and S2AND reference model described in the paper S2AND: A Benchmark and Evaluation System f
 54 Nov 28, 2022
54 Nov 28, 2022

This is the unofficial code of Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes. which achieve state-of-the-art trade-off between accuracy and speed on cityscapes and camvid, without using inference acceleration and extra data
Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes Introduction This is the unofficial code of Deep Dual-re
 113 Dec 23, 2022
113 Dec 23, 2022

Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion (CVPR 2021)
Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion (CVPR 2021) This repository is for BAAF-Net introduce
 90 Dec 29, 2022
90 Dec 29, 2022

Codes for TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised Object Localization.
TS-CAM: Token Semantic Coupled Attention Map for Weakly SupervisedObject Localization This is the official implementaion of paper TS-CAM: Token Semant
 112 Jan 2, 2023
112 Jan 2, 2023

box is a text-based visual programming language inspired by Unreal Engine Blueprint function graphs.
Box is a text-based visual programming language inspired by Unreal Engine blueprint function graphs. $ cat factorial.box ┌─ƒ(Factorial)───┐
 104 Dec 24, 2022
104 Dec 24, 2022

joint detection and semantic segmentation, based on ultralytics/yolov5,
Multi YOLO V5——Detection and Semantic Segmentation Overeview This is my undergraduate graduation project which based on ultralytics YOLO V5 tag v5.0.
 477 Jan 6, 2023
477 Jan 6, 2023
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
 564 Jan 3, 2023
564 Jan 3, 2023

Code for "Learning Canonical Representations for Scene Graph to Image Generation", Herzig & Bar et al., ECCV2020
Learning Canonical Representations for Scene Graph to Image Generation (ECCV 2020) Roei Herzig*, Amir Bar*, Huijuan Xu, Gal Chechik, Trevor Darrell, A
 24 Jul 7, 2022
24 Jul 7, 2022
![[CVPR2021] Look before you leap: learning landmark features for one-stage visual grounding.](https://github.com/svip-lab/LBYLNet/raw/main/imgs/landmarks.png)
[CVPR2021] Look before you leap: learning landmark features for one-stage visual grounding.
LBYL-Net This repo implements paper Look Before You Leap: Learning Landmark Features For One-Stage Visual Grounding CVPR 2021. Getting Started Prerequ
 45 Dec 12, 2022
45 Dec 12, 2022

VID-Fusion: Robust Visual-Inertial-Dynamics Odometry for Accurate External Force Estimation
VID-Fusion VID-Fusion: Robust Visual-Inertial-Dynamics Odometry for Accurate External Force Estimation Authors: Ziming Ding , Tiankai Yang, Kunyi Zhan
 86 Nov 18, 2022
86 Nov 18, 2022
Localizing Visual Sounds the Hard Way
Localizing-Visual-Sounds-the-Hard-Way Code and Dataset for "Localizing Visual Sounds the Hard Way". The repo contains code and our pre-trained model.
 58 Dec 7, 2022
58 Dec 7, 2022
![[CVPR 2020] Interpreting the Latent Space of GANs for Semantic Face Editing](https://github.com/genforce/interfacegan/raw/master/docs/assets/teaser.jpg)
[CVPR 2020] Interpreting the Latent Space of GANs for Semantic Face Editing
InterFaceGAN - Interpreting the Latent Space of GANs for Semantic Face Editing Figure: High-quality facial attributes editing results with InterFaceGA
 1.3k Dec 29, 2022
1.3k Dec 29, 2022

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023

Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
SEDE SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description
 83 Nov 11, 2022
83 Nov 11, 2022

(CVPR2021) DANNet: A One-Stage Domain Adaptation Network for Unsupervised Nighttime Semantic Segmentation
DANNet: A One-Stage Domain Adaptation Network for Unsupervised Nighttime Semantic Segmentation CVPR2021(oral) [arxiv] Requirements python3.7 pytorch==
 85 Dec 7, 2022
85 Dec 7, 2022

Official Pytorch Implementation of: "Semantic Diversity Learning for Zero-Shot Multi-label Classification"(2021) paper
Semantic Diversity Learning for Zero-Shot Multi-label Classification Paper Official PyTorch Implementation Avi Ben-Cohen, Nadav Zamir, Emanuel Ben Bar
 28 Aug 29, 2022
28 Aug 29, 2022

Orthogonal Over-Parameterized Training
The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is of great importance. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. See our previous work -- MHE for an in-depth introduction.
 11 Apr 18, 2022
11 Apr 18, 2022

Visual Weather api. Returns beautiful pictures with the current weather.
VWapi Visual Weather api. Returns beautiful pictures with the current weather. Installation: sudo apt update -y && sudo apt upgrade -y sudo apt instal
 33 Nov 13, 2022
33 Nov 13, 2022

MLP-Like Vision Permutator for Visual Recognition (PyTorch)
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition (arxiv) This is a Pytorch implementation of our paper. We present Vision
 162 Nov 28, 2022
162 Nov 28, 2022

Pytorch implementation of few-shot semantic image synthesis
Few-shot Semantic Image Synthesis Using StyleGAN Prior Our method can synthesize photorealistic images from dense or sparse semantic annotations using
 40 Sep 26, 2022
40 Sep 26, 2022

PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in clustering (CVPR2021)
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering Jang Hyun Cho1, Utkarsh Mall2, Kavita Bala2, Bharath Harihar
 164 Dec 30, 2022
164 Dec 30, 2022
PyTorch implementation code for the paper MixCo: Mix-up Contrastive Learning for Visual Representation
How to Reproduce our Results This repository contains PyTorch implementation code for the paper MixCo: Mix-up Contrastive Learning for Visual Represen
 46 Dec 15, 2022
46 Dec 15, 2022

VOLO: Vision Outlooker for Visual Recognition
VOLO: Vision Outlooker for Visual Recognition, arxiv This is a PyTorch implementation of our paper. We present Vision Outlooker (VOLO). We show that o
 876 Dec 9, 2022
876 Dec 9, 2022
Code for the paper One Thing One Click: A Self-Training Approach for Weakly Supervised 3D Semantic Segmentation, CVPR 2021.
One Thing One Click One Thing One Click: A Self-Training Approach for Weakly Supervised 3D Semantic Segmentation (CVPR2021) Code for the paper One Thi
 44 Dec 12, 2022
44 Dec 12, 2022

Code for the RA-L (ICRA) 2021 paper "SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition"
SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition [ArXiv+Supplementary] [IEEE Xplore RA-L 2021] [ICRA 2021 YouTube Video]
 63 Dec 12, 2022
63 Dec 12, 2022

Implementation of Diverse Semantic Image Synthesis via Probability Distribution Modeling
Diverse Semantic Image Synthesis via Probability Distribution Modeling (CVPR 2021) Paper Zhentao Tan, Menglei Chai, Dongdong Chen, Jing Liao, Qi Chu,
 45 Nov 17, 2022
45 Nov 17, 2022

JittorVis - Visual understanding of deep learning model.
JittorVis is a deep neural network computational graph visualization library based on Jittor.
 182 Jan 6, 2023
182 Jan 6, 2023
Jina allows you to build deep learning-powered search-as-a-service in just minutes
Cloud-native neural search framework for any kind of data
 17k Dec 31, 2022
17k Dec 31, 2022

Episodic Transformer (E.T.) is a novel attention-based architecture for vision-and-language navigation. E.T. is based on a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions.
Episodic Transformers (E.T.) Episodic Transformer for Vision-and-Language Navigation Alexander Pashevich, Cordelia Schmid, Chen Sun Episodic Transform
 62 Dec 24, 2022
62 Dec 24, 2022
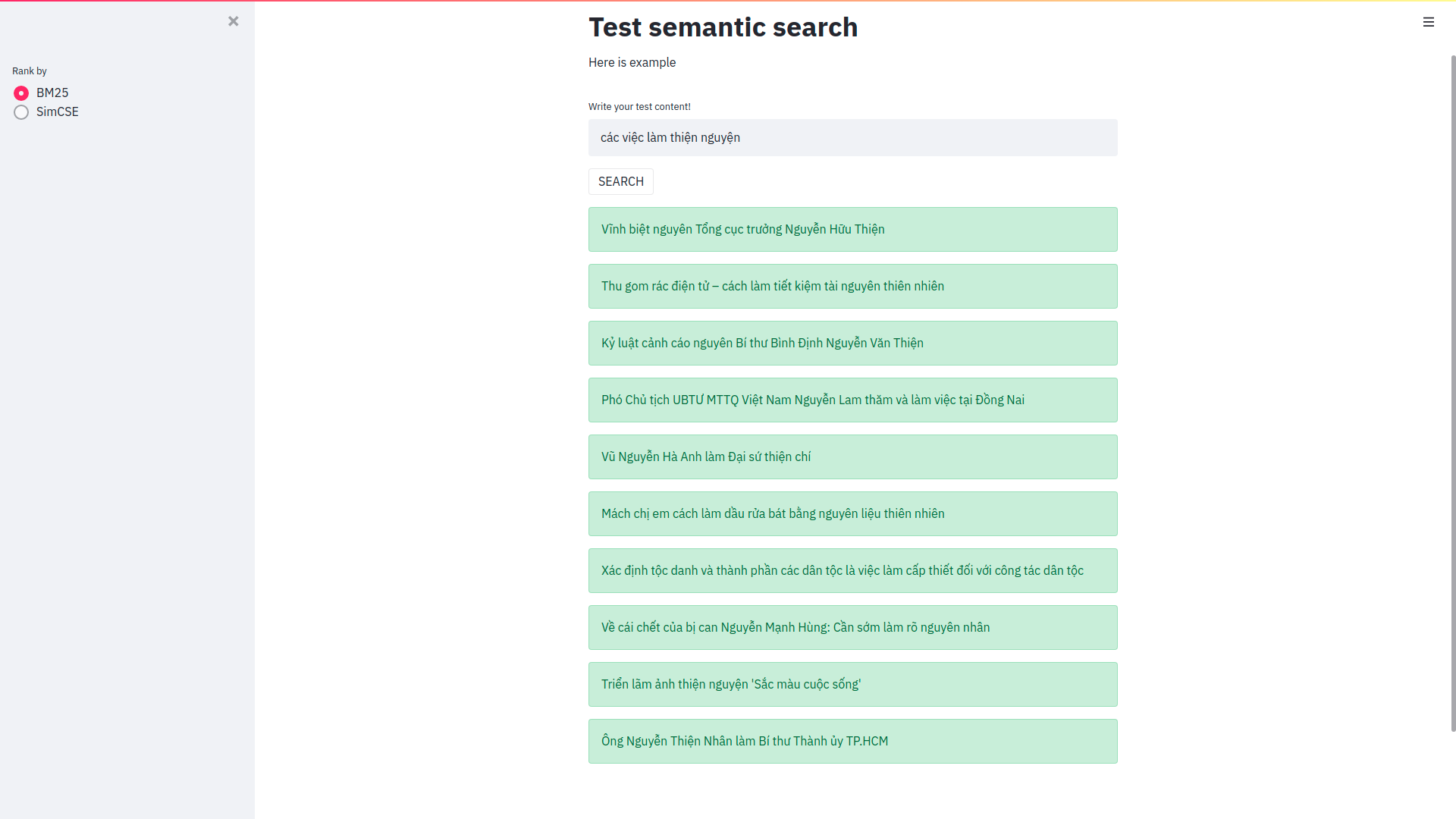
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings Trong bài viết này mình sẽ sử dụng pretrain model SimCS
 18 Nov 25, 2022
18 Nov 25, 2022

Pytorch implementation of the paper SPICE: Semantic Pseudo-labeling for Image Clustering
SPICE: Semantic Pseudo-labeling for Image Clustering By Chuang Niu and Ge Wang This is a Pytorch implementation of the paper. (In updating) SOTA on 5
 154 Dec 15, 2022
154 Dec 15, 2022
Unifying Cross-Lingual Semantic Role Labeling with Heterogeneous Linguistic Resources (NAACL-2021).
Unifying Cross-Lingual Semantic Role Labeling with Heterogeneous Linguistic Resources Description This is the repository for the paper Unifying Cross-
 16 Sep 9, 2022
16 Sep 9, 2022

Official implementation of "SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers"
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers Figure 1: Performance of SegFormer-B0 to SegFormer-B5. Project page
 1.4k Dec 31, 2022
1.4k Dec 31, 2022
![Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations. [2021]](https://github.com/wvangansbeke/Revisiting-Contrastive-SSL/raw/main/images/teaser.jpg)
Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations. [2021]
Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations This repo contains the Pytorch implementation of our paper: Revisit
 80 Nov 20, 2022
80 Nov 20, 2022
FANet - Real-time Semantic Segmentation with Fast Attention
FANet Real-time Semantic Segmentation with Fast Attention Ping Hu, Federico Perazzi, Fabian Caba Heilbron, Oliver Wang, Zhe Lin, Kate Saenko , Stan Sc
 42 Nov 30, 2022
42 Nov 30, 2022
Code for our paper "Sematic Representation for Dialogue Modeling" in ACL2021
AMR-Dialogue An implementation for paper "Semantic Representation for Dialogue Modeling". You may find our paper here. Requirements python 3.6 pytorch
 45 Dec 26, 2022
45 Dec 26, 2022

Keep CALM and Improve Visual Feature Attribution
Keep CALM and Improve Visual Feature Attribution Jae Myung Kim1*, Junsuk Choe1*, Zeynep Akata2, Seong Joon Oh1† * Equal contribution † Corresponding a
 90 Dec 7, 2022
90 Dec 7, 2022
Semantic-based Patch Detection for Binary Programs
PMatch Semantic-based Patch Detection for Binary Programs Requirement tensorflow-gpu 1.13.1 numpy 1.16.2 scikit-learn 0.20.3 ssdeep 3.4 Usage tar -xvz
 3 Sep 2, 2022
3 Sep 2, 2022

CATs: Semantic Correspondence with Transformers
CATs: Semantic Correspondence with Transformers For more information, check out the paper on [arXiv]. Training with different backbones and evaluation
 74 Dec 10, 2021
74 Dec 10, 2021

Code for paper: Group-CAM: Group Score-Weighted Visual Explanations for Deep Convolutional Networks
Group-CAM By Zhang, Qinglong and Rao, Lu and Yang, Yubin [State Key Laboratory for Novel Software Technology at Nanjing University] This repo is the o
 98 Nov 16, 2022
98 Nov 16, 2022

This package is for running the semantic SLAM algorithm using extracted planar surfaces from the received detection
Semantic SLAM This package can perform optimization of pose estimated from VO/VIO methods which tend to drift over time. It uses planar surfaces extra
 125 Dec 2, 2022
125 Dec 2, 2022

The implementation of PEMP in paper "Prior-Enhanced Few-Shot Segmentation with Meta-Prototypes"
Prior-Enhanced network with Meta-Prototypes (PEMP) This is the PyTorch implementation of PEMP. Overview of PEMP Meta-Prototypes & Adaptive Prototypes
 8 Oct 14, 2021
8 Oct 14, 2021

An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C.
vizh An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C. Overview Her
 228 Dec 17, 2022
228 Dec 17, 2022
PyTorch implementation for ACL 2021 paper "Maria: A Visual Experience Powered Conversational Agent".
Maria: A Visual Experience Powered Conversational Agent This repository is the Pytorch implementation of our paper "Maria: A Visual Experience Powered
 22 Dec 12, 2022
22 Dec 12, 2022

3D AffordanceNet is a 3D point cloud benchmark consisting of 23k shapes from 23 semantic object categories, annotated with 56k affordance annotations and covering 18 visual affordance categories.
3D AffordanceNet This repository is the official experiment implementation of 3D AffordanceNet benchmark. 3D AffordanceNet is a 3D point cloud benchma
 49 Dec 1, 2022
49 Dec 1, 2022
![A 2D Visual Localization Framework based on Essential Matrices [ICRA2020]](https://github.com/GrumpyZhou/visloc-relapose/raw/master/pipeline/pipeline.jpg)
A 2D Visual Localization Framework based on Essential Matrices [ICRA2020]
A 2D Visual Localization Framework based on Essential Matrices This repository provides implementation of our paper accepted at ICRA: To Learn or Not
 27 Nov 7, 2022
27 Nov 7, 2022
FLVIS: Feedback Loop Based Visual Initial SLAM
FLVIS Feedback Loop Based Visual Inertial SLAM 1-Video EuRoC DataSet MH_05 Handheld Test in Lab FlVIS on UAV Platform 2-Relevent Publication: Under Re
 182 Dec 4, 2022
182 Dec 4, 2022