1678 Repositories
Python Drug-Rating-Prediction-Portal-from-Drug-Reviews-Dataset-NLP-ML Libraries
Hierarchical Attentive Recurrent Tracking
Hierarchical Attentive Recurrent Tracking This is an official Tensorflow implementation of single object tracking in videos by using hierarchical atte
 147 Aug 7, 2021
147 Aug 7, 2021
Real-time object detection on Android using the YOLO network with TensorFlow
TensorFlow YOLO object detection on Android Source project android-yolo is the first implementation of YOLO for TensorFlow on an Android device. It is
 624 Jan 3, 2023
624 Jan 3, 2023
Multi-Person Extreme Motion Prediction
Multi-Person Extreme Motion Prediction Implementation for paper Wen Guo, Xiaoyu Bie, Xavier Alameda-Pineda, Francesc Moreno-Noguer, Multi-Person Extre
 38 Nov 15, 2022
38 Nov 15, 2022
A design of MIDI language for music generation task, specifically for Natural Language Processing (NLP) models.
MIDI Language Introduction Reference Paper: Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions: code This
 3 May 25, 2022
3 May 25, 2022
Course project of NLP@UCAS
NaiveMT Prepare Clone this repository git clone [email protected]:Poeroz/NaiveMT.git Install Please first install PyTorch = 1.5.0, then type the followi
 2 Apr 24, 2022
2 Apr 24, 2022
SLAMP: Stochastic Latent Appearance and Motion Prediction
SLAMP: Stochastic Latent Appearance and Motion Prediction Official implementation of the paper SLAMP: Stochastic Latent Appearance and Motion Predicti
 34 Dec 8, 2022
34 Dec 8, 2022

Predicting Axillary Lymph Node Metastasis in Early Breast Cancer Using Deep Learning on Primary Tumor Biopsy Slides
Predicting Axillary Lymph Node Metastasis in Early Breast Cancer Using Deep Learning on Primary Tumor Biopsy Slides Project | This repo is the officia
 33 Dec 28, 2022
33 Dec 28, 2022
Simple bots or Simbots is a library designed to create simple bots using the power of python. This library utilises Intent, Entity, Relation and Context model to create bots .
Simple bots or Simbots is a library designed to create simple chat bots using the power of python. This library utilises Intent, Entity, Relation and
 14 Dec 15, 2021
14 Dec 15, 2021
Source code and dataset of the paper "Contrastive Adaptive Propagation Graph Neural Networks forEfficient Graph Learning"
CAPGNN Source code and dataset of the paper "Contrastive Adaptive Propagation Graph Neural Networks forEfficient Graph Learning" Paper URL: https://ar
 1 Mar 12, 2022
1 Mar 12, 2022
Experiments with the Robust Binary Interval Search (RBIS) algorithm, a Query-Based prediction algorithm for the Online Search problem.
OnlineSearchRBIS Online Search with Best-Price and Query-Based Predictions This is the implementation of the Robust Binary Interval Search (RBIS) algo
 1 Apr 16, 2022
1 Apr 16, 2022
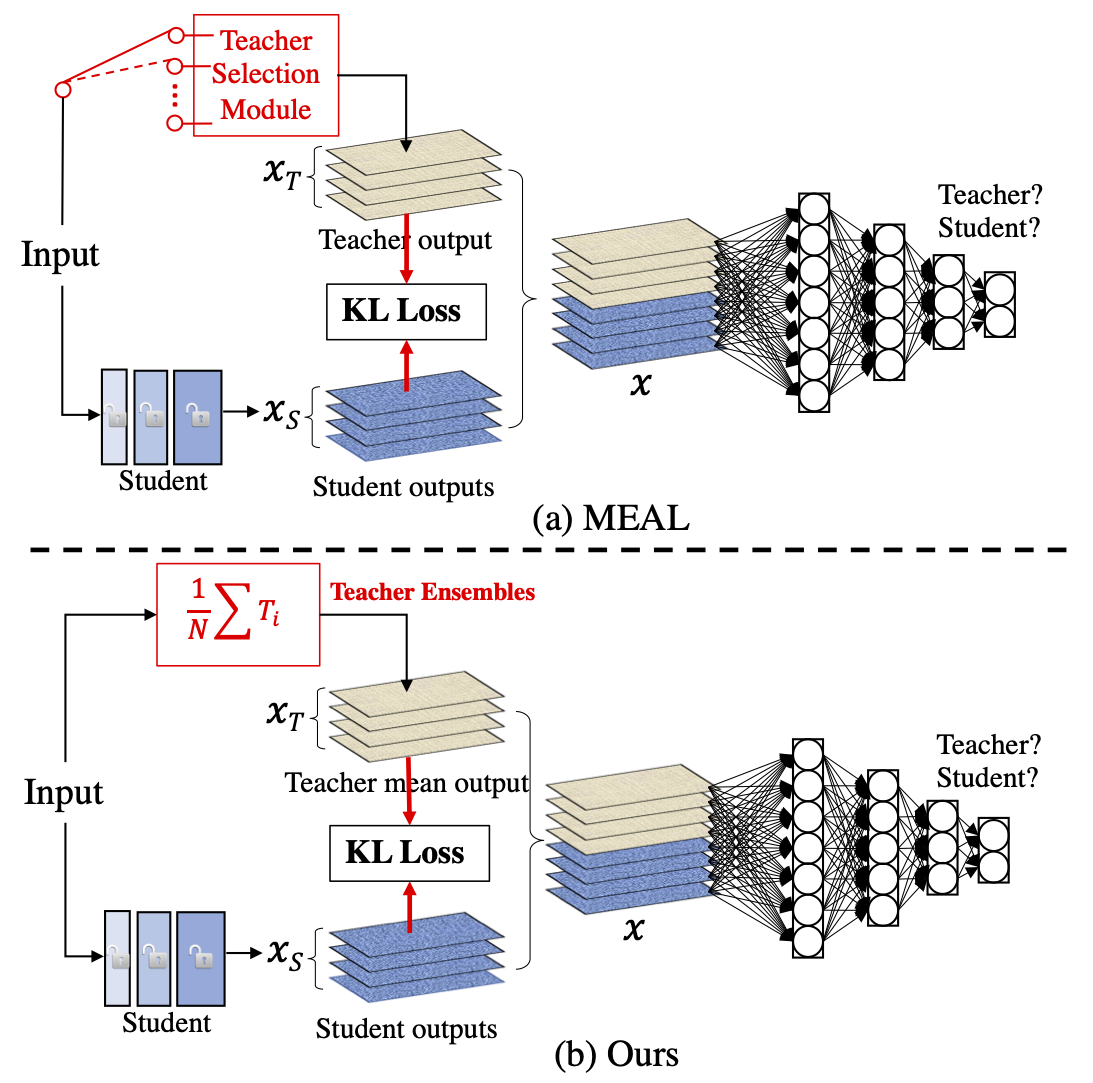
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
MEAL-V2 This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tric
 653 Dec 19, 2022
653 Dec 19, 2022
DaReCzech is a dataset for text relevance ranking in Czech
Dataset DaReCzech is a dataset for text relevance ranking in Czech. The dataset consists of more than 1.6M annotated query-documents pairs,
 8 Jul 26, 2022
8 Jul 26, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022

Contra is a lightweight, production ready Tensorflow alternative for solving time series prediction challenges with AI
Contra AI Engine A lightweight, production ready Tensorflow alternative developed by Styvio styvio.com » How to Use · Report Bug · Request Feature Tab
 14 May 25, 2022
14 May 25, 2022
An assignment from my grad-level data mining course demonstrating some experience with NLP/neural networks/Pytorch
NLP-Pytorch-Assignment An assignment from my grad-level data mining course (before I started personal projects) demonstrating some experience with NLP
 0 Feb 6, 2022
0 Feb 6, 2022

Air Pollution Prediction System using Linear Regression and ANN
AirPollution Pollution Weather Prediction System: Smart Outdoor Pollution Monitoring and Prediction for Healthy Breathing and Living Publication Link:
 19 Feb 7, 2022
19 Feb 7, 2022
public repo for ESTER dataset and modeling (EMNLP'21)
Project / Paper Introduction This is the project repo for our EMNLP'21 paper: https://arxiv.org/abs/2104.08350 Here, we provide brief descriptions of
 19 Oct 27, 2022
19 Oct 27, 2022

Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU
GPU Docker NLP Application Deployment Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU, to setup the enviroment on
 9 Oct 14, 2022
9 Oct 14, 2022
The official homepage of the (outdated) COCO-Stuff 10K dataset.
COCO-Stuff 10K dataset v1.1 (outdated) Holger Caesar, Jasper Uijlings, Vittorio Ferrari Overview Welcome to official homepage of the COCO-Stuff [1] da
 263 Dec 11, 2022
263 Dec 11, 2022

Simple API for UCI Machine Learning Dataset Repository (search, download, analyze)
A simple API for working with University of California, Irvine (UCI) Machine Learning (ML) repository Table of Contents Introduction About Page of the
 223 Dec 5, 2022
223 Dec 5, 2022

Joint Detection and Identification Feature Learning for Person Search
Person Search Project This repository hosts the code for our paper Joint Detection and Identification Feature Learning for Person Search. The code is
 712 Dec 17, 2022
712 Dec 17, 2022
Natural Language Processing Tasks and Examples.
Natural Language Processing Tasks and Examples With the advancement of A.I. technology in recent years, natural language processing technology has bee
 53 Dec 20, 2022
53 Dec 20, 2022
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022

This is a project built for FALLABOUT2021 event under SRMMIC, This project deals with NLP poetry generation.
FALLABOUT-SRMMIC 21 POETRY-GENERATION HINGLISH DESCRIPTION We have developed a NLP(natural language processing) model which automatically generates a
 7 Sep 28, 2021
7 Sep 28, 2021

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
463 Dec 30, 2022

SentAugment is a data augmentation technique for semi-supervised learning in NLP.
SentAugment SentAugment is a data augmentation technique for semi-supervised learning in NLP. It uses state-of-the-art sentence embeddings to structur
 363 Dec 30, 2022
363 Dec 30, 2022
Source code and dataset for ACL 2019 paper "ERNIE: Enhanced Language Representation with Informative Entities"
ERNIE Source code and dataset for "ERNIE: Enhanced Language Representation with Informative Entities" Reqirements: Pytorch=0.4.1 Python3 tqdm boto3 r
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph",
K-BERT Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph", which is implemented based on the UER framework. R
 834 Jan 9, 2023
834 Jan 9, 2023
![[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations](https://github.com/kdexd/virtex/raw/master/docs/_static/system_figure.jpg)
[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations
VirTex: Learning Visual Representations from Textual Annotations Karan Desai and Justin Johnson University of Michigan CVPR 2021 arxiv.org/abs/2006.06
 533 Dec 24, 2022
533 Dec 24, 2022

CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer
CSAW-M This repository contains code for CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer. Source code for tr
 7 Oct 11, 2022
7 Oct 11, 2022

PartImageNet is a large, high-quality dataset with part segmentation annotations
PartImageNet: A Large, High-Quality Dataset of Parts We will release our dataset and scripts soon after cleaning and approval. Introduction PartImageN
 77 Nov 30, 2022
77 Nov 30, 2022

DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting Created by Yongming Rao*, Wenliang Zhao*, Guangyi Chen, Yansong Tang, Zheng Z
 322 Dec 31, 2022
322 Dec 31, 2022

Editing a classifier by rewriting its prediction rules
This repository contains the code and data for our paper: Editing a classifier by rewriting its prediction rules Shibani Santurkar*, Dimitris Tsipras*
 86 Dec 27, 2022
86 Dec 27, 2022

Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
 2 Dec 2, 2021
2 Dec 2, 2021
An kind of operating system portal to a variety of apps with pure python
pyos An kind of operating system portal to a variety of apps. Installation Run this on your terminal: git clone https://github.com/arjunj132/pyos.git
 1 Jan 22, 2022
1 Jan 22, 2022
The Malware Open-source Threat Intelligence Family dataset contains 3,095 disarmed PE malware samples from 454 families
MOTIF Dataset The Malware Open-source Threat Intelligence Family (MOTIF) dataset contains 3,095 disarmed PE malware samples from 454 families, labeled
 112 Dec 13, 2022
112 Dec 13, 2022
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting Created by Yongming Rao*, Wenliang Zhao*, Guangyi Chen, Yansong Tang, Zheng Z
321 Dec 27, 2022

Artstation-Artistic-face-HQ Dataset (AAHQ)
Artstation-Artistic-face-HQ Dataset (AAHQ) Artstation-Artistic-face-HQ (AAHQ) is a high-quality image dataset of artistic-face images. It is proposed
 105 Dec 16, 2022
105 Dec 16, 2022

IMDb + Auto + Unlimited Filter BoT
Telegram Movie Bot Features Auto Filter Manuel Filter IMDB Admin Commands Broadcast Index IMDB search Inline Search Random pics ids and User info Stat
 1 Dec 3, 2021
1 Dec 3, 2021

Modified GPT using average pooling to reduce the softmax attention memory constraints.
NLP-GPT-Upsampling This repository contains an implementation of Open AI's GPT Model. In particular, this implementation takes inspiration from the Ny
 1 Dec 3, 2021
1 Dec 3, 2021
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
Code for Editing Factual Knowledge in Language Models
KnowledgeEditor Code for Editing Factual Knowledge in Language Models (https://arxiv.org/abs/2104.08164). @inproceedings{decao2021editing, title={Ed
 86 Nov 28, 2022
86 Nov 28, 2022
Code for the paper "Are Sixteen Heads Really Better than One?"
Are Sixteen Heads Really Better than One? This repository contains code to reproduce the experiments in our paper Are Sixteen Heads Really Better than
 143 Dec 14, 2022
143 Dec 14, 2022

The official implementation of "BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?, ACL 2021 main conference"
BERT is to NLP what AlexNet is to CV This is the official implementation of BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Iden
 20 Nov 3, 2022
20 Nov 3, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
 2.1k Dec 28, 2022
2.1k Dec 28, 2022
Research code for "What to Pre-Train on? Efficient Intermediate Task Selection", EMNLP 2021
efficient-task-transfer This repository contains code for the experiments in our paper "What to Pre-Train on? Efficient Intermediate Task Selection".
 26 Dec 24, 2022
26 Dec 24, 2022
Adapter-BERT: Parameter-Efficient Transfer Learning for NLP.
Adapter-BERT: Parameter-Efficient Transfer Learning for NLP.
340 Jan 3, 2023
This repository contains the code for "Exploiting Cloze Questions for Few-Shot Text Classification and Natural Language Inference"
Pattern-Exploiting Training (PET) This repository contains the code for Exploiting Cloze Questions for Few-Shot Text Classification and Natural Langua
 1.4k Dec 30, 2022
1.4k Dec 30, 2022
EasyTransfer is designed to make the development of transfer learning in NLP applications easier.
EasyTransfer is designed to make the development of transfer learning in NLP applications easier. The literature has witnessed the success of applying
 819 Jan 3, 2023
819 Jan 3, 2023

🥇Samsung AI Challenge 2021 1등 솔루션입니다🥇
MoT - Molecular Transformer Large-scale Pretraining for Molecular Property Prediction Samsung AI Challenge for Scientific Discovery This repository is
 44 Dec 3, 2022
44 Dec 3, 2022

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022

Cooperative Driving Dataset: a dataset for multi-agent driving scenarios
Cooperative Driving Dataset (CODD) The Cooperative Driving dataset is a synthetic dataset generated using CARLA that contains lidar data from multiple
 124 Dec 28, 2022
124 Dec 28, 2022

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023
Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
8 Oct 6, 2022
A set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI.
Overview This is a set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI. Make TFRecords To run t
 8 Nov 1, 2022
8 Nov 1, 2022
The official homepage of the COCO-Stuff dataset.
The COCO-Stuff dataset Holger Caesar, Jasper Uijlings, Vittorio Ferrari Welcome to official homepage of the COCO-Stuff [1] dataset. COCO-Stuff augment
715 Dec 31, 2022
Python script to download the celebA-HQ dataset from google drive
download-celebA-HQ Python script to download and create the celebA-HQ dataset. WARNING from the author. I believe this script is broken since a few mo
 133 Dec 21, 2022
133 Dec 21, 2022
[3DV 2021] A Dataset-Dispersion Perspective on Reconstruction Versus Recognition in Single-View 3D Reconstruction Networks
dispersion-score Official implementation of 3DV 2021 Paper A Dataset-dispersion Perspective on Reconstruction versus Recognition in Single-view 3D Rec
 7 May 28, 2022
7 May 28, 2022

Dataset for the Research2Clinics @ NeurIPS 2021 Paper: What Do You See in this Patient? Behavioral Testing of Clinical NLP Models
Behavioral Testing of Clinical NLP Models This repository contains code for testing the behavior of clinical prediction models based on patient letter
 2 Sep 20, 2022
2 Sep 20, 2022

Official PyTorch Implementation of HELP: Hardware-adaptive Efficient Latency Prediction for NAS via Meta-Learning (NeurIPS 2021 Spotlight)
[NeurIPS 2021 Spotlight] HELP: Hardware-adaptive Efficient Latency Prediction for NAS via Meta-Learning [Paper] This is Official PyTorch implementatio
 4 Nov 25, 2021
4 Nov 25, 2021
Auditing Black-Box Prediction Models for Data Minimization Compliance
Data-Minimization-Auditor An auditing tool for model-instability based data minimization that is introduced in "Auditing Black-Box Prediction Models f
 2 Mar 24, 2022
2 Mar 24, 2022
Dataset and codebase for NeurIPS 2021 paper: Exploring Forensic Dental Identification with Deep Learning
Repository under construction. Example dataset, checkpoints, and training/testing scripts will be avaible soon! 💡 Collated best practices from most p
 4 Jun 26, 2022
4 Jun 26, 2022
Info and sample codes for "NTU RGB+D Action Recognition Dataset"
"NTU RGB+D" Action Recognition Dataset "NTU RGB+D 120" Action Recognition Dataset "NTU RGB+D" is a large-scale dataset for human action recognition. I
 578 Dec 30, 2022
578 Dec 30, 2022

DALLE-tools provided useful dataset utilities to improve you workflow with WebDatasets.
DALLE tools DALLE-tools is a github repository with useful tools to categorize, annotate or check the sanity of your datasets. Installation Just clone
 11 Dec 25, 2022
11 Dec 25, 2022
Behavioral Testing of Clinical NLP Models
Behavioral Testing of Clinical NLP Models This repository contains code for testing the behavior of clinical prediction models based on patient letter
2 Sep 20, 2022
CCPD: a diverse and well-annotated dataset for license plate detection and recognition
CCPD (Chinese City Parking Dataset, ECCV) UPdate on 10/03/2019. CCPD Dataset is now updated. We are confident that images in subsets of CCPD is much m
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
Cluttered MNIST Dataset
Cluttered MNIST Dataset A setup script will download MNIST and produce mnist/*.t7 files: luajit download_mnist.lua Example usage: local mnist_clutter
 50 Jul 12, 2022
50 Jul 12, 2022
A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset
xwrf A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset. The primary objective of
 43 Nov 29, 2022
43 Nov 29, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022
Long Expressive Memory (LEM)
Long Expressive Memory for Sequence Modeling This repository contains the implementation to reproduce the numerical experiments of the paper Long Expr
 47 Dec 17, 2022
47 Dec 17, 2022

Project to deploy a machine learning model based on Titanic dataset from Kaggle
kaggle_titanic_deploy Project to deploy a machine learning model based on Titanic dataset from Kaggle In this project we used the Titanic dataset from
 8 May 23, 2022
8 May 23, 2022
Set of methods to ensemble boxes from different object detection models, including implementation of "Weighted boxes fusion (WBF)" method.
Set of methods to ensemble boxes from different object detection models, including implementation of "Weighted boxes fusion (WBF)" method.
 1.4k Jan 5, 2023
1.4k Jan 5, 2023

Source code for ZePHyR: Zero-shot Pose Hypothesis Rating @ ICRA 2021
ZePHyR: Zero-shot Pose Hypothesis Rating ZePHyR is a zero-shot 6D object pose estimation pipeline. The core is a learned scoring function that compare
 18 Aug 22, 2022
18 Aug 22, 2022
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset This repository contains links to data and code to fetch and reproduce
 19 Dec 16, 2022
19 Dec 16, 2022
COIN the currently largest dataset for comprehensive instruction video analysis.
COIN Dataset COIN is the currently largest dataset for comprehensive instruction video analysis. It contains 11,827 videos of 180 different tasks (i.e
 86 Dec 28, 2022
86 Dec 28, 2022
Dataset and Source code of paper 'Enhancing Keyphrase Extraction from Academic Articles with their Reference Information'.
Enhancing Keyphrase Extraction from Academic Articles with their Reference Information Overview Dataset and code for paper "Enhancing Keyphrase Extrac
 15 Nov 24, 2022
15 Nov 24, 2022

A benchmark dataset for emulating atmospheric radiative transfer in weather and climate models with machine learning (NeurIPS 2021 Datasets and Benchmarks Track)
ClimART - A Benchmark Dataset for Emulating Atmospheric Radiative Transfer in Weather and Climate Models Official PyTorch Implementation Using deep le
 21 Dec 31, 2022
21 Dec 31, 2022
Source Code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chinese Question Matching
Description The source code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chin
 3 Jun 28, 2022
3 Jun 28, 2022
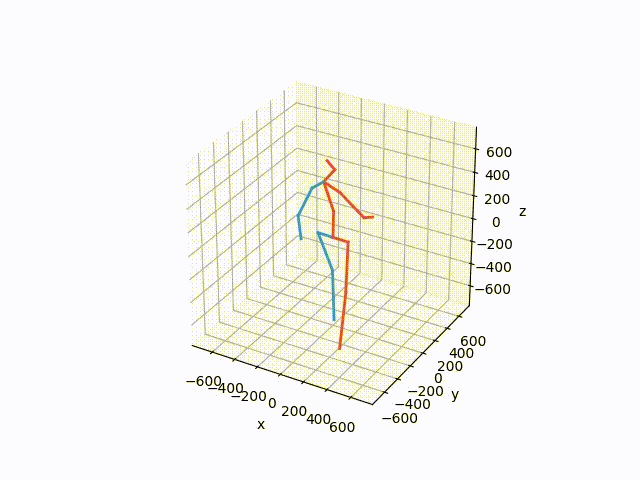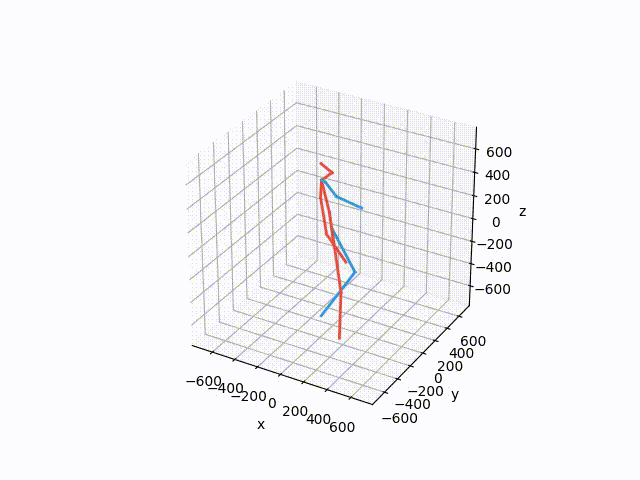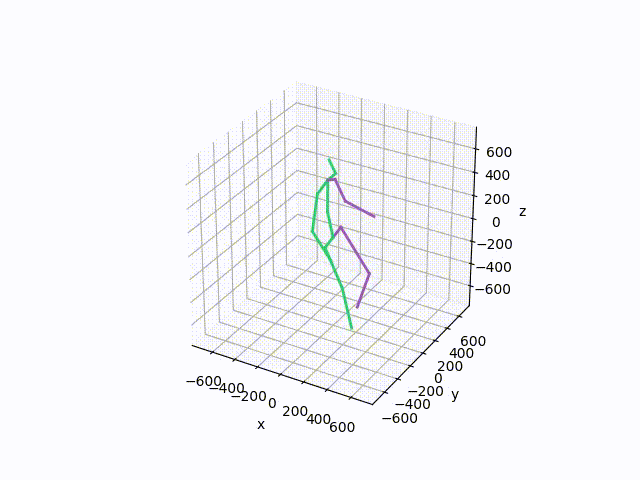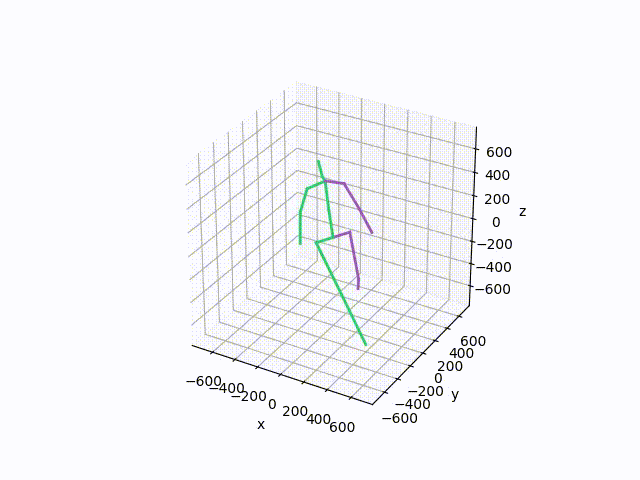
Plot and save the ground truth and predicted results of human 3.6 M and CMU mocap dataset.
Visualization-of-Human3.6M-Dataset Plot and save the ground truth and predicted results of human 3.6 M and CMU mocap dataset. human-motion-prediction
 5 Nov 18, 2022
5 Nov 18, 2022
A benchmark dataset for mesh multi-label-classification based on cube engravings introduced in MeshCNN
Double Cube Engravings This script creates a dataset for multi-label mesh clasification, with an intentionally difficult setup for point cloud classif
 1 Nov 30, 2021
1 Nov 30, 2021
A fast, dataset-agnostic, deep visual search engine for digital art history
imgs.ai imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings. It utilizes modern
 5 Dec 14, 2022
5 Dec 14, 2022
Predicting diabetes over a five year period using logistic regression and the Pima First-Nation dataset
Diabetes This script uses the Pima First Nations dataset to create a model to predict whether or not an individual will develop Diabetes Mellitus Type
 1 Mar 28, 2022
1 Mar 28, 2022
Train an imgs.ai model on your own dataset
imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings.
5 Dec 21, 2021

Molecular Sets (MOSES): A Benchmarking Platform for Molecular Generation Models
Molecular Sets (MOSES): A benchmarking platform for molecular generation models Deep generative models are rapidly becoming popular for the discovery
 656 Dec 29, 2022
656 Dec 29, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

This repository contains the source code of our work on designing efficient CNNs for computer vision
Efficient networks for Computer Vision This repo contains source code of our work on designing efficient networks for different computer vision tasks:
 386 Nov 26, 2022
386 Nov 26, 2022
WSDM‘2022: Knowledge Enhanced Sports Game Summarization
Knowledge Enhanced Sports Game Summarization Cooming Soon! :) Data will be released after approval process. Code will be published once the author of
 14 Jul 13, 2022
14 Jul 13, 2022

This code is for eCaReNet: explainable Cancer Relapse Prediction Network.
eCaReNet This code is for eCaReNet: explainable Cancer Relapse Prediction Network. (Towards Explainable End-to-End Prostate Cancer Relapse Prediction
 2 Jul 28, 2022
2 Jul 28, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
An open-source Kazakh named entity recognition dataset (KazNERD), annotation guidelines, and baseline NER models.
Kazakh Named Entity Recognition This repository contains an open-source Kazakh named entity recognition dataset (KazNERD), named entity annotation gui
 9 Dec 23, 2022
9 Dec 23, 2022

Boston House Prediction Valuation Tool
Boston-House-Prediction-Valuation-Tool From Below Anlaysis The Valuation Tool is Designed Correlation Matrix Regrssion Analysis Between Target Vs Pred
 0 Sep 9, 2022
0 Sep 9, 2022
LSUN Dataset Documentation and Demo Code
LSUN Please check LSUN webpage for more information about the dataset. Data Release All the images in one category are stored in one lmdb database fil
 426 Jan 2, 2023
426 Jan 2, 2023
A new test set for ImageNet
ImageNetV2 The ImageNetV2 dataset contains new test data for the ImageNet benchmark. This repository provides associated code for assembling and worki
 186 Dec 18, 2022
186 Dec 18, 2022

Eulera Dashboard is an easy and intuitive way to get a quick feel of what’s happening on the world’s market.
an easy and intuitive way to get a quick feel of what’s happening on the world’s market ! Eulera dashboard is a tool allows you to monitor historical
 4 Nov 25, 2022
4 Nov 25, 2022
A logistic regression model for health insurance purchasing prediction
Logistic_Regression_Model A logistic regression model for health insurance purchasing prediction This code is using these packages, so please make sur
 1 Nov 29, 2021
1 Nov 29, 2021
Haystack is an open source NLP framework that leverages Transformer models.
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
 2.7k Nov 28, 2021
2.7k Nov 28, 2021
Qlib is an AI-oriented quantitative investment platform
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment.
 10.1k Dec 30, 2022
10.1k Dec 30, 2022
Code for our NeurIPS 2021 paper: Sparsely Changing Latent States for Prediction and Planning in Partially Observable Domains
GateL0RD This is a lightweight PyTorch implementation of GateL0RD, our RNN presented in "Sparsely Changing Latent States for Prediction and Planning i
 16 Nov 3, 2022
16 Nov 3, 2022