733 Repositories
Python chinese-nlp Libraries

Label data using HuggingFace's transformers and automatically get a prediction service
Label Studio for Hugging Face's Transformers Website • Docs • Twitter • Join Slack Community Transfer learning for NLP models by annotating your textu
 135 Dec 29, 2022
135 Dec 29, 2022

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 342 Jan 5, 2023
342 Jan 5, 2023
The code for the Subformer, from the EMNLP 2021 Findings paper: "Subformer: Exploring Weight Sharing for Parameter Efficiency in Generative Transformers", by Machel Reid, Edison Marrese-Taylor, and Yutaka Matsuo
Subformer This repository contains the code for the Subformer. To help overcome this we propose the Subformer, allowing us to retain performance while
 10 Dec 27, 2022
10 Dec 27, 2022
Transcribing audio files using Hugging Face's implementation of Wav2Vec2 + "chain-linking" NLP tasks to combine speech-to-text with downstream tasks like translation and summarisation.
PART 2: CHAIN LINKING AUDIO-TO-TEXT NLP TASKS 2A: TRANSCRIBE-TRANSLATE-SENTIMENT-ANALYSIS In notebook3.0, I demo a simple workflow to: transcribe a lo
 30 Jul 13, 2022
30 Jul 13, 2022
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
 2.1k Dec 28, 2022
2.1k Dec 28, 2022

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023

The projects lets you extract glossary words and their definitions from a given piece of text automatically using NLP techniques
Unsupervised technique to Glossary and Definition Extraction Code Files GPT2-DefinitionModel.ipynb - GPT-2 model for definition generation. Data_Gener
 28 May 25, 2021
28 May 25, 2021

Powerful unsupervised domain adaptation method for dense retrieval.
Powerful unsupervised domain adaptation method for dense retrieval
 191 Dec 28, 2022
191 Dec 28, 2022
Converts a Bangla numeric string to literal words.
Bangla Number in Words Converts a Bangla numeric string to literal words. Install $ pip install banglanum2words Usage
 3 Aug 29, 2022
3 Aug 29, 2022
Text completion with Hugging Face and TensorFlow.js running on Node.js
Katana ML Text Completion 🤗 Description Runs with with Hugging Face DistilBERT and TensorFlow.js on Node.js distilbert-model - converter from Hugging
 2 Nov 4, 2022
2 Nov 4, 2022
Using Bert as the backbone model for lime, designed for NLP task explanation (sentence pair text classification task)
Lime Comparing deep contextualized model for sentences highlighting task. In addition, take the classic explanation model "LIME" with bert-base model
 2 Jan 18, 2022
2 Jan 18, 2022
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
keytotext Idea is to build a model which will take keywords as inputs and generate sentences as outputs. Potential use case can include: Marketing Sea
 364 Jan 3, 2023
364 Jan 3, 2023

A toolkit for document-level event extraction, containing some SOTA model implementations
Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker Source code for ACL-IJCNLP 2021 Long paper: Document-le
 84 Dec 15, 2022
84 Dec 15, 2022
RCT-ART is an NLP pipeline built with spaCy for converting clinical trial result sentences into tables through jointly extracting intervention, outcome and outcome measure entities and their relations.
Randomised controlled trial abstract result tabulator RCT-ART is an NLP pipeline built with spaCy for converting clinical trial result sentences into
 2 Sep 16, 2022
2 Sep 16, 2022

NLP tool to extract emotional phrase from tweets 🤩
Emotional phrase extractor Extract phrase in the given text that is used to express the sentiment. Capturing sentiment in language is important in the
 38 Oct 17, 2022
38 Oct 17, 2022
Continuously update some NLP practice based on different tasks.
NLP_practice We will continuously update some NLP practice based on different tasks. prerequisites Software pytorch = 1.10 torchtext = 0.11.0 sklear
 0 Jan 5, 2022
0 Jan 5, 2022

State-of-the-art NLP through transformer models in a modular design and consistent APIs.
Trapper (Transformers wRAPPER) Trapper is an NLP library that aims to make it easier to train transformer based models on downstream tasks. It wraps h
 42 Sep 21, 2022
42 Sep 21, 2022
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
922 Dec 10, 2021
This is a project of data parallel that running on NLP tasks.
This is a project of data parallel that running on NLP tasks.
 2 Dec 12, 2021
2 Dec 12, 2021

Hashformers is a framework for hashtag segmentation with transformers.
Hashtag segmentation is the task of automatically inserting the missing spaces between the words in a hashtag. Hashformers applies Transformer models
 41 Nov 9, 2022
41 Nov 9, 2022
Suite of 500 procedurally-generated NLP tasks to study language model adaptability
TaskBench500 The TaskBench500 dataset and code for generating tasks. Data The TaskBench dataset is available under wget http://web.mit.edu/bzl/www/Tas
 20 May 17, 2022
20 May 17, 2022
Suite of 500 procedurally-generated NLP tasks to study language model adaptability
TaskBench500 The TaskBench500 dataset and code for generating tasks. Data The TaskBench dataset is available under wget http://web.mit.edu/bzl/www/Tas
20 May 17, 2022
This repository contains Python scripts for extracting linguistic features from Filipino texts.
Filipino Text Linguistic Feature Extractors This repository contains scripts for extracting linguistic features from Filipino texts. The scripts were
 1 Oct 5, 2021
1 Oct 5, 2021
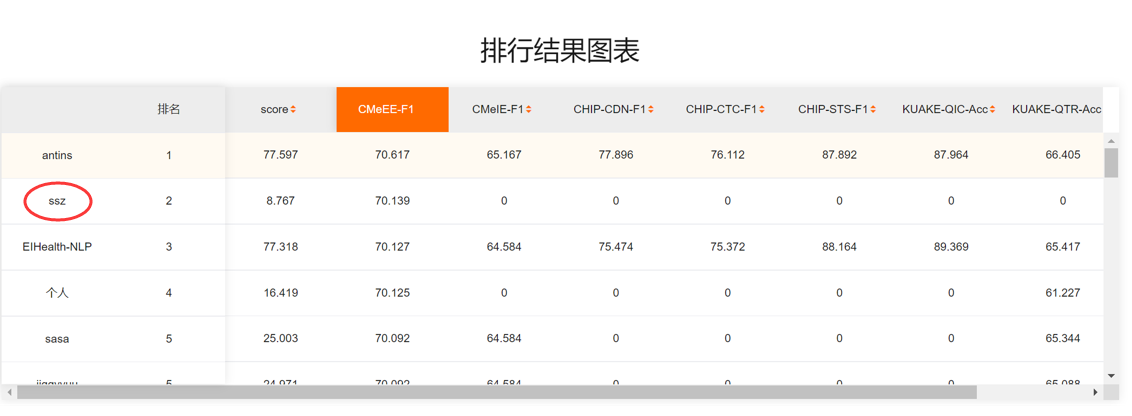
Nested Named Entity Recognition for Chinese Biomedical Text
CBio-NAMER CBioNAMER (Nested nAMed Entity Recognition for Chinese Biomedical Text) is our method used in CBLUE (Chinese Biomedical Language Understand
 8 Dec 25, 2022
8 Dec 25, 2022
Chatbot in 200 lines of code using TensorLayer
Seq2Seq Chatbot This is a 200 lines implementation of Twitter/Cornell-Movie Chatbot, please read the following references before you read the code: Pr
 820 Dec 17, 2022
820 Dec 17, 2022
End-To-End Memory Network using Tensorflow
MemN2N Implementation of End-To-End Memory Networks with sklearn-like interface using Tensorflow. Tasks are from the bAbl dataset. Get Started git clo
 339 Oct 27, 2022
339 Oct 27, 2022

Tensorflow implementation of Character-Aware Neural Language Models.
Character-Aware Neural Language Models Tensorflow implementation of Character-Aware Neural Language Models. The original code of author can be found h
 751 Dec 26, 2022
751 Dec 26, 2022
A design of MIDI language for music generation task, specifically for Natural Language Processing (NLP) models.
MIDI Language Introduction Reference Paper: Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions: code This
 3 May 25, 2022
3 May 25, 2022
Course project of NLP@UCAS
NaiveMT Prepare Clone this repository git clone [email protected]:Poeroz/NaiveMT.git Install Please first install PyTorch = 1.5.0, then type the followi
 2 Apr 24, 2022
2 Apr 24, 2022
Simple bots or Simbots is a library designed to create simple bots using the power of python. This library utilises Intent, Entity, Relation and Context model to create bots .
Simple bots or Simbots is a library designed to create simple chat bots using the power of python. This library utilises Intent, Entity, Relation and
 14 Dec 15, 2021
14 Dec 15, 2021
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022
An assignment from my grad-level data mining course demonstrating some experience with NLP/neural networks/Pytorch
NLP-Pytorch-Assignment An assignment from my grad-level data mining course (before I started personal projects) demonstrating some experience with NLP
 0 Feb 6, 2022
0 Feb 6, 2022

Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU
GPU Docker NLP Application Deployment Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU, to setup the enviroment on
 9 Oct 14, 2022
9 Oct 14, 2022
100+ Chinese Word Vectors 上百种预训练中文词向量
Chinese Word Vectors 中文词向量 中文 This project provides 100+ Chinese Word Vectors (embeddings) trained with different representations (dense and sparse),
 10.4k Jan 9, 2023
10.4k Jan 9, 2023
Natural Language Processing Tasks and Examples.
Natural Language Processing Tasks and Examples With the advancement of A.I. technology in recent years, natural language processing technology has bee
 53 Dec 20, 2022
53 Dec 20, 2022
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022

This is a project built for FALLABOUT2021 event under SRMMIC, This project deals with NLP poetry generation.
FALLABOUT-SRMMIC 21 POETRY-GENERATION HINGLISH DESCRIPTION We have developed a NLP(natural language processing) model which automatically generates a
 7 Sep 28, 2021
7 Sep 28, 2021

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
463 Dec 30, 2022

SentAugment is a data augmentation technique for semi-supervised learning in NLP.
SentAugment SentAugment is a data augmentation technique for semi-supervised learning in NLP. It uses state-of-the-art sentence embeddings to structur
 363 Dec 30, 2022
363 Dec 30, 2022
Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph",
K-BERT Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph", which is implemented based on the UER framework. R
 834 Jan 9, 2023
834 Jan 9, 2023

Modified GPT using average pooling to reduce the softmax attention memory constraints.
NLP-GPT-Upsampling This repository contains an implementation of Open AI's GPT Model. In particular, this implementation takes inspiration from the Ny
 1 Dec 3, 2021
1 Dec 3, 2021
Code for Editing Factual Knowledge in Language Models
KnowledgeEditor Code for Editing Factual Knowledge in Language Models (https://arxiv.org/abs/2104.08164). @inproceedings{decao2021editing, title={Ed
 86 Nov 28, 2022
86 Nov 28, 2022
Code for the paper "Are Sixteen Heads Really Better than One?"
Are Sixteen Heads Really Better than One? This repository contains code to reproduce the experiments in our paper Are Sixteen Heads Really Better than
 143 Dec 14, 2022
143 Dec 14, 2022

The official implementation of "BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies?, ACL 2021 main conference"
BERT is to NLP what AlexNet is to CV This is the official implementation of BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Iden
 20 Nov 3, 2022
20 Nov 3, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
2.1k Dec 28, 2022
Research code for "What to Pre-Train on? Efficient Intermediate Task Selection", EMNLP 2021
efficient-task-transfer This repository contains code for the experiments in our paper "What to Pre-Train on? Efficient Intermediate Task Selection".
 26 Dec 24, 2022
26 Dec 24, 2022
Adapter-BERT: Parameter-Efficient Transfer Learning for NLP.
Adapter-BERT: Parameter-Efficient Transfer Learning for NLP.
340 Jan 3, 2023
This repository contains the code for "Exploiting Cloze Questions for Few-Shot Text Classification and Natural Language Inference"
Pattern-Exploiting Training (PET) This repository contains the code for Exploiting Cloze Questions for Few-Shot Text Classification and Natural Langua
 1.4k Dec 30, 2022
1.4k Dec 30, 2022
EasyTransfer is designed to make the development of transfer learning in NLP applications easier.
EasyTransfer is designed to make the development of transfer learning in NLP applications easier. The literature has witnessed the success of applying
819 Jan 3, 2023

Dataset for the Research2Clinics @ NeurIPS 2021 Paper: What Do You See in this Patient? Behavioral Testing of Clinical NLP Models
Behavioral Testing of Clinical NLP Models This repository contains code for testing the behavior of clinical prediction models based on patient letter
 2 Sep 20, 2022
2 Sep 20, 2022

Bayesian inference for Permuton-induced Chinese Restaurant Process (NeurIPS2021).
Permuton-induced Chinese Restaurant Process Note: Currently only the Matlab version is available, but a Python version will be available soon! This is
 3 Dec 17, 2022
3 Dec 17, 2022
Behavioral Testing of Clinical NLP Models
Behavioral Testing of Clinical NLP Models This repository contains code for testing the behavior of clinical prediction models based on patient letter
2 Sep 20, 2022
Source Code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chinese Question Matching
Description The source code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chin
 3 Jun 28, 2022
3 Jun 28, 2022
WSDM‘2022: Knowledge Enhanced Sports Game Summarization
Knowledge Enhanced Sports Game Summarization Cooming Soon! :) Data will be released after approval process. Code will be published once the author of
 14 Jul 13, 2022
14 Jul 13, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
Haystack is an open source NLP framework that leverages Transformer models.
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
 2.7k Nov 28, 2021
2.7k Nov 28, 2021
KakaoBrain KoGPT (Korean Generative Pre-trained Transformer)
KoGPT KoGPT (Korean Generative Pre-trained Transformer) https://github.com/kakaobrain/kogpt https://huggingface.co/kakaobrain/kogpt Model Descriptions
 799 Dec 28, 2022
799 Dec 28, 2022

Conversational text Analysis using various NLP techniques
PyConverse Let me try first Installation pip install pyconverse Usage Please try this notebook that demos the core functionalities: basic usage noteb
 158 Dec 25, 2022
158 Dec 25, 2022

A Facebook Messenger Chatbot using NLP
A Facebook Messenger Chatbot using NLP This project is about creating a messenger chatbot using basic NLP techniques and models like Logistic Regressi
 6 Nov 20, 2022
6 Nov 20, 2022
Package to compute Mauve, a similarity score between neural text and human text. Install with `pip install mauve-text`.
MAUVE MAUVE is a library built on PyTorch and HuggingFace Transformers to measure the gap between neural text and human text with the eponymous MAUVE
 182 Jan 2, 2023
182 Jan 2, 2023

Make differentially private training of transformers easy for everyone
private-transformers This codebase facilitates fast experimentation of differentially private training of Hugging Face transformers. What is this? Why
 73 Dec 28, 2022
73 Dec 28, 2022

A curated list of awesome papers for Semantic Retrieval (TOIS Accepted: Semantic Models for the First-stage Retrieval: A Comprehensive Review).
A curated list of awesome papers for Semantic Retrieval (TOIS Accepted: Semantic Models for the First-stage Retrieval: A Comprehensive Review).
 189 Dec 28, 2022
189 Dec 28, 2022

Automated question generation and question answering from Turkish texts using text-to-text transformers
Turkish Question Generation Offical source code for "Automated question generation & question answering from Turkish texts using text-to-text transfor
29 Dec 14, 2022
🧪 Cutting-edge experimental spaCy components and features
spacy-experimental: Cutting-edge experimental spaCy components and features This package includes experimental components and features for spaCy v3.x,
 65 Dec 30, 2022
65 Dec 30, 2022
An easy to use Natural Language Processing library and framework for predicting, training, fine-tuning, and serving up state-of-the-art NLP models.
Welcome to AdaptNLP A high level framework and library for running, training, and deploying state-of-the-art Natural Language Processing (NLP) models
 407 Jan 3, 2023
407 Jan 3, 2023
State of the art faster Natural Language Processing in Tensorflow 2.0 .
tf-transformers: faster and easier state-of-the-art NLP in TensorFlow 2.0 ****************************************************************************
 74 Dec 5, 2022
74 Dec 5, 2022
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows.
An open-source, low-code machine learning library in Python 🚀 Version 2.3.5 out now! Check out the release notes here. Official • Docs • Install • Tu
 6.7k Jan 8, 2023
6.7k Jan 8, 2023
A fast, efficient universal vector embedding utility package.
Magnitude: a fast, simple vector embedding utility library A feature-packed Python package and vector storage file format for utilizing vector embeddi
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Repo for the paper "DiLBERT: Cheap Embeddings for Disease Related Medical NLP"
DiLBERT Repo for the paper "DiLBERT: Cheap Embeddings for Disease Related Medical NLP" Pretrained Model The pretrained model presented in the paper is
 2 Dec 15, 2022
2 Dec 15, 2022

Backprop makes it simple to use, finetune, and deploy state-of-the-art ML models.
Backprop makes it simple to use, finetune, and deploy state-of-the-art ML models. Solve a variety of tasks with pre-trained models or finetune them in
 227 Dec 10, 2022
227 Dec 10, 2022
An Unsupervised Detection Framework for Chinese Jargons in the Darknet
An Unsupervised Detection Framework for Chinese Jargons in the Darknet This repo is the Python 3 implementation of 《An Unsupervised Detection Framewor
 7 Nov 8, 2022
7 Nov 8, 2022
Stanza: A Python NLP Library for Many Human Languages
Official Stanford NLP Python Library for Many Human Languages
 5.8k Nov 22, 2021
5.8k Nov 22, 2021
Utilities for preprocessing text for deep learning with Keras
Note: This utility is really old and is no longer maintained. You should use keras.layers.TextVectorization instead of this. Utilities for pre-process
 180 Dec 9, 2022
180 Dec 9, 2022
How to use TensorLayer
How to use TensorLayer While research in Deep Learning continues to improve the world, we use a bunch of tricks to implement algorithms with TensorLay
 349 Dec 7, 2022
349 Dec 7, 2022

Predicting the usefulness of reviews given the review text and metadata surrounding the reviews.
Predicting Yelp Review Quality Table of Contents Introduction Motivation Goal and Central Questions The Data Data Storage and ETL EDA Data Pipeline Da
 3 Nov 27, 2022
3 Nov 27, 2022
Multiple implementations for abstractive text summurization , using google colab
Text Summarization models if you are able to endorse me on Arxiv, i would be more than glad https://arxiv.org/auth/endorse?x=FRBB89 thanks This repo i
 463 Dec 26, 2022
463 Dec 26, 2022
NLP and Text Generation Experiments in TensorFlow 2.x / 1.x
Code has been run on Google Colab, thanks Google for providing computational resources Contents Natural Language Processing(自然语言处理) Text Classificati
 1.5k Nov 14, 2022
1.5k Nov 14, 2022
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Introduction XLNet is a new unsupervised language representation learning method based on a novel generalized permutation language modeling objective.
 6k Jan 7, 2023
6k Jan 7, 2023
TensorFlow code and pre-trained models for BERT
BERT ***** New March 11th, 2020: Smaller BERT Models ***** This is a release of 24 smaller BERT models (English only, uncased, trained with WordPiece
32.9k Jan 8, 2023
Deep learning for NLP crash course at ABBYY.
Deep NLP Course at ABBYY Deep learning for NLP crash course at ABBYY. Suggested textbook: Neural Network Methods in Natural Language Processing by Yoa
 597 Dec 18, 2022
597 Dec 18, 2022
nlp-tutorial is a tutorial for who is studying NLP(Natural Language Processing) using Pytorch
nlp-tutorial is a tutorial for who is studying NLP(Natural Language Processing) using Pytorch. Most of the models in NLP were implemented with less than 100 lines of code.(except comments or blank lines)
 11.9k Jan 8, 2023
11.9k Jan 8, 2023

Biterm Topic Model (BTM): modeling topics in short texts
Biterm Topic Model Bitermplus implements Biterm topic model for short texts introduced by Xiaohui Yan, Jiafeng Guo, Yanyan Lan, and Xueqi Cheng. Actua
 49 Dec 30, 2022
49 Dec 30, 2022

Binary LSTM model for text classification
Text Classification The purpose of this repository is to create a neural network model of NLP with deep learning for binary classification of texts re
 1 Mar 11, 2022
1 Mar 11, 2022
AI-powered literature discovery and review engine for medical/scientific papers
AI-powered literature discovery and review engine for medical/scientific papers paperai is an AI-powered literature discovery and review engine for me
 819 Dec 30, 2022
819 Dec 30, 2022
topic modeling on unstructured data in Space news articles retrieved from the Guardian (UK) newspaper using API
NLP Space News Topic Modeling Photos by nasa.gov (1, 2, 3, 4, 5) and extremetech.com Table of Contents Project Idea Data acquisition Primary data sour
 1 Jan 3, 2022
1 Jan 3, 2022
Conversational text Analysis using various NLP techniques
Conversational text Analysis using various NLP techniques
159 Jan 6, 2023
Politecnico of Turin Thesis: "Implementation and Evaluation of an Educational Chatbot based on NLP Techniques"
THESIS_CAIRONE_FIORENTINO Politecnico of Turin Thesis: "Implementation and Evaluation of an Educational Chatbot based on NLP Techniques" GENERATE TOKE
 1 Dec 10, 2021
1 Dec 10, 2021
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
1.4k Jan 4, 2023
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 A repository part of the MarIA project. Corpora 📃 Corpora Number of documents Number of tokens Size (GB) BNE 201,080,084
 203 Dec 20, 2022
203 Dec 20, 2022
Maha is a text processing library specially developed to deal with Arabic text.
An Arabic text processing library intended for use in NLP applications Maha is a text processing library specially developed to deal with Arabic text.
 184 Nov 27, 2022
184 Nov 27, 2022

A demo of chinese asr
chinese_asr_demo 一个端到端的中文语音识别模型训练、测试框架 具备数据预处理、模型训练、解码、计算wer等等功能 训练数据 训练数据采用thchs_30,
 4 Dec 9, 2021
4 Dec 9, 2021
Code for training and evaluation of the model from "Language Generation with Recurrent Generative Adversarial Networks without Pre-training"
Language Generation with Recurrent Generative Adversarial Networks without Pre-training Code for training and evaluation of the model from "Language G
 253 Sep 14, 2022
253 Sep 14, 2022

Learning Chinese Character style with conditional GAN
zi2zi: Master Chinese Calligraphy with Conditional Adversarial Networks Introduction Learning eastern asian language typefaces with GAN. zi2zi(字到字, me
 2.2k Jan 2, 2023
2.2k Jan 2, 2023

🛠️ Tools for Transformers compression using Lightning ⚡
Bert-squeeze is a repository aiming to provide code to reduce the size of Transformer-based models or decrease their latency at inference time.
 66 Dec 11, 2022
66 Dec 11, 2022