155 Repositories
Python cqa-evaluation Libraries

Open-Source CI/CD platform for ML teams. Deliver ML products, better & faster. ⚡️🧑🔧
Deliver ML products, better & faster Giskard is an Open-Source CI/CD platform for ML teams. Inspect ML models visually from your Python notebook 📗 Re
 335 Jan 4, 2023
335 Jan 4, 2023

KwaiRec: A Fully-observed Dataset for Recommender Systems (Density: Almost 100%)
KuaiRec: A Fully-observed Dataset for Recommender Systems (Density: Almost 100%) KuaiRec is a real-world dataset collected from the recommendation log
 70 Dec 28, 2022
70 Dec 28, 2022

Evaluation and Benchmarking of Speech Super-resolution Methods
Speech Super-resolution Evaluation and Benchmarking What this repo do: A toolbox for the evaluation of speech super-resolution algorithms. Unify the e
 84 Dec 20, 2022
84 Dec 20, 2022
A benchmark for evaluation and comparison of various NLP tasks in Persian language.
Persian NLP Benchmark The repository aims to track existing natural language processing models and evaluate their performance on well-known datasets.
 68 Dec 19, 2022
68 Dec 19, 2022

APEACH: Attacking Pejorative Expressions with Analysis on Crowd-generated Hate Speech Evaluation Datasets
APEACH - Korean Hate Speech Evaluation Datasets APEACH is the first crowd-generated Korean evaluation dataset for hate speech detection. Sentences of
 70 Dec 6, 2022
70 Dec 6, 2022
Provide baselines and evaluation metrics of the task: traffic flow prediction
Note: This repo is adpoted from https://github.com/UNIMIBInside/Smart-Mobility-Prediction. Due to technical reasons, I did not fork their code. Introd
 11 Nov 2, 2022
11 Nov 2, 2022
Object detection evaluation metrics using Python.
Object detection evaluation metrics using Python.
 2 Sep 6, 2022
2 Sep 6, 2022

DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
 36 Feb 13, 2022
36 Feb 13, 2022
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
98 Dec 15, 2022
Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model
Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model About This repository contains the code to replicate the syn
 12 Dec 7, 2022
12 Dec 7, 2022
Image-based Navigation in Real-World Environments via Multiple Mid-level Representations: Fusion Models Benchmark and Efficient Evaluation
Image-based Navigation in Real-World Environments via Multiple Mid-level Representations: Fusion Models Benchmark and Efficient Evaluation This reposi
 1 Aug 21, 2022
1 Aug 21, 2022
Evaluation framework for testing segmentation networks in PyTorch
Evaluation framework for testing segmentation networks in PyTorch. What segmentation network to choose for next Kaggle competition? This benchmark knows the answer!
 37 Apr 27, 2022
37 Apr 27, 2022

This is the repository for our paper Ditch the Gold Standard: Re-evaluating Conversational Question Answering
Ditch the Gold Standard: Re-evaluating Conversational Question Answering This is the repository for our paper Ditch the Gold Standard: Re-evaluating C
 38 Dec 16, 2022
38 Dec 16, 2022
FAIR Enough Metrics is an API for various FAIR Metrics Tests, written in python
☑️ FAIR Enough metrics for research FAIR Enough Metrics is an API for various FAIR Metrics Tests, written in python, conforming to the specifications
 3 Jul 6, 2022
3 Jul 6, 2022
SuRE Evaluation: A Supplementary Material
SuRE Evaluation: A Supplementary Material This repository contains supplementary material regarding the evaluations presented in the paper Visual Expl
 0 Dec 14, 2021
0 Dec 14, 2021
The open-source and free to use Python package miseval was developed to establish a standardized medical image segmentation evaluation procedure
miseval: a metric library for Medical Image Segmentation EVALuation The open-source and free to use Python package miseval was developed to establish
 59 Dec 10, 2022
59 Dec 10, 2022
Official repository for the paper "On Evaluation Metrics for Graph Generative Models"
On Evaluation Metrics for Graph Generative Models Authors: Rylee Thompson, Boris Knyazev, Elahe Ghalebi, Jungtaek Kim, Graham Taylor This is the offic
 5 Jan 26, 2022
5 Jan 26, 2022
This repository contains pre-trained models and some evaluation code for our paper Towards Unsupervised Dense Information Retrieval with Contrastive Learning
Contriever: Towards Unsupervised Dense Information Retrieval with Contrastive Learning This repository contains pre-trained models and some evaluation
 207 Jan 8, 2023
207 Jan 8, 2023
Image Segmentation Evaluation
Image Segmentation Evaluation Martin Keršner, [email protected] Evaluation metrics for image segmentation inspired by paper Fully Convolutional Netw
 273 Oct 28, 2022
273 Oct 28, 2022
On Evaluation Metrics for Graph Generative Models
On Evaluation Metrics for Graph Generative Models Authors: Rylee Thompson, Boris Knyazev, Elahe Ghalebi, Jungtaek Kim, Graham Taylor This is the offic
13 Jan 7, 2023

Project made in Qt Designer + Python, for evaluation in the subject Introduction to Programming in IFPE - Paulista campus.
Project made in Qt Designer + Python, for evaluation in the subject Introduction to Programming in IFPE - Paulista campus.
 2 Apr 13, 2022
2 Apr 13, 2022

NLG evaluation via Statistical Measures of Similarity: BaryScore, DepthScore, InfoLM
NLG evaluation via Statistical Measures of Similarity: BaryScore, DepthScore, InfoLM Automatic Evaluation Metric described in the papers BaryScore (EM
 28 Dec 28, 2022
28 Dec 28, 2022
PyTorch code for the NAACL 2021 paper "Improving Generation and Evaluation of Visual Stories via Semantic Consistency"
Improving Generation and Evaluation of Visual Stories via Semantic Consistency PyTorch code for the NAACL 2021 paper "Improving Generation and Evaluat
 28 Dec 8, 2022
28 Dec 8, 2022
An Evaluation of Generative Adversarial Networks for Collaborative Filtering.
An Evaluation of Generative Adversarial Networks for Collaborative Filtering. This repository was developed by Fernando B. Pérez Maurera. Fernando is
 0 Jan 19, 2022
0 Jan 19, 2022
The Turing Change Point Detection Benchmark: An Extensive Benchmark Evaluation of Change Point Detection Algorithms on real-world data
Turing Change Point Detection Benchmark Welcome to the repository for the Turing Change Point Detection Benchmark, a benchmark evaluation of change po
 85 Dec 28, 2022
85 Dec 28, 2022
General Assembly's 2015 Data Science course in Washington, DC
DAT8 Course Repository Course materials for General Assembly's Data Science course in Washington, DC (8/18/15 - 10/29/15). Instructor: Kevin Markham (
 1.6k Jan 7, 2023
1.6k Jan 7, 2023

Automatic caption evaluation metric based on typicality analysis.
SeMantic and linguistic UndeRstanding Fusion (SMURF) Automatic caption evaluation metric described in the paper "SMURF: SeMantic and linguistic UndeRs
 6 Jan 9, 2022
6 Jan 9, 2022
Text Summarization - WCN — Weighted Contextual N-gram method for evaluation of Text Summarization
Text Summarization WCN — Weighted Contextual N-gram method for evaluation of Text Summarization In this project, I fine tune T5 model on Extreme Summa
 1 Jan 3, 2022
1 Jan 3, 2022
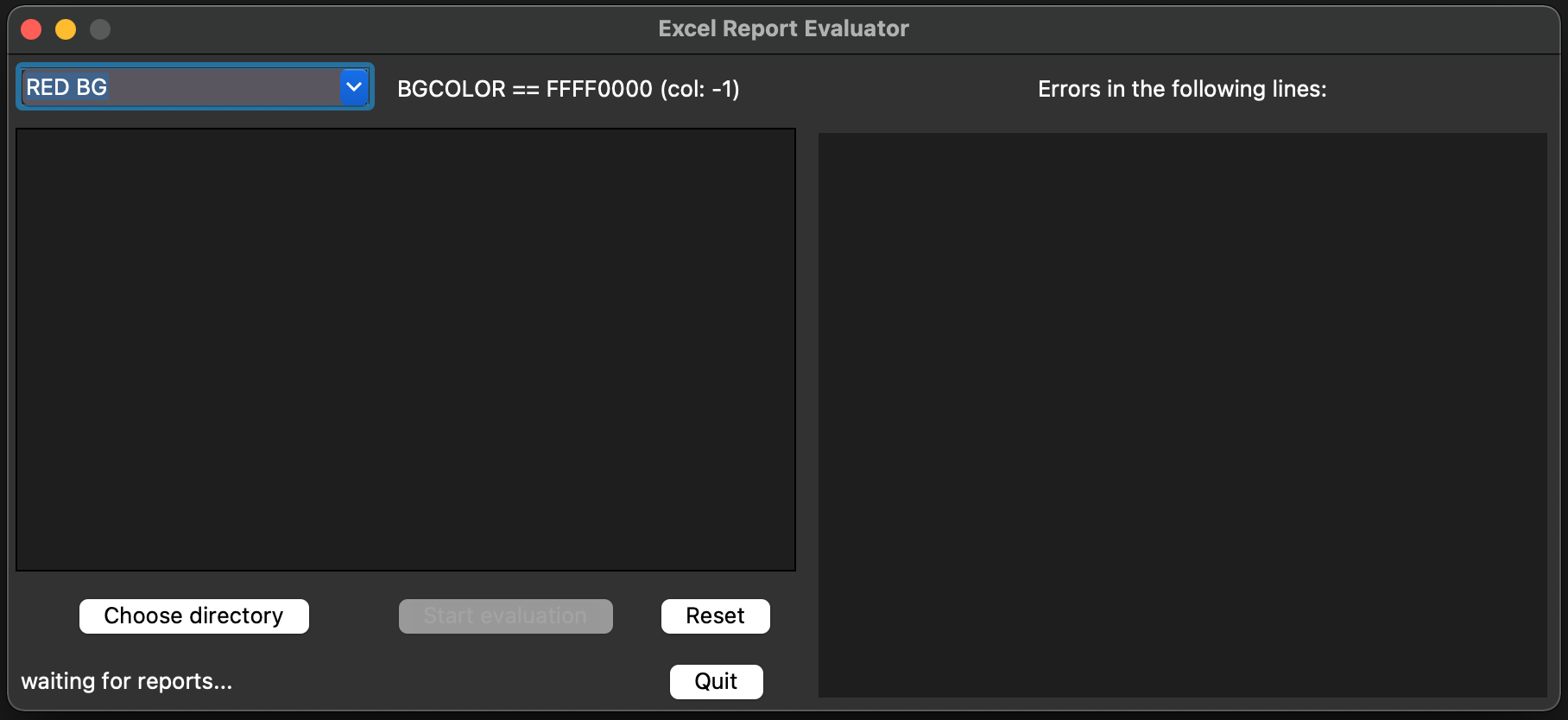
Excel-report-evaluator - A simple Python GUI application to aid with bulk evaluation of Microsoft Excel reports.
Excel Report Evaluator Simple Python GUI with Tkinter for evaluating Microsoft Excel reports (.xlsx-Files). Usage Start main.py and choose one of the
 1 Dec 29, 2021
1 Dec 29, 2021
Image Matching Evaluation
Image Matching Evaluation (IME) IME provides to test any feature matching algorithm on datasets containing ground-truth homographies. Also, one can re
 32 Nov 17, 2022
32 Nov 17, 2022

An efficient PyTorch implementation of the evaluation metrics in recommender systems.
recsys_metrics An efficient PyTorch implementation of the evaluation metrics in recommender systems. Overview • Installation • How to use • Benchmark
 12 Dec 2, 2022
12 Dec 2, 2022
GCRC: A Gaokao Chinese Reading Comprehension dataset for interpretable Evaluation
GCRC GCRC: A New Challenging MRC Dataset from Gaokao Chinese for Explainable Eva
 5 Nov 4, 2022
5 Nov 4, 2022
Place holder for HOPE: a human-centric and task-oriented MT evaluation framework using professional post-editing
HOPE: A Task-Oriented and Human-Centric Evaluation Framework Using Professional Post-Editing Towards More Effective MT Evaluation Place holder for dat
 1 Apr 25, 2022
1 Apr 25, 2022
Modeval (or Modular Eval) is a modular and secure string evaluation library that can be used to create custom parsers or interpreters.
modeval Modeval (or Modular Eval) is a modular and secure string evaluation library that can be used to create custom parsers or interpreters. Basic U
 2 Jan 1, 2022
2 Jan 1, 2022
Modeval (or Modular Eval) is a modular and secure string evaluation library that can be used to create custom parsers or interpreters.
modeval Modeval (or Modular Eval) is a modular and secure string evaluation library that can be used to create custom parsers or interpreters. Basic U
2 Jan 1, 2022
Latte: Cross-framework Python Package for Evaluation of Latent-based Generative Models
Cross-framework Python Package for Evaluation of Latent-based Generative Models Latte Latte (for LATent Tensor Evaluation) is a cross-framework Python
 30 Sep 8, 2022
30 Sep 8, 2022

Evaluation toolkit of the informative tracking benchmark comprising 9 scenarios, 180 diverse videos, and new challenges.
Informative-tracking-benchmark Informative tracking benchmark (ITB) higher diversity. It contains 9 representative scenarios and 180 diverse videos. m
 15 Nov 26, 2022
15 Nov 26, 2022
Implementation for paper BLEU: a Method for Automatic Evaluation of Machine Translation
BLEU Score Implementation for paper: BLEU: a Method for Automatic Evaluation of Machine Translation Author: Ba Ngoc from ProtonX BLEU score is a popul
 6 Oct 7, 2021
6 Oct 7, 2021
Evaluation of file formats in the context of geo-referenced 3D geometries.
Geo-referenced Geometry File Formats Classic geometry file formats as .obj, .off, .ply, .stl or .dae do not support the utilization of coordinate syst
 11 Mar 2, 2022
11 Mar 2, 2022

Training and Evaluation Code for Neural Volumes
Neural Volumes This repository contains training and evaluation code for the paper Neural Volumes. The method learns a 3D volumetric representation of
370 Dec 8, 2022

The RDT protocol (RDT3.0,GBN,SR) implementation and performance evaluation code using socket
소켓을 이용한 RDT protocols (RDT3.0,GBN,SR) 구현 및 성능 평가 코드 입니다. 코드를 실행할때 리시버를 먼저 실행하세요. 성능 평가 코드는 패킷 전송 과정을 제외하고 시간당 전송률을 출력합니다. RDT3.0 GBN SR(버그 발견으로 구현중 입니
 0 Dec 20, 2021
0 Dec 20, 2021
Evaluation toolkit of the informative tracking benchmark comprising 9 scenarios, 180 diverse videos, and new challenges.
Informative-tracking-benchmark Informative tracking benchmark (ITB) higher diversity. It contains 9 representative scenarios and 180 diverse videos. m
15 Nov 26, 2022
A PyTorch library and evaluation platform for end-to-end compression research
CompressAI CompressAI (compress-ay) is a PyTorch library and evaluation platform for end-to-end compression research. CompressAI currently provides: c
 680 Jan 6, 2023
680 Jan 6, 2023

Atari2600 Training / Evaluation with RLlib
Training Atari2600 by Reinforcement Learning Train Atari2600 and check how it works! How to Setup You can setup packages on your local env. $ make set
 1 Dec 12, 2021
1 Dec 12, 2021
Official implementation of the paper "Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering"
Light Field Networks Project Page | Paper | Data | Pretrained Models Vincent Sitzmann*, Semon Rezchikov*, William Freeman, Joshua Tenenbaum, Frédo Dur
 130 Dec 29, 2022
130 Dec 29, 2022
HDMapNet: A Local Semantic Map Learning and Evaluation Framework
HDMapNet_devkit Devkit for HDMapNet. HDMapNet: A Local Semantic Map Learning and Evaluation Framework Qi Li, Yue Wang, Yilun Wang, Hang Zhao [Paper] [
 421 Jan 4, 2023
421 Jan 4, 2023

Machine learning model evaluation made easy: plots, tables, HTML reports, experiment tracking and Jupyter notebook analysis.
sklearn-evaluation Machine learning model evaluation made easy: plots, tables, HTML reports, experiment tracking, and Jupyter notebook analysis. Suppo
 354 Dec 31, 2022
354 Dec 31, 2022
Team collaborative evaluation tracker.
Team collaborative evaluation tracker.
 2 Dec 19, 2021
2 Dec 19, 2021
TextWorld is a sandbox learning environment for the training and evaluation of reinforcement learning (RL) agents on text-based games.
TextWorld A text-based game generator and extensible sandbox learning environment for training and testing reinforcement learning (RL) agents. Also ch
 983 Dec 23, 2022
983 Dec 23, 2022

Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
 2 Dec 2, 2021
2 Dec 2, 2021

Training and evaluation codes for the BertGen paper (ACL-IJCNLP 2021)
BERTGEN This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codeb
 9 Oct 26, 2022
9 Oct 26, 2022
Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
8 Oct 6, 2022
Official Repository for "Robust On-Policy Data Collection for Data Efficient Policy Evaluation" (NeurIPS 2021 Workshop on OfflineRL).
Robust On-Policy Data Collection for Data-Efficient Policy Evaluation Source code of Robust On-Policy Data Collection for Data-Efficient Policy Evalua
 2 Oct 9, 2022
2 Oct 9, 2022

(NeurIPS 2021) Realistic Evaluation of Transductive Few-Shot Learning
Realistic evaluation of transductive few-shot learning Introduction This repo contains the code for our NeurIPS 2021 submitted paper "Realistic evalua
 14 Dec 13, 2022
14 Dec 13, 2022

Python Single Object Tracking Evaluation
pysot-toolkit The purpose of this repo is to provide evaluation API of Current Single Object Tracking Dataset, including VOT2016 VOT2018 VOT2018-LT OT
 348 Dec 22, 2022
348 Dec 22, 2022

Tightness-aware Evaluation Protocol for Scene Text Detection
TIoU-metric Release on 27/03/2019. This repository is built on the ICDAR 2015 evaluation code. If you propose a better metric and require further eval
 206 Nov 18, 2022
206 Nov 18, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022

Prevent `CUDA error: out of memory` in just 1 line of code.
🐨 Koila Koila solves CUDA error: out of memory error painlessly. Fix it with just one line of code, and forget it. 🚀 Features 🙅 Prevents CUDA error
 1.7k Jan 2, 2023
1.7k Jan 2, 2023
GradAttack is a Python library for easy evaluation of privacy risks in public gradients in Federated Learning
GradAttack is a Python library for easy evaluation of privacy risks in public gradients in Federated Learning, as well as corresponding mitigation strategies.
 129 Dec 30, 2022
129 Dec 30, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

Rethinking of Pedestrian Attribute Recognition: A Reliable Evaluation under Zero-Shot Pedestrian Identity Setting
Pytorch Pedestrian Attribute Recognition: A strong PyTorch baseline of pedestrian attribute recognition and multi-label classification.
 79 Dec 18, 2022
79 Dec 18, 2022

Training code and evaluation benchmarks for the "Self-Supervised Policy Adaptation during Deployment" paper.
Self-Supervised Policy Adaptation during Deployment PyTorch implementation of PAD and evaluation benchmarks from Self-Supervised Policy Adaptation dur
 101 Nov 1, 2022
101 Nov 1, 2022
Semi-Supervised Learning for Fine-Grained Classification
Semi-Supervised Learning for Fine-Grained Classification This repo contains the code of: A Realistic Evaluation of Semi-Supervised Learning for Fine-G
 25 Nov 8, 2022
25 Nov 8, 2022

A Python package for causal inference using Synthetic Controls
Synthetic Control Methods A Python package for causal inference using synthetic controls This Python package implements a class of approaches to estim
 107 Dec 28, 2022
107 Dec 28, 2022
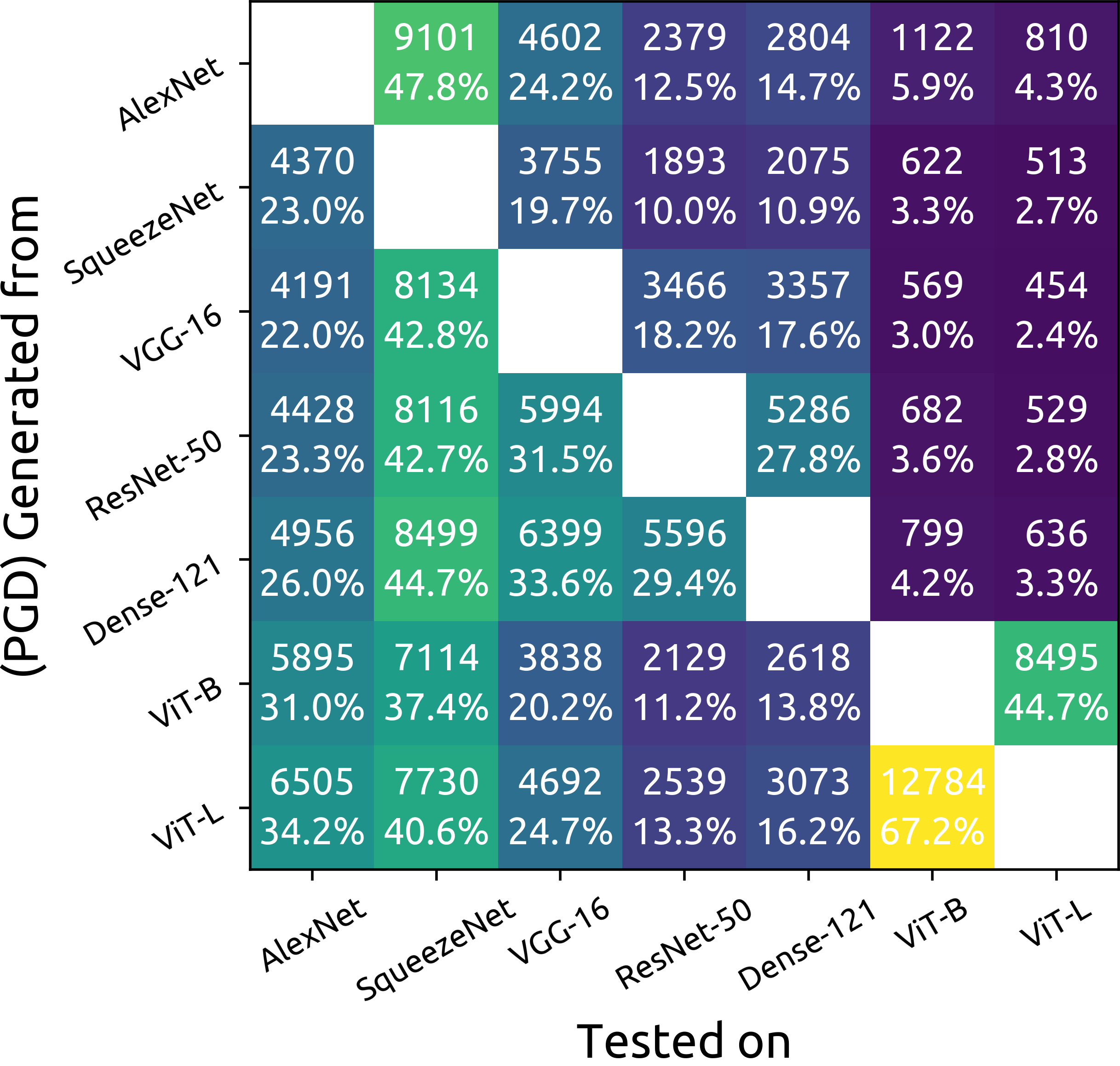
ImageNet Adversarial Image Evaluation
ImageNet Adversarial Image Evaluation This repository contains the code and some materials used in the experimental work presented in the following pa
 11 Dec 26, 2022
11 Dec 26, 2022

Accelerating model creation and evaluation.
EmeraldML A machine learning library for streamlining the process of (1) cleaning and splitting data, (2) training, optimizing, and testing various mo
 0 Dec 6, 2021
0 Dec 6, 2021
Politecnico of Turin Thesis: "Implementation and Evaluation of an Educational Chatbot based on NLP Techniques"
THESIS_CAIRONE_FIORENTINO Politecnico of Turin Thesis: "Implementation and Evaluation of an Educational Chatbot based on NLP Techniques" GENERATE TOKE
 1 Dec 10, 2021
1 Dec 10, 2021

Automatic Video Captioning Evaluation Metric --- EMScore
Automatic Video Captioning Evaluation Metric --- EMScore Overview For an illustration, EMScore can be computed as: Installation modify the encode_text
 17 Nov 28, 2022
17 Nov 28, 2022
Code for training and evaluation of the model from "Language Generation with Recurrent Generative Adversarial Networks without Pre-training"
Language Generation with Recurrent Generative Adversarial Networks without Pre-training Code for training and evaluation of the model from "Language G
 253 Sep 14, 2022
253 Sep 14, 2022
A high performance implementation of HDBSCAN clustering.
HDBSCAN HDBSCAN - Hierarchical Density-Based Spatial Clustering of Applications with Noise. Performs DBSCAN over varying epsilon values and integrates
 2.3k Jan 2, 2023
2.3k Jan 2, 2023
Non-Metric Space Library (NMSLIB): An efficient similarity search library and a toolkit for evaluation of k-NN methods for generic non-metric spaces.
Non-Metric Space Library (NMSLIB) Important Notes NMSLIB is generic but fast, see the results of ANN benchmarks. A standalone implementation of our fa
 2.9k Jan 4, 2023
2.9k Jan 4, 2023
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding This repo contains the data and source code for baseline models in the NeurIPS 2
10 Nov 17, 2021

reXmeX is recommender system evaluation metric library.
A general purpose recommender metrics library for fair evaluation.
 258 Dec 22, 2022
258 Dec 22, 2022

XAI - An eXplainability toolbox for machine learning
XAI - An eXplainability toolbox for machine learning XAI is a Machine Learning library that is designed with AI explainability in its core. XAI contai
 875 Dec 27, 2022
875 Dec 27, 2022
The project covers common metrics for super-resolution performance evaluation.
Super-Resolution Performance Evaluation Code The project covers common metrics for super-resolution performance evaluation. Metrics support The script
 10 Aug 3, 2022
10 Aug 3, 2022
Source code, data, and evaluation details for “Cross-Lingual Citations in English Papers: A Large-Scale Analysis of Prevalence, Formation, and Ramifications”
Analysis of cross-lingual citations in English papers Contents initial_analysis Source code, data, and evaluation details as published at ICADL2020 ci
 1 Oct 27, 2022
1 Oct 27, 2022
Multi-Modal Fingerprint Presentation Attack Detection: Evaluation On A New Dataset
PADISI USC Dataset This repository analyzes the PADISI-Finger dataset introduced in Multi-Modal Fingerprint Presentation Attack Detection: Evaluation
 6 Feb 6, 2022
6 Feb 6, 2022

Security evaluation module with onnx, pytorch, and SecML.
🚀 🐼 🔥 PandaVision Integrate and automate security evaluations with onnx, pytorch, and SecML! Installation Starting the server without Docker If you
 11 Apr 12, 2022
11 Apr 12, 2022
Web Crawlers for Data Labelling of Malicious Domain Detection & IP Reputation Evaluation
Web Crawlers for Data Labelling of Malicious Domain Detection & IP Reputation Evaluation This repository provides two web crawlers to label domain nam
 1 Nov 5, 2021
1 Nov 5, 2021
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding This repo contains the data and source code for baseline models in the NeurIPS 2
29 Dec 29, 2022

Suite of tools for retrieving USGS NWIS observations and evaluating National Water Model (NWM) data.
Documentation OWPHydroTools GitHub pages documentation Motivation We developed OWPHydroTools with data scientists in mind. We attempted to ensure the
 36 Dec 11, 2022
36 Dec 11, 2022
Pipeline and Dataset helpers for complex algorithm evaluation.
tpcp - Tiny Pipelines for Complex Problems A generic way to build object-oriented datasets and algorithm pipelines and tools to evaluate them pip inst
 3 Dec 7, 2022
3 Dec 7, 2022
Installation, test and evaluation of Scribosermo speech-to-text engine
Scribosermo STT Setup Scribosermo is a LGPL licensed, open-source speech recognition engine to "Train fast Speech-to-Text networks in different langua
 3 Jun 20, 2022
3 Jun 20, 2022
A toolkit for geo ML data processing and model evaluation (fork of solaris)
An open source ML toolkit for overhead imagery. This is a beta version of lunular which may continue to develop. Please report any bugs through issues
 4 Nov 4, 2021
4 Nov 4, 2021
Evaluation of TCP BBRv1 in wireless networks
The Network Simulator, Version 3 Table of Contents: An overview Building ns-3 Running ns-3 Getting access to the ns-3 documentation Working with the d
 3 Nov 1, 2021
3 Nov 1, 2021
Facilitating Database Tuning with Hyper-ParameterOptimization: A Comprehensive Experimental Evaluation
A Comprehensive Experimental Evaluation for Database Configuration Tuning This is the source code to the paper "Facilitating Database Tuning with Hype
 9 Oct 29, 2022
9 Oct 29, 2022
Unified MultiWOZ evaluation scripts for the context-to-response task.
MultiWOZ Context-to-Response Evaluation Standardized and easy to use Inform, Success, BLEU ~ See the paper ~ Easy-to-use scripts for standardized eval
 38 Dec 13, 2022
38 Dec 13, 2022
Data, model training, and evaluation code for "PubTables-1M: Towards a universal dataset and metrics for training and evaluating table extraction models".
PubTables-1M This repository contains training and evaluation code for the paper "PubTables-1M: Towards a universal dataset and metrics for training a
365 Jan 4, 2023
This is a five-step framework for the development of intrusion detection systems (IDS) using machine learning (ML) considering model realization, and performance evaluation.
AB-TRAP: building invisibility shields to protect network devices The AB-TRAP framework is applicable to the development of Network Intrusion Detectio
 17 Jan 4, 2023
17 Jan 4, 2023
Federated_learning codes used for the the paper "Evaluation of Federated Learning Aggregation Algorithms" and "A Federated Learning Aggregation Algorithm for Pervasive Computing: Evaluation and Comparison"
Federated Distance (FedDist) This is the code accompanying the Percom2021 paper "A Federated Learning Aggregation Algorithm for Pervasive Computing: E
 8 Jan 3, 2023
8 Jan 3, 2023

Developed a website to analyze and generate report of students based on the curriculum that represents student’s academic performance.
Developed a website to analyze and generate report of students based on the curriculum that represents student’s academic performance. We have developed the system such that, it will automatically parse data onto the database from excel file, which will in return reduce time consumption of analysis of data.
 3 Nov 8, 2022
3 Nov 8, 2022

Source code for "Taming Visually Guided Sound Generation" (Oral at the BMVC 2021)
Taming Visually Guided Sound Generation • [Project Page] • [ArXiv] • [Poster] • • Listen for the samples on our project page. Overview We propose to t
 226 Jan 3, 2023
226 Jan 3, 2023
Anomaly detection in multi-agent trajectories: Code for training, evaluation and the OpenAI highway simulation.
Anomaly Detection in Multi-Agent Trajectories for Automated Driving This is the official project page including the paper, code, simulation, baseline
 12 Dec 2, 2022
12 Dec 2, 2022
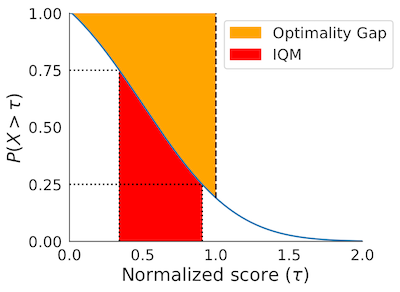
rliable is an open-source Python library for reliable evaluation, even with a handful of runs, on reinforcement learning and machine learnings benchmarks.
Open-source library for reliable evaluation on reinforcement learning and machine learning benchmarks. See NeurIPS 2021 oral for details.
 529 Jan 1, 2023
529 Jan 1, 2023

Evaluation of a Monocular Eye Tracking Set-Up
Evaluation of a Monocular Eye Tracking Set-Up As part of my master thesis, I implemented a new state-of-the-art model that is based on the work of Che
 19 Dec 17, 2022
19 Dec 17, 2022

A fast implementation of bss_eval metrics for blind source separation
fast_bss_eval Do you have a zillion BSS audio files to process and it is taking days ? Is your simulation never ending ? Fear no more! fast_bss_eval i
 99 Dec 13, 2022
99 Dec 13, 2022
ImageNet-CoG is a benchmark for concept generalization. It provides a full evaluation framework for pre-trained visual representations which measure how well they generalize to unseen concepts.
The ImageNet-CoG Benchmark Project Website Paper (arXiv) Code repository for the ImageNet-CoG Benchmark introduced in the paper "Concept Generalizatio
 23 Oct 9, 2022
23 Oct 9, 2022
fast_bss_eval is a fast implementation of the bss_eval metrics for the evaluation of blind source separation.
fast_bss_eval Do you have a zillion BSS audio files to process and it is taking days ? Is your simulation never ending ? Fear no more! fast_bss_eval i
99 Dec 13, 2022

Supplementary materials for ISMIR 2021 LBD paper "Evaluation of Latent Space Disentanglement in the Presence of Interdependent Attributes"
Evaluation of Latent Space Disentanglement in the Presence of Interdependent Attributes Supplementary materials for ISMIR 2021 LBD submission: K. N. W
2 Oct 25, 2021
Implementation of temporal pooling methods studied in [ICIP'20] A Comparative Evaluation Of Temporal Pooling Methods For Blind Video Quality Assessment
Implementation of temporal pooling methods studied in [ICIP'20] A Comparative Evaluation Of Temporal Pooling Methods For Blind Video Quality Assessment
 5 Sep 16, 2022
5 Sep 16, 2022