1394 Repositories
Python deduplicate-text-datasets Libraries

The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding.
SuperGen The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. Requirements Before running, you
 38 Dec 12, 2022
38 Dec 12, 2022

The pyrelational package offers a flexible workflow to enable active learning with as little change to the models and datasets as possible
pyrelational is a python active learning library developed by Relation Therapeutics for rapidly implementing active learning pipelines from data management, model development (and Bayesian approximation), to creating novel active learning strategies.
 95 Dec 27, 2022
95 Dec 27, 2022

I³ Tracker for Essential Open Innovation Datasets
I³ Tracker for Essential Open Innovation Datasets This repository is set up to track, version, and contribute updates to the I³ Essential Open Innovat
 1 Feb 8, 2022
1 Feb 8, 2022

BCI datasets and algorithms
Brainda Welcome! First and foremost, Welcome! Thank you for visiting the Brainda repository which was initially released at this repo and reorganized
 52 Jan 4, 2023
52 Jan 4, 2023

Complete* list of autonomous driving related datasets
AD Datasets Complete* and curated list of autonomous driving related datasets Contributing Contributions are very welcome! To add or update a dataset:
 13 Dec 19, 2022
13 Dec 19, 2022
L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources.
L3Cube-MahaCorpus L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources. We expand the existing Marathi monolingual
 21 Dec 17, 2022
21 Dec 17, 2022
To classify the News into Real/Fake using Features from the Text Content of the article
Hoax-Detector Authenticity of news has now become a major problem. The Idea is to classify the News into Real/Fake using Features from the Text Conten
 1 Feb 9, 2022
1 Feb 9, 2022
Transformers provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 50 Nov 12, 2022
50 Nov 12, 2022

Pytorch implementation of TailCalibX : Feature Generation for Long-tail Classification
TailCalibX : Feature Generation for Long-tail Classification by Rahul Vigneswaran, Marc T. Law, Vineeth N. Balasubramanian, Makarand Tapaswi [arXiv] [
 34 Jan 2, 2023
34 Jan 2, 2023

Temporal Dynamic Convolutional Neural Network for Text-Independent Speaker Verification and Phonemetic Analysis
TDY-CNN for Text-Independent Speaker Verification Official implementation of Temporal Dynamic Convolutional Neural Network for Text-Independent Speake
 16 Oct 17, 2022
16 Oct 17, 2022
This code is the implementation of Text Emotion Recognition (TER) with linguistic features
APSIPA-TER This code is the implementation of Text Emotion Recognition (TER) with linguistic features. The network model is BERT with a pretrained mod
 1 Feb 8, 2022
1 Feb 8, 2022
Text Analysis & Topic Extraction on Android App user reviews
AndroidApp_TextAnalysis Hi, there! This is code archive for Text Analysis and Topic Extraction from user_reviews of Android App. Dataset Source : http
 1 Feb 14, 2022
1 Feb 14, 2022
Text Normalization(文本正则化)
Text Normalization(文本正则化) 任务描述:通过机器学习算法将英文文本的“手写”形式转换成“口语“形式,例如“6ft”转换成“six feet”等 实验结果 XGBoost + bag-of-words: 0.99159 XGBoost+Weights+rules:0.99002
 0 Feb 26, 2022
0 Feb 26, 2022
Estimation of the CEFR complexity score of a given word, sentence or text.
NLP-Swedish … allows to estimate CEFR (Common European Framework of References) complexity score of a given word, sentence or text. CEFR scores come f
 3 Apr 30, 2022
3 Apr 30, 2022

Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
 7 Nov 9, 2022
7 Nov 9, 2022

Balabobapy - Using artificial intelligence algorithms to continue the text
Balabobapy - Using artificial intelligence algorithms to continue the text
 1 Feb 4, 2022
1 Feb 4, 2022
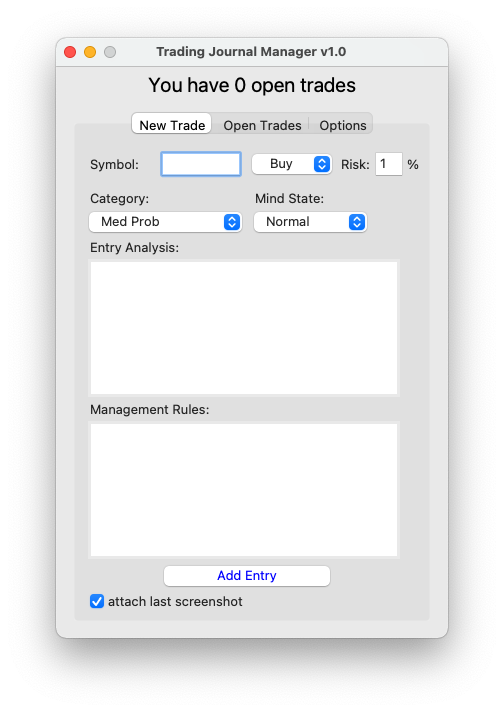
A python Tk GUI that creates, writes text and attaches images into a custom spreadsheet file
A python Tk GUI that creates, writes text and attaches images into a custom spreadsheet file
 13 Dec 9, 2022
13 Dec 9, 2022
En- and decrypting text-messages by creating a key with of the fibonacci-sequence
En- and decrypting text-messages by creating a key with of the fibonacci-sequence. This key helps to create mathematical functions, whose zeros should generates the encrypted message.
 1 Feb 5, 2022
1 Feb 5, 2022
Application to help find best train itinerary, uses speech to text, has a spam filter to segregate invalid inputs, NLP and Pathfinding algos.
T-IAI-901-MSC2022 - GROUP 18 Gestion de projet Notre travail a été organisé et réparti dans un Trello. https://trello.com/b/X3s2fpPJ/ia-projet Install
 1 Feb 5, 2022
1 Feb 5, 2022
JD-backup is an advanced Python script, that will extract all links from a jDownloader 2 file list and export them to a text file.
JD-backup is an advanced Python script, that will extract all links from a jDownloader 2 file list and export them to a text file.
 3 Jun 7, 2022
3 Jun 7, 2022
A collection of Jupyter notebooks to play with NVIDIA's StyleGAN3 and OpenAI's CLIP for a text-based guided image generation.
StyleGAN3 CLIP-based guidance StyleGAN3 + CLIP StyleGAN3 + inversion + CLIP This repo is a collection of Jupyter notebooks made to easily play with St
 176 Dec 30, 2022
176 Dec 30, 2022
/samples.jpg)
A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution.
Awesome Pretrained StyleGAN2 A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution. Note the readme is a
 1.1k Dec 24, 2022
1.1k Dec 24, 2022

An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to art and design.
Awesome AI for Art & Design An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to a
 20 Dec 21, 2022
20 Dec 21, 2022
Pytorch implementation of the paper "Enhancing Content Preservation in Text Style Transfer Using Reverse Attention and Conditional Layer Normalization"
Pytorch implementation of the paper "Enhancing Content Preservation in Text Style Transfer Using Reverse Attention and Conditional Layer Normalization"
 4 Sep 18, 2022
4 Sep 18, 2022
Fake Shakespearean Text Generator
Fake Shakespearean Text Generator This project contains an impelementation of stateful Char-RNN model to generate fake shakespearean texts. Files and
 1 Feb 15, 2022
1 Feb 15, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022

Py3editor - A text editor written in Python and Tkinter
Py3Editor My text editor written in Python and Tkinter! Contains a basic set of
 1 Mar 5, 2022
1 Mar 5, 2022
Integrating C Buffer Data Into the instruction of `.text` segment instead of on `.data`, `.rodata` to avoid copy.
gcc-bufdata-integrating2text Integrating C Buffer Data Into the instruction of .text segment instead of on .data, .rodata to avoid copy. Usage In your
 1 Jan 31, 2022
1 Jan 31, 2022
Creating an Audiobook (mp3 file) using a Ebook (epub) using BeautifulSoup and Google Text to Speech
epub2audiobook Creating an Audiobook (mp3 file) using a Ebook (epub) using BeautifulSoup and Google Text to Speech Input examples qual a pasta do seu
 7 Aug 25, 2022
7 Aug 25, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
 32 Dec 29, 2022
32 Dec 29, 2022
Python tool that takes the OCR.space JSON output as input and draws a text overlay on top of the image.
OCR.space OCR Result Checker = Draw OCR overlay on top of image Python tool that takes the OCR.space JSON output as input, and draws an overlay on to
 4 Oct 18, 2022
4 Oct 18, 2022
List of Land Cover datasets in the GEE Catalog
List of Land Cover datasets in the GEE Catalog A list of all the Land Cover (or discrete) datasets in Google Earth Engine. Values, Colors and Descript
 5 Aug 24, 2022
5 Aug 24, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
 327 Jan 1, 2023
327 Jan 1, 2023

RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and rearranging captions and pictures. Unlike other versions of the model we use BERT for text encoder and SWIN transformer for image encoder.
ruCLIP-SB RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and re
 5 Apr 13, 2022
5 Apr 13, 2022
This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transformer"
FlatTN This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transfor
 74 Nov 28, 2022
74 Nov 28, 2022
Tensorflow Implementation of A Generative Flow for Text-to-Speech via Monotonic Alignment Search
Tensorflow Implementation of A Generative Flow for Text-to-Speech via Monotonic Alignment Search
 10 Oct 13, 2022
10 Oct 13, 2022
This repository contains (not all) code from my project on Named Entity Recognition in philosophical text
NERphilosophy 👋 Welcome to the github repository of my BsC thesis. This repository contains (not all) code from my project on Named Entity Recognitio
 1 Jan 27, 2022
1 Jan 27, 2022
2 telegram-bots: for image recognition and for text generation
💻 📱 Telegram_Bots 🔎 & 📖 2 telegram-bots: for image recognition and for text generation. About Image recognition bot: User sends a photo and bot de
 1 Jan 27, 2022
1 Jan 27, 2022
Recognizing the text contents from a scanned visiting card
Recognizing the text contents from a scanned visiting card. The application which is used to recognize the text from scanned images,printeddocuments,r
 1 Jan 28, 2022
1 Jan 28, 2022
This repository serves as a place to document a toy attempt on how to create a generative text model in Catalan, based on GPT-2
GPT-2 Catalan playground and scripts to train a GPT-2 model either from scrath or from another pretrained model.
 1 Jan 28, 2022
1 Jan 28, 2022

Python script for writing text on github contribution chart.
Github Contribution Drawer Python script for writing text on github contribution chart. Requirements Python 3.X Getting Started Create repository Put
 0 May 27, 2022
0 May 27, 2022
Annotate datasets with a semi-trained or fully trained YOLOv5 model
YOLOv5 Auto Annotator Annotate datasets with a semi-trained or fully trained YOLOv5 model Prerequisites Ubuntu =20.04 Python =3.7 System dependencie
 3 May 14, 2022
3 May 14, 2022

A PyTorch implementation for our paper "Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation".
Dual-Contrastive-Learning A PyTorch implementation for our paper "Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation". Y
 85 Dec 26, 2022
85 Dec 26, 2022
For encoding a text longer than 512 tokens, for example 800. Set max_pos to 800 during both preprocessing and training.
LongScientificFormer For encoding a text longer than 512 tokens, for example 800. Set max_pos to 800 during both preprocessing and training. Some code
 6 Nov 2, 2022
6 Nov 2, 2022
PyTorch implementation of an end-to-end Handwritten Text Recognition (HTR) system based on attention encoder-decoder networks
AttentionHTR PyTorch implementation of an end-to-end Handwritten Text Recognition (HTR) system based on attention encoder-decoder networks. Scene Text
 31 Dec 22, 2022
31 Dec 22, 2022
Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation
Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation Prerequisites This repo is built upon a local copy of transfo
 10 Sep 28, 2022
10 Sep 28, 2022
A notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository
We provide a notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository. The notebook also shows how to segment the corpus using BPE tokenization which can be used to train an English-Hindi MT System.
 9 Oct 13, 2022
9 Oct 13, 2022
This pyhton script converts a pdf to Image then using tesseract as OCR engine converts Image to Text
Script_Convertir_PDF_IMG_TXT Este script de pyhton convierte un pdf en Imagen luego utilizando tesseract como motor OCR convierte la Imagen a Texto. p
 1 Jan 27, 2022
1 Jan 27, 2022

Create animated and pretty Pandas Dataframe or Pandas Series
Rich DataFrame Create animated and pretty Pandas Dataframe or Pandas Series, as shown below: Installation pip install rich-dataframe Usage Minimal exa
 92 Dec 26, 2022
92 Dec 26, 2022

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023
Graviti-python-sdk - Graviti Data Platform Python SDK
Graviti Python SDK Graviti Python SDK is a python library to access Graviti Data
 13 Dec 15, 2022
13 Dec 15, 2022

This is a NLP based project to extract effective date of the contract from their text files.
Date-Extraction-from-Contracts This is a NLP based project to extract effective date of the contract from their text files. Problem statement This is
 1 Jan 26, 2022
1 Jan 26, 2022
Towards Fine-Grained Reasoning for Fake News Detection
FinerFact This is the PyTorch implementation for the FinerFact model in the AAAI 2022 paper Towards Fine-Grained Reasoning for Fake News Detection (Ar
 15 Dec 15, 2022
15 Dec 15, 2022
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
TweebankNLP This repo contains the new Tweebank-NER dataset and off-the-shelf Twitter-Stanza pipeline for state-of-the-art Tweet NLP, as described in
 42 Jan 26, 2022
42 Jan 26, 2022

This repository contains the database and code used in the paper Embedding Arithmetic for Text-driven Image Transformation
This repository contains the database and code used in the paper Embedding Arithmetic for Text-driven Image Transformation (Guillaume Couairon, Holger
 31 Oct 17, 2022
31 Oct 17, 2022
"Structure-Augmented Text Representation Learning for Efficient Knowledge Graph Completion"(WWW 2021)
STAR_KGC This repo contains the source code of the paper accepted by WWW'2021. "Structure-Augmented Text Representation Learning for Efficient Knowled
 60 Dec 26, 2022
60 Dec 26, 2022
SpyQL - SQL with Python in the middle
SpyQL SQL with Python in the middle Concept SpyQL is a query language that combines: the simplicity and structure of SQL with the power and readabilit
 853 Dec 30, 2022
853 Dec 30, 2022
Postgres full text search options (tsearch, trigram) examples
postgres-full-text-search Postgres full text search options (tsearch, trigram) examples. Create DB CREATE DATABASE ftdb; To feed db with an example
 97 Dec 30, 2022
97 Dec 30, 2022
Discord Bot that can translate your text, count and reply to your messages with a personalised text
Discord Bot that can translate your text, count and reply to your messages with a personalised text
 2 Jan 26, 2022
2 Jan 26, 2022

CRLT: A Unified Contrastive Learning Toolkit for Unsupervised Text Representation Learning
CRLT: A Unified Contrastive Learning Toolkit for Unsupervised Text Representation Learning This repository contains the code and relevant instructions
 5 Aug 19, 2022
5 Aug 19, 2022

CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs
CLIP [Blog] [Paper] [Model Card] [Colab] CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pair
 6k Jan 25, 2022
6k Jan 25, 2022
STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs
STonKGs STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs. This multimodal Transformer combin
 27 Aug 11, 2022
27 Aug 11, 2022
Simple and understandable swin-transformer OCR project
swin-transformer-ocr ocr with swin-transformer Overview Simple and understandable swin-transformer OCR project. The model in this repository heavily r
 67 Dec 31, 2022
67 Dec 31, 2022
Improving Factual Completeness and Consistency of Image-to-text Radiology Report Generation
Improving Factual Completeness and Consistency of Image-to-text Radiology Report Generation The reference code of Improving Factual Completeness and C
 46 Dec 15, 2022
46 Dec 15, 2022

🛰️ Awesome Satellite Imagery Datasets
Awesome Satellite Imagery Datasets List of aerial and satellite imagery datasets with annotations for computer vision and deep learning. Newest datase
 3k Jan 3, 2023
3k Jan 3, 2023

This project generates news headlines using a Long Short-Term Memory (LSTM) neural network.
News Headlines Generator bunnysaini/Generate-Headlines Goal This project aims to generate news headlines using a Long Short-Term Memory (LSTM) neural
 1 Jan 24, 2022
1 Jan 24, 2022
Simple Text-To-Speech Bot For Discord
Simple Text-To-Speech Bot For Discord This is a very simple TTS bot for discord made with python. For this bot you need FFMPEG, see installation to se
 1 Sep 26, 2022
1 Sep 26, 2022
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features | paper | Official PyTorch implementation for Mul
 48 Dec 28, 2022
48 Dec 28, 2022
Klexikon: A German Dataset for Joint Summarization and Simplification
Klexikon: A German Dataset for Joint Summarization and Simplification Dennis Aumiller and Michael Gertz Heidelberg University Under submission at LREC
 8 Jan 3, 2023
8 Jan 3, 2023
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
 3 Jan 24, 2022
3 Jan 24, 2022
A python module to parse text files with contains secret variables.
A python module to parse text files with contains secret variables.
 0 Dec 5, 2022
0 Dec 5, 2022
AIDynamicTextReader - A simple dynamic text reader based on Artificial intelligence
AI Dynamic Text Reader: This is a simple dynamic text reader based on Artificial
 1 Jan 18, 2022
1 Jan 18, 2022
Blackstone is a spaCy model and library for processing long-form, unstructured legal text
Blackstone Blackstone is a spaCy model and library for processing long-form, unstructured legal text. Blackstone is an experimental research project f
 579 Jan 8, 2023
579 Jan 8, 2023

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
Grover is a model for Neural Fake News -- both generation and detectio
Grover is a model for Neural Fake News -- both generation and detection. However, it probably can also be used for other generation tasks.
 856 Dec 24, 2022
856 Dec 24, 2022

HairCLIP: Design Your Hair by Text and Reference Image
Overview This repository hosts the official PyTorch implementation of the paper: "HairCLIP: Design Your Hair by Text and Reference Image". Our single
 322 Dec 30, 2022
322 Dec 30, 2022

TransVTSpotter: End-to-end Video Text Spotter with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
 66 Dec 26, 2022
66 Dec 26, 2022

A library for creating text-based graphs in the terminal
tplot is a Python package for creating text-based graphs. Useful for visualizing data to the terminal or log files.
 164 Dec 14, 2022
164 Dec 14, 2022
ECLARE: Extreme Classification with Label Graph Correlations
ECLARE ECLARE: Extreme Classification with Label Graph Correlations @InProceedings{Mittal21b, author = "Mittal, A. and Sachdeva, N. and Agrawal
 35 Nov 6, 2022
35 Nov 6, 2022

Meta Self-learning for Multi-Source Domain Adaptation: A Benchmark
Meta Self-Learning for Multi-Source Domain Adaptation: A Benchmark Project | Arxiv | YouTube | | Abstract In recent years, deep learning-based methods
 188 Dec 12, 2022
188 Dec 12, 2022
Awesome AI Learning with +100 AI Cheat-Sheets, Free online Books, Top Courses, Best Videos and Lectures, Papers, Tutorials, +99 Researchers, Premium Websites, +121 Datasets, Conferences, Frameworks, Tools
All about AI with Cheat-Sheets(+100 Cheat-sheets), Free Online Books, Courses, Videos and Lectures, Papers, Tutorials, Researchers, Websites, Datasets
 1.2k Jan 1, 2023
1.2k Jan 1, 2023

T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets
T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets (product titles, images, comments, etc.).
 55 Nov 22, 2022
55 Nov 22, 2022
A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk.
Simple-Vosk A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk. Check out the official Vosk G
 2 Jun 19, 2022
2 Jun 19, 2022
TweebankNLP - Pre-trained Tweet NLP Pipeline (NER, tokenization, lemmatization, POS tagging, dependency parsing) + Models + Tweebank-NER
TweebankNLP This repo contains the new Tweebank-NER dataset and Twitter-Stanza p
84 Dec 20, 2022
Finetune the base 64 px GLIDE-text2im model from OpenAI on your own image-text dataset
Finetune the base 64 px GLIDE-text2im model from OpenAI on your own image-text dataset
 82 Oct 13, 2022
82 Oct 13, 2022
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss This is official implement of "
 87 Dec 24, 2022
87 Dec 24, 2022

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022
Custom function scheduler TUI (text-based user interface) in the console
Custom function scheduler TUI (text-based user interface) in the console
 1 Oct 26, 2022
1 Oct 26, 2022
Free & simple way to encipher text
VenSipher VenSipher is a free medium through which text can be enciphered. It can convert any text into an unrecognizable secret text that can only be
 3 Jan 28, 2022
3 Jan 28, 2022
The Scary Story - A Text Adventure
This is a text adventure which I made in python 3. This is one of my first big projects so any feedback would be greatly appreciated.
 2 Feb 20, 2022
2 Feb 20, 2022
📝An easy-to-use package to restore punctuation of the text.
✏️ rpunct - Restore Punctuation This repo contains code for Punctuation restoration. This package is intended for direct use as a punctuation restorat
 72 Dec 30, 2022
72 Dec 30, 2022

Cross-modal Retrieval using Transformer Encoder Reasoning Networks (TERN). With use of Metric Learning and FAISS for fast similarity search on GPU
Cross-modal Retrieval using Transformer Encoder Reasoning Networks This project reimplements the idea from "Transformer Reasoning Network for Image-Te
 5 Nov 5, 2022
5 Nov 5, 2022

CLIP2Video: Mastering Video-Text Retrieval via Image CLIP
CLIP2Video: Mastering Video-Text Retrieval via Image CLIP The implementation of paper CLIP2Video: Mastering Video-Text Retrieval via Image CLIP. CLIP2
 168 Dec 29, 2022
168 Dec 29, 2022
Pretty-doc - Composable text objects with python
pretty-doc from __future__ import annotations from dataclasses import dataclass
 2 Jan 17, 2022
2 Jan 17, 2022
Deasciify-highlighted - A Python script for deasciifying text to Turkish and copying clipboard
deasciify-highlighted is a Python script for deasciifying text to Turkish and copying clipboard.
 3 Mar 18, 2022
3 Mar 18, 2022

A Unified Framework and Analysis for Structured Knowledge Grounding
UnifiedSKG 📚 : Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models Code for paper UnifiedSKG: Unifying and Mu
 370 Dec 21, 2022
370 Dec 21, 2022

Rotated Box Is Back : Accurate Box Proposal Network for Scene Text Detection
Rotated Box Is Back : Accurate Box Proposal Network for Scene Text Detection This material is supplementray code for paper accepted in ICDAR 2021 We h
 30 Dec 21, 2022
30 Dec 21, 2022
[AI6122] Text Data Management & Processing
[AI6122] Text Data Management & Processing is an elective course of MSAI, SCSE, NTU, Singapore. The repository corresponds to the AI6122 of Semester 1, AY2021-2022, starting from 08/2021. The instructor of this course is Prof. Sun Aixin.
 1 Jan 17, 2022
1 Jan 17, 2022

NeWT: Natural World Tasks
NeWT: Natural World Tasks This repository contains resources for working with the NeWT dataset. ❗ At this time the binary tasks are not publicly avail
 26 Oct 18, 2022
26 Oct 18, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022