1394 Repositories
Python deduplicate-text-datasets Libraries
Repo for Enhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization
ESACL: Enhanced Seq2Seq Autoencoder via Contrastive Learning for AbstractiveText Summarization This repo is for our paper "Enhanced Seq2Seq Autoencode
 14 Nov 1, 2022
14 Nov 1, 2022
Transcribing audio files using Hugging Face's implementation of Wav2Vec2 + "chain-linking" NLP tasks to combine speech-to-text with downstream tasks like translation and summarisation.
PART 2: CHAIN LINKING AUDIO-TO-TEXT NLP TASKS 2A: TRANSCRIBE-TRANSLATE-SENTIMENT-ANALYSIS In notebook3.0, I demo a simple workflow to: transcribe a lo
 30 Jul 13, 2022
30 Jul 13, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
Large-scale pretraining for dialogue
A State-of-the-Art Large-scale Pretrained Response Generation Model (DialoGPT) This repository contains the source code and trained model for a large-
1.8k Jan 7, 2023
Code for ACL 2020 paper "Rigid Formats Controlled Text Generation"
SongNet SongNet: SongCi + Song (Lyrics) + Sonnet + etc. @inproceedings{li-etal-2020-rigid, title = "Rigid Formats Controlled Text Generation",
 212 Dec 17, 2022
212 Dec 17, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
 2.1k Dec 28, 2022
2.1k Dec 28, 2022
Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
Tensor2Tensor Tensor2Tensor, or T2T for short, is a library of deep learning models and datasets designed to make deep learning more accessible and ac
 12.9k Jan 7, 2023
12.9k Jan 7, 2023
Code for Massive-scale Decoding for Text Generation using Lattices
Massive-scale Decoding for Text Generation using Lattices Jiacheng Xu, Greg Durrett TL;DR: a new search algorithm to construct lattices encoding many
 37 Dec 18, 2022
37 Dec 18, 2022
Delta TTA(Text To Audio) SoftWare
Text-To-Audio-Windows Delta TTA(Text To Audio) SoftWare Info You Can Use It For Convert Your Text To Audio File You Just Write Your Text And Your End
 2 Dec 14, 2021
2 Dec 14, 2021

Text Classification in Turkish Texts with Bert
You can watch the details of the project on my youtube channel Project Interface Project Second Interface Goal= Correctly guessing the classification
 42 Dec 31, 2022
42 Dec 31, 2022

The projects lets you extract glossary words and their definitions from a given piece of text automatically using NLP techniques
Unsupervised technique to Glossary and Definition Extraction Code Files GPT2-DefinitionModel.ipynb - GPT-2 model for definition generation. Data_Gener
 28 May 25, 2021
28 May 25, 2021

Predict an emoji that is associated with a text
Sentiment Analysis Sentiment analysis in computational linguistics is a general term for techniques that quantify sentiment or mood in a text. Can you
 30 Sep 7, 2022
30 Sep 7, 2022
🔎 Like Chardet. 🚀 Package for encoding & language detection. Charset detection.
Charset Detection, for Everyone 👋 The Real First Universal Charset Detector A library that helps you read text from an unknown charset encoding. Moti
 332 Dec 31, 2022
332 Dec 31, 2022
Text completion with Hugging Face and TensorFlow.js running on Node.js
Katana ML Text Completion 🤗 Description Runs with with Hugging Face DistilBERT and TensorFlow.js on Node.js distilbert-model - converter from Hugging
 2 Nov 4, 2022
2 Nov 4, 2022

A public data repository for datasets created from TransLink GTFS data.
TransLink Spatial Data What: TransLink is the statutory public transit authority for the Metro Vancouver region. This GitHub repository is a collectio
 3 Jan 14, 2022
3 Jan 14, 2022
Put blind watermark into a text with python
text_blind_watermark Put blind watermark into a text. Can be used in Wechat dingding ... How to Use install pip install text_blind_watermark Alice Pu
 164 Dec 30, 2022
164 Dec 30, 2022

A 1.3B text-to-image generation model trained on 14 million image-text pairs
minDALL-E on Conceptual Captions minDALL-E, named after minGPT, is a 1.3B text-to-image generation model trained on 14 million image-text pairs for no
 604 Dec 14, 2022
604 Dec 14, 2022
Joint learning of images and text via maximization of mutual information
mutual_info_img_txt Joint learning of images and text via maximization of mutual information. This repository incorporates the algorithms presented in
 10 Dec 22, 2022
10 Dec 22, 2022
Using Bert as the backbone model for lime, designed for NLP task explanation (sentence pair text classification task)
Lime Comparing deep contextualized model for sentences highlighting task. In addition, take the classic explanation model "LIME" with bert-base model
 2 Jan 18, 2022
2 Jan 18, 2022

The datasets and code of ACL 2021 paper "Aspect-Category-Opinion-Sentiment Quadruple Extraction with Implicit Aspects and Opinions".
Aspect-Category-Opinion-Sentiment (ACOS) Quadruple Extraction This repo contains the data sets and source code of our paper: Aspect-Category-Opinion-S
 144 Jan 2, 2023
144 Jan 2, 2023
![[ICME 2021 Oral] CORE-Text: Improving Scene Text Detection with Contrastive Relational Reasoning](https://github.com/jylins/CORE-Text/raw/main/resources/core_text.png)
[ICME 2021 Oral] CORE-Text: Improving Scene Text Detection with Contrastive Relational Reasoning
CORE-Text: Improving Scene Text Detection with Contrastive Relational Reasoning This repository is the official PyTorch implementation of CORE-Text, a
 18 Aug 11, 2022
18 Aug 11, 2022
Adversarial Examples for Extreme Multilabel Text Classification
Adversarial Examples for Extreme Multilabel Text Classification The code is adapted from the source codes of BERT-ATTACK [1], APLC_XLNet [2], and Atte
 1 May 14, 2022
1 May 14, 2022
Type annotations builder for boto3 compatible with VSCode, PyCharm, Emacs, Sublime Text, pyright and mypy.
mypy_boto3_builder Type annotations builder for boto3-stubs project. Compatible with VSCode, PyCharm, Emacs, Sublime Text, mypy, pyright and other too
 2 Dec 5, 2022
2 Dec 5, 2022
A collection of existing KGQA datasets in the form of the huggingface datasets library, aiming to provide an easy-to-use access to them.
KGQA Datasets Brief Introduction This repository is a collection of existing KGQA datasets in the form of the huggingface datasets library, aiming to
 21 Jan 6, 2023
21 Jan 6, 2023

Manage your WordPress installation directly from SublimeText SideBar and Command Palette.
WordpressPluginManager Manage your WordPress installation directly from SublimeText SideBar and Command Palette. Installation Dependencies You will ne
 1 Dec 14, 2021
1 Dec 14, 2021

Converts a text file of songs to a playlist on your Spotify account.
Playlist Converter Convert a text file of songs to a playlist on your Spotify account. Create your playlists faster instead of manually searching for
 18 Dec 21, 2022
18 Dec 21, 2022
The code of "Dependency Learning for Legal Judgment Prediction with a Unified Text-to-Text Transformer".
Code data_preprocess.py: preprocess data for Dependent-T5. parameters.py: define parameters of Dependent-T5. train_tools.py: traning and evaluation co
 1 Apr 21, 2022
1 Apr 21, 2022

CleanX is an open source python library for exploring, cleaning and augmenting large datasets of X-rays, or certain other types of radiological images.
cleanX CleanX is an open source python library for exploring, cleaning and augmenting large datasets of X-rays, or certain other types of radiological
 20 Jan 5, 2023
20 Jan 5, 2023
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
 47 Dec 26, 2022
47 Dec 26, 2022

Binary classification for arrythmia detection with ECG datasets.
HEART DISEASE AI DATATHON 2021 [Eng] / [Kor] #English This is an AI diagnosis modeling contest that uses the heart disease echocardiography and electr
 3 Jul 14, 2022
3 Jul 14, 2022
Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts
t5-japanese Codes to pre-train T5 (Text-to-Text Transfer Transformer) models pre-trained on Japanese web texts. The following is a list of models that
 1 Dec 13, 2021
1 Dec 13, 2021

Python library to build pretty command line user prompts ✨Easy to use multi-select lists, confirmations, free text prompts ...
Questionary ✨ Questionary is a Python library for effortlessly building pretty command line interfaces ✨ Features Installation Usage Documentation Sup
 990 Jan 1, 2023
990 Jan 1, 2023
Extract price amount and currency symbol from a raw text string
price-parser is a small library for extracting price and currency from raw text strings.
 252 Dec 31, 2022
252 Dec 31, 2022
Convert long numbers into a human-readable format in Python
Convert long numbers into a human-readable format in Python
 73 Dec 28, 2022
73 Dec 28, 2022

♟️ QR Code display for P4wnP1 (SSH, VNC, any text / URL)
♟️ Display QR Codes on P4wnP1 (p4wnsolo-qr) 🟢 QR Code display for P4wnP1 w/OLED (SSH, VNC, P4wnP1 WebGUI, any text / URL / exfiltrated data) Note: Th
 4 Dec 19, 2022
4 Dec 19, 2022
Easy Language Model Pretraining leveraging Huggingface's Transformers and Datasets
Easy Language Model Pretraining leveraging Huggingface's Transformers and Datasets What is LASSL • How to Use What is LASSL LASSL은 LAnguage Semi-Super
 116 Dec 27, 2022
116 Dec 27, 2022
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022
Synthetic Data Generation for tabular, relational and time series data.
An Open Source Project from the Data to AI Lab, at MIT Website: https://sdv.dev Documentation: https://sdv.dev/SDV User Guides Developer Guides Github
 1.2k Jan 7, 2023
1.2k Jan 7, 2023
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
47 Dec 26, 2022
Python 3 module to print out long strings of text with intervals of time inbetween
Python-Fastprint Python 3 module to print out long strings of text with intervals of time inbetween Install: pip install fastprint Sync Usage: from fa
 2 Jun 27, 2022
2 Jun 27, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 9 Dec 11, 2021
9 Dec 11, 2021
Models, datasets and tools for Facial keypoints detection
Template for Data Science Project This repo aims to give a robust starting point to any Data Science related project. It contains readymade tools setu
 1 Feb 11, 2022
1 Feb 11, 2022

This script has been created in order to find what are the most common demanded technologies in Data Engineering field.
This is a Python script that given a whole corpus of job descriptions and a file with keywords it extracts the number of number of ocurrences of these keywords and write it to a file. This script it is easy to extend to accept more functionalities
 0 Jul 17, 2022
0 Jul 17, 2022
Synchronised text editor over TCP, for live editing with others.
SyncTEd Synchronised text editor over TCP, for live editing with others. Written in Python with PyGame. Run Install requirements: pip install -r requi
 1 May 13, 2022
1 May 13, 2022
A complete speech segmentation system using Kaldi and x-vectors for voice activity detection (VAD) and speaker diarisation.
bbc-speech-segmenter: Voice Activity Detection & Speaker Diarization A complete speech segmentation system using Kaldi and x-vectors for voice activit
 16 Oct 27, 2022
16 Oct 27, 2022

HairCLIP: Design Your Hair by Text and Reference Image
Overview This repository hosts the official PyTorch implementation of the paper: "HairCLIP: Design Your Hair by Text and Reference Image". Our single
 322 Jan 6, 2023
322 Jan 6, 2023

Official implementation of Self-supervised Image-to-text and Text-to-image Synthesis
Self-supervised Image-to-text and Text-to-image Synthesis This is the official implementation of Self-supervised Image-to-text and Text-to-image Synth
 6 Jul 31, 2022
6 Jul 31, 2022

A new video text spotting framework with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
67 Jan 3, 2023
Deep Learning Datasets Maker is a QGIS plugin to make datasets creation easier for raster and vector data.
Deep Learning Dataset Maker Deep Learning Datasets Maker is a QGIS plugin to make datasets creation easier for raster and vector data. How to use Down
 25 Dec 15, 2022
25 Dec 15, 2022
Integrate clang-format with Sublime Text
Sublime Text Clang Format Plugin This is a minimal plugin integrating clang-format with Sublime Text, with emphasis on the word minimal. It is not rea
 1 Dec 17, 2021
1 Dec 17, 2021

1st Online Python Editor With Live Syntax Checking and Execution
PythonBuddy 🖊️ 🐍 Online Python 3 Programming with Live Pylint Syntax Checking! Usage Fetch from repo: git clone https://github.com/ethanchewy/Python
 255 Dec 23, 2022
255 Dec 23, 2022
Code for paper "Extract, Denoise and Enforce: Evaluating and Improving Concept Preservation for Text-to-Text Generation" EMNLP 2021
The repo provides the code for paper "Extract, Denoise and Enforce: Evaluating and Improving Concept Preservation for Text-to-Text Generation" EMNLP 2
 18 May 24, 2022
18 May 24, 2022
[NeurIPS 2019] Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss
Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, Tengyu Ma This is the offi
 528 Jan 1, 2023
528 Jan 1, 2023

Papers, Datasets, Algorithms, SOTA for STR. Long-time Maintaining
Scene Text Recognition Recommendations Everythin about Scene Text Recognition SOTA • Papers • Datasets • Code Contents 1. Papers 2. Datasets 2.1 Synth
 197 Jan 5, 2023
197 Jan 5, 2023
Download and preprocess popular sequential recommendation datasets
Sequential Recommendation Datasets This repository collects some commonly used sequential recommendation datasets in recent research papers and provid
 125 Dec 6, 2022
125 Dec 6, 2022
Voice to Text using Raspberry Pi
This module will help to convert your voice (speech) into text using Speech Recognition Library. You can control the devices or you can perform the desired tasks by the word recognition
 2 Dec 15, 2021
2 Dec 15, 2021
EMNLP 2021 paper Models and Datasets for Cross-Lingual Summarisation.
This repository contains data and code for our EMNLP 2021 paper Models and Datasets for Cross-Lingual Summarisation. Please contact me at [email protected]
 9 Oct 28, 2022
9 Oct 28, 2022

Video Translation Into Text
2021/12/9 The project has been updated Added a home screen Just drag it onto the screen The final results \ 2021/12/9 项目已更新 添加了主界面 拖到即可 最后结果 \ Using t
 10 Mar 12, 2022
10 Mar 12, 2022

WACV 2022 Paper - Is An Image Worth Five Sentences? A New Look into Semantics for Image-Text Matching
Is An Image Worth Five Sentences? A New Look into Semantics for Image-Text Matching Code based on our WACV 2022 Accepted Paper: https://arxiv.org/pdf/
 13 Dec 17, 2022
13 Dec 17, 2022

Localized representation learning from Vision and Text (LoVT)
Localized Vision-Text Pre-Training Contrastive learning has proven effective for pre- training image models on unlabeled data and achieved great resul
 10 Dec 7, 2022
10 Dec 7, 2022

Package for extracting emotions from social media text. Tailored for financial data.
EmTract: Extracting Emotions from Social Media Text Tailored for Financial Contexts EmTract is a tool that extracts emotions from social media text. I
 13 Nov 17, 2022
13 Nov 17, 2022
![[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining](https://github.com/microsoft/COCO-LM/raw/main/coco-lm.png)
[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
COCO-LM This repository contains the scripts for fine-tuning COCO-LM pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: COCO-LM: Correcting an
106 Dec 12, 2022
Event Coding for the HV Protocol MEG datasets
Scripts for QA and trigger preprocessing of NIMH HV Protocol Install pip install git+https://github.com/nih-megcore/hv_proc Usage hv_process.py will
 2 Nov 14, 2022
2 Nov 14, 2022
This python script will generate passwords for your emails, With certain lengths, And saves them into plain text files.
How to use. Change the Default length of genereated password in default.length.txt Type the email for your account. Type the website that the email an
 2 Dec 26, 2021
2 Dec 26, 2021

Pytorch code for "Text-Independent Speaker Verification Using 3D Convolutional Neural Networks".
:speaker: Deep Learning & 3D Convolutional Neural Networks for Speaker Verification
 114 Dec 18, 2022
114 Dec 18, 2022
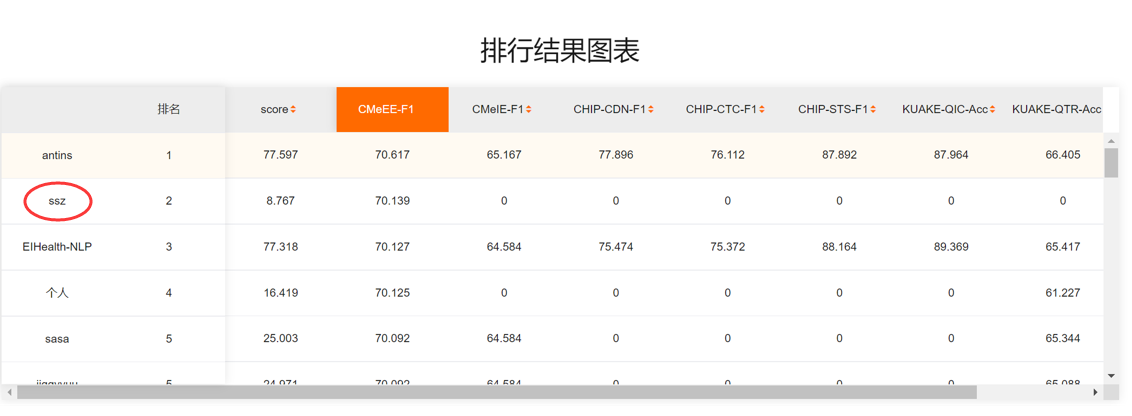
Nested Named Entity Recognition for Chinese Biomedical Text
CBio-NAMER CBioNAMER (Nested nAMed Entity Recognition for Chinese Biomedical Text) is our method used in CBLUE (Chinese Biomedical Language Understand
 8 Dec 25, 2022
8 Dec 25, 2022
Generative Adversarial Text to Image Synthesis
Text To Image Synthesis This is a tensorflow implementation of synthesizing images. The images are synthesized using the GAN-CLS Algorithm from the pa
 575 Jan 8, 2023
575 Jan 8, 2023

TensorFlow implementation of the paper "Hierarchical Attention Networks for Document Classification"
Hierarchical Attention Networks for Document Classification This is an implementation of the paper Hierarchical Attention Networks for Document Classi
 83 Dec 5, 2022
83 Dec 5, 2022
Convolutional Neural Network for Text Classification in Tensorflow
This code belongs to the "Implementing a CNN for Text Classification in Tensorflow" blog post. It is slightly simplified implementation of Kim's Convo
 5.5k Jan 2, 2023
5.5k Jan 2, 2023

Implementation of the ivis algorithm as described in the paper Structure-preserving visualisation of high dimensional single-cell datasets.
Implementation of the ivis algorithm as described in the paper Structure-preserving visualisation of high dimensional single-cell datasets.
 285 Jan 4, 2023
285 Jan 4, 2023
Train and use generative text models in a few lines of code.
blather Train and use generative text models in a few lines of code. To see blather in action check out the colab notebook! Installation Use the packa
 16 Nov 7, 2022
16 Nov 7, 2022

PyTorch implementation of Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Simple PyTorch Implementation of "Grokking" Implementation of Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets Usage Running
 15 Sep 29, 2022
15 Sep 29, 2022

A little but useful tool to explore OCR data extracted with `pytesseract` and `opencv`
Screenshot OCR Tool Extracting data from screen time screenshots in iOS and Android. We are exploring 3 options: Simple OCR with no text position usin
 1 Dec 7, 2021
1 Dec 7, 2021
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
 76 Dec 30, 2022
76 Dec 30, 2022

FuseDream: Training-Free Text-to-Image Generationwith Improved CLIP+GAN Space OptimizationFuseDream: Training-Free Text-to-Image Generationwith Improved CLIP+GAN Space Optimization
FuseDream This repo contains code for our paper (paper link): FuseDream: Training-Free Text-to-Image Generation with Improved CLIP+GAN Space Optimizat
 191 Dec 31, 2022
191 Dec 31, 2022

A mini command line tool to spellcheck text files using tadqeek.alsharekh.org
tadqeek_sakhr A mini command line tool to spellcheck text files using tadqeek.alsharekh.org Usage usage: python tadqeek_sakhr.py [-h] -i INPUT [-o OUT
 5 Dec 11, 2022
5 Dec 11, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
0 Mar 20, 2022
DaReCzech is a dataset for text relevance ranking in Czech
Dataset DaReCzech is a dataset for text relevance ranking in Czech. The dataset consists of more than 1.6M annotated query-documents pairs,
 8 Jul 26, 2022
8 Jul 26, 2022
A comprehensive set of fairness metrics for datasets and machine learning models, explanations for these metrics, and algorithms to mitigate bias in datasets and models.
AI Fairness 360 (AIF360) The AI Fairness 360 toolkit is an extensible open-source library containg techniques developed by the research community to h
 1.9k Jan 6, 2023
1.9k Jan 6, 2023
The implementation for paper Joint t-SNE for Comparable Projections of Multiple High-Dimensional Datasets.
Joint t-sne This is the implementation for paper Joint t-SNE for Comparable Projections of Multiple High-Dimensional Datasets. abstract: We present Jo
 7 Dec 18, 2022
7 Dec 18, 2022
This repository contains scripts to control a RGB text fan attached to a Raspberry Pi.
RGB Text Fan Controller This repository contains scripts to control a RGB text fan attached to a Raspberry Pi. Setup The Raspberry Pi and RGB text fan
 1 Oct 1, 2021
1 Oct 1, 2021

Implementation of NÜWA, state of the art attention network for text to video synthesis, in Pytorch
NÜWA - Pytorch (wip) Implementation of NÜWA, state of the art attention network for text to video synthesis, in Pytorch. This repository will be popul
 463 Dec 28, 2022
463 Dec 28, 2022

Implementation of Google Brain's WaveGrad high-fidelity vocoder
WaveGrad Implementation (PyTorch) of Google Brain's high-fidelity WaveGrad vocoder (paper). First implementation on GitHub with high-quality generatio
 363 Dec 27, 2022
363 Dec 27, 2022
DiffWave is a fast, high-quality neural vocoder and waveform synthesizer.
DiffWave DiffWave is a fast, high-quality neural vocoder and waveform synthesizer. It starts with Gaussian noise and converts it into speech via itera
 498 Jan 3, 2023
498 Jan 3, 2023
PyTorch toolkit for biomedical imaging
farabio is a minimal PyTorch toolkit for out-of-the-box deep learning support in biomedical imaging. For further information, see Wikis and Docs.
 47 Dec 28, 2022
47 Dec 28, 2022
Neural HMMs are all you need (for high-quality attention-free TTS)
Neural HMMs are all you need (for high-quality attention-free TTS) Shivam Mehta, Éva Székely, Jonas Beskow, and Gustav Eje Henter This is the official
 0 Oct 28, 2022
0 Oct 28, 2022

Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition"
CLIPstyler Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition" Environment Pytorch 1.7.1, Python 3.6 $ c
 201 Dec 29, 2022
201 Dec 29, 2022

Answering Open-Domain Questions of Varying Reasoning Steps from Text
This repository contains the authors' implementation of the Iterative Retriever, Reader, and Reranker (IRRR) model in the EMNLP 2021 paper "Answering Open-Domain Questions of Varying Reasoning Steps from Text".
 26 Dec 22, 2022
26 Dec 22, 2022

3D mesh stylization driven by a text input in PyTorch
Text2Mesh [Project Page] Text2Mesh is a method for text-driven stylization of a 3D mesh, as described in "Text2Mesh: Text-Driven Neural Stylization fo
 649 Dec 27, 2022
649 Dec 27, 2022
A Python script which randomly chooses and prints a file from a directory.
___ ____ ____ _ __ ___ / _ \ | _ \ | _ \ ___ _ __ | '__| / _ \ | |_| || | | || | | | / _ \| '__| | | | __/ | _ || |_| || |_| || __
 0 Aug 6, 2021
0 Aug 6, 2021

A Python script that creates subtitles of a given length from text paragraphs that can be easily imported into any Video Editing software such as FinalCut Pro for further adjustments.
Text to Subtitles - Python This python file creates subtitles of a given length from text paragraphs that can be easily imported into any Video Editin
 9 Dec 24, 2022
9 Dec 24, 2022
A prototype COG-based tile server for sparse Mars datasets
Mars tiler Mars Tiler is a prototype web application that serves tiles from cloud-optimized GeoTIFFs, with an emphasis on supporting planetary dataset
 3 Mar 23, 2022
3 Mar 23, 2022
Parse Any Text With Python
ParseAnyText A small package to parse strings. What is the work of it? Well It's a module to creates parser that helps to parse a text easily with les
 1 Jan 11, 2022
1 Jan 11, 2022

Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU
GPU Docker NLP Application Deployment Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU, to setup the enviroment on
 9 Oct 14, 2022
9 Oct 14, 2022
Encriptificator is a text editor app developed by me as a personal project.
Encriptificator is a text editor app developed by me as a personal project. It provides all basic features of a text editor with the additional feature of encrypting your files. To know more about how to use the encryption features , please read the readme file.
 1 May 9, 2022
1 May 9, 2022

Tensorflow implementation of Semi-supervised Sequence Learning (https://arxiv.org/abs/1511.01432)
Transfer Learning for Text Classification with Tensorflow Tensorflow implementation of Semi-supervised Sequence Learning(https://arxiv.org/abs/1511.01
 82 Oct 22, 2022
82 Oct 22, 2022
TextWorld is a sandbox learning environment for the training and evaluation of reinforcement learning (RL) agents on text-based games.
TextWorld A text-based game generator and extensible sandbox learning environment for training and testing reinforcement learning (RL) agents. Also ch
983 Dec 23, 2022

End-2-end speech synthesis with recurrent neural networks
Introduction New: Interactive demo using Google Colaboratory can be found here TTS-Cube is an end-2-end speech synthesis system that provides a full p
 214 Dec 7, 2022
214 Dec 7, 2022

Text to speech for Vietnamese, ez to use, ez to update
Chào mọi người, đây là dự án mở nhằm giúp việc đọc được trở nên dễ dàng hơn. Rất cảm ơn đội ngũ Zalo đã cung cấp hạ tầng để mình có thể tạo ra app này
 32 Jul 29, 2022
32 Jul 29, 2022
Simple GUI where you can enter an article and get a crisp summarized version.
Text-Summarization-using-TextRank-BART Simple GUI where you can enter an article and get a crisp summarized version. How to run: Clone the repo Instal
 4 Sep 28, 2022
4 Sep 28, 2022