1246 Repositories
Python speech-nlp-datasets Libraries

Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
MediumVC MediumVC is an utterance-level method towards any-to-any VC. Before that, we propose SingleVC to perform A2O tasks(Xi → Ŷi) , Xi means utter
 47 Dec 25, 2022
47 Dec 25, 2022
Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech
EdiTTS: Score-based Editing for Controllable Text-to-Speech Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech. Au
 98 Dec 25, 2022
98 Dec 25, 2022
Tribuo - A Java machine learning library
Tribuo - A Java prediction library (v4.1) Tribuo is a machine learning library in Java that provides multi-class classification, regression, clusterin
 1.1k Dec 28, 2022
1.1k Dec 28, 2022
StrengthNet: Deep Learning-based Emotion Strength Assessment for Emotional Speech Synthesis
StrengthNet Implementation of "StrengthNet: Deep Learning-based Emotion Strength Assessment for Emotional Speech Synthesis" https://arxiv.org/abs/2110
 21 Oct 11, 2021
21 Oct 11, 2021

A 10000+ hours dataset for Chinese speech recognition
WenetSpeech Official website | Paper A 10000+ Hours Multi-domain Chinese Corpus for Speech Recognition Download Please visit the official website, rea
 310 Jan 3, 2023
310 Jan 3, 2023

Speech Separation Using an Asynchronous Fully Recurrent Convolutional Neural Network
Speech Separation Using an Asynchronous Fully Recurrent Convolutional Neural Network This repository is the official implementation of Speech Separati
 116 Nov 9, 2022
116 Nov 9, 2022

PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
 279 Jan 4, 2023
279 Jan 4, 2023
Persian Kaldi profile for Rhasspy built from open speech data
Persian Kaldi Profile A Rhasspy profile for Persian (fa). Installation Get started by first installing Vosk: # Create virtual environment python3 -m v
 12 Aug 8, 2022
12 Aug 8, 2022
Every Google, Azure & IBM text to speech voice for free
TTS-Grabber Quick thing i made about a year ago to download any text with any tts voice, over 630 voices to choose from currently. It will split the i
 16 Dec 7, 2022
16 Dec 7, 2022

text to speech toolkit. 好用的中文语音合成工具箱,包含语音编码器、语音合成器、声码器和可视化模块。
ttskit Text To Speech Toolkit: 语音合成工具箱。 安装 pip install -U ttskit 注意 可能需另外安装的依赖包:torch,版本要求torch=1.6.0,=1.7.1,根据自己的实际环境安装合适cuda或cpu版本的torch。 ttskit的
 483 Jan 4, 2023
483 Jan 4, 2023
Implementation of "StrengthNet: Deep Learning-based Emotion Strength Assessment for Emotional Speech Synthesis"
StrengthNet Implementation of "StrengthNet: Deep Learning-based Emotion Strength Assessment for Emotional Speech Synthesis" https://arxiv.org/abs/2110
65 Dec 20, 2022
Train 🤗-transformers model with Poutyne.
poutyne-transformers Train 🤗 -transformers models with Poutyne. Installation pip install poutyne-transformers Example import torch from transformers
 2 Dec 18, 2022
2 Dec 18, 2022

Google's Meena transformer chatbot implementation
Here's my attempt at recreating Meena, a state of the art chatbot developed by Google Research and described in the paper Towards a Human-like Open-Domain Chatbot.
 94 Dec 25, 2022
94 Dec 25, 2022
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English ⚖️ 🏆 🧑🎓 👩⚖️ Dataset Summary Inspired by the recent widespread use of th
 95 Dec 8, 2022
95 Dec 8, 2022
EdiTTS: Score-based Editing for Controllable Text-to-Speech
Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech
99 Jan 2, 2023
PortaSpeech - PyTorch Implementation
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
276 Dec 26, 2022

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023
A set of examples around hub for creating and processing datasets
Examples for Hub - Dataset Format for AI A repository showcasing examples of using Hub Uploading Dataset Places365 Colab Tutorials Notebook Link Getti
 11 Dec 14, 2022
11 Dec 14, 2022
A Python library for choreographing your machine learning research.
A Python library for choreographing your machine learning research.
 270 Jan 6, 2023
270 Jan 6, 2023

PyTorch implementation of Microsoft's text-to-speech system FastSpeech 2: Fast and High-Quality End-to-End Text to Speech.
An implementation of Microsoft's "FastSpeech 2: Fast and High-Quality End-to-End Text to Speech"
 1k Dec 30, 2022
1k Dec 30, 2022
Refactored version of FastSpeech2
Refactored version of FastSpeech2. An implementation of Microsoft's "FastSpeech 2: Fast and High-Quality End-to-End Text to Speech"
 10 May 26, 2022
10 May 26, 2022
Signature remover is a NLP based solution which removes email signatures from the rest of the text.
Signature Remover Signature remover is a NLP based solution which removes email signatures from the rest of the text. It helps to enchance data conten
 8 Jan 6, 2023
8 Jan 6, 2023
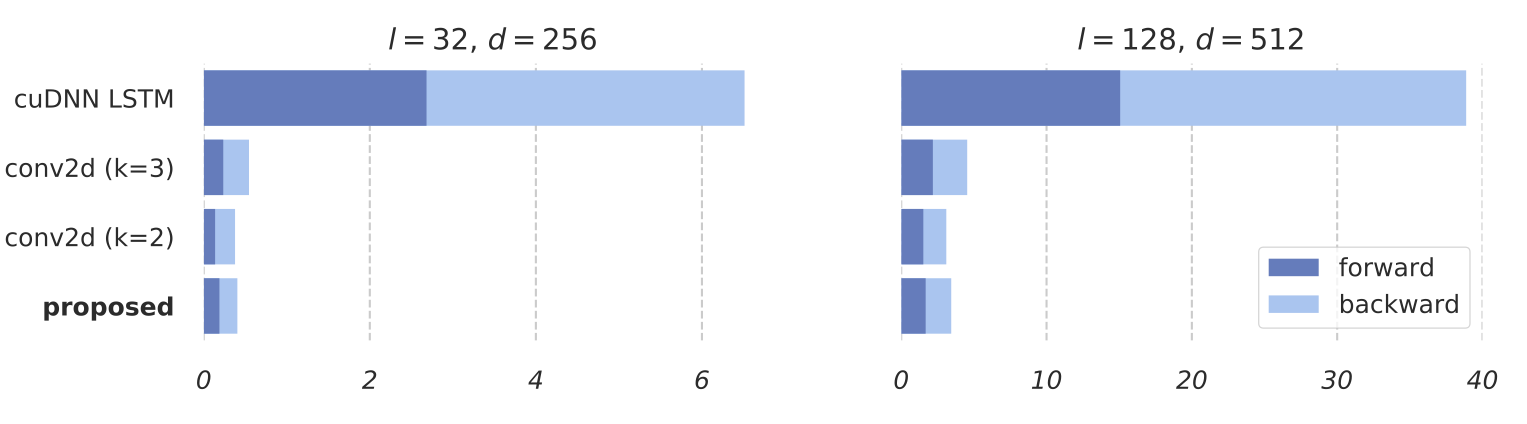
Training RNNs as Fast as CNNs
News SRU++, a new SRU variant, is released. [tech report] [blog] The experimental code and SRU++ implementation are available on the dev branch which
 2.1k Jan 1, 2023
2.1k Jan 1, 2023
TorchXRayVision: A library of chest X-ray datasets and models.
torchxrayvision A library for chest X-ray datasets and models. Including pre-trained models. ( 🎬 promo video about the project) Motivation: While the
 575 Jan 8, 2023
575 Jan 8, 2023
Beyond Paragraphs: NLP for Long Sequences
Beyond Paragraphs: NLP for Long Sequences
338 Dec 2, 2022
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modifies the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. OpenPrompt supports loading PLMs directly from huggingface transformers. In the future, we will also support PLMs implemented by other libraries.
 2.3k Jan 8, 2023
2.3k Jan 8, 2023

Google and Stanford University released a new pre-trained model called ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants. For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA. ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022

Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
 730 Jan 9, 2023
730 Jan 9, 2023
Paradigm Shift in NLP - "Paradigm Shift in Natural Language Processing".
Paradigm Shift in NLP Welcome to the webpage for "Paradigm Shift in Natural Language Processing". Some resources of the paper are constantly maintaine
 41 Dec 30, 2022
41 Dec 30, 2022

An official reimplementation of the method described in the INTERSPEECH 2021 paper - Speech Resynthesis from Discrete Disentangled Self-Supervised Representations.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations Implementation of the method described in the Speech Resynthesis from Di
 253 Jan 6, 2023
253 Jan 6, 2023

A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You can find two approaches for achieving this in this repo.
multitask-learning-transformers A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You
 48 Jan 2, 2023
48 Jan 2, 2023
VoiceFixer VoiceFixer is a framework for general speech restoration.
VoiceFixer VoiceFixer is a framework for general speech restoration. We aim at the restoration of severly degraded speech and historical speech. Paper
 174 Jan 6, 2023
174 Jan 6, 2023
A 10000+ hours dataset for Chinese speech recognition
A 10000+ hours dataset for Chinese speech recognition
309 Dec 16, 2022
Voicefixer aims at the restoration of human speech regardless how serious its degraded.
Voicefixer aims at the restoration of human speech regardless how serious its degraded.
324 Dec 26, 2022
Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ)
DeepNLP-models-Pytorch Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ: NLP with Deep Learning) This is not for Pytorch be
 2.9k Dec 24, 2022
2.9k Dec 24, 2022
An IPython Notebook tutorial on deep learning for natural language processing, including structure prediction.
Table of Contents: Introduction to Torch's Tensor Library Computation Graphs and Automatic Differentiation Deep Learning Building Blocks: Affine maps,
 1.8k Jan 4, 2023
1.8k Jan 4, 2023

C++ Implementation of PyTorch Tutorials for Everyone
C++ Implementation of PyTorch Tutorials for Everyone OS (Compiler)\LibTorch 1.9.0 macOS (clang 10.0, 11.0, 12.0) Linux (gcc 8, 9, 10, 11) Windows (msv
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022

Unofficial Implementation of Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration This repo contains only model Implementation of Zero-Shot Text-to-Speech for Text
 33 Sep 22, 2022
33 Sep 22, 2022

A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
237 Jan 2, 2023
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
 2.7k Jan 5, 2023
2.7k Jan 5, 2023
Create Fast and easy image datasets using reddit
Reddit-Image-Scraper Reddit Reddit is an American Social news aggregation, web content rating, and discussion website. Reddit has been devided by topi
 4 Apr 27, 2022
4 Apr 27, 2022

Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation (SIGGRAPH Asia 2021)
Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation This repository contains the implementation of the following paper: Live Speech
 575 Dec 31, 2022
575 Dec 31, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 287 Dec 21, 2022
287 Dec 21, 2022
Universal Adversarial Triggers for Attacking and Analyzing NLP (EMNLP 2019)
Universal Adversarial Triggers for Attacking and Analyzing NLP This is the official code for the EMNLP 2019 paper, Universal Adversarial Triggers for
 248 Dec 17, 2022
248 Dec 17, 2022

Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
 883 Jan 7, 2023
883 Jan 7, 2023
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023
A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis
WaveGlow A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis Quick Start: Install requirements: pip install
 204 Jul 14, 2022
204 Jul 14, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 2, 2023
77.2k Jan 2, 2023
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
Pervasive Attention: 2D Convolutional Networks for Sequence-to-Sequence Prediction
This is a fork of Fairseq(-py) with implementations of the following models: Pervasive Attention - 2D Convolutional Neural Networks for Sequence-to-Se
 490 Dec 15, 2022
490 Dec 15, 2022

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Jan 8, 2023
1.8k Jan 8, 2023
PyTorch implementation of Tacotron speech synthesis model.
tacotron_pytorch PyTorch implementation of Tacotron speech synthesis model. Inspired from keithito/tacotron. Currently not as much good speech quality
279 Dec 9, 2022

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
730 Jan 9, 2023

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Labelling platform for text using distant supervision
With DataQA, you can label unstructured text documents using rule-based distant supervision.
 245 Aug 5, 2022
245 Aug 5, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 4, 2023
7.1k Jan 4, 2023
Speech Recognition using DeepSpeech2.
deepspeech.pytorch Implementation of DeepSpeech2 for PyTorch using PyTorch Lightning. The repo supports training/testing and inference using the DeepS
 2k Jan 4, 2023
2k Jan 4, 2023
Recurrent Variational Autoencoder that generates sequential data implemented with pytorch
Pytorch Recurrent Variational Autoencoder Model: This is the implementation of Samuel Bowman's Generating Sentences from a Continuous Space with Kim's
 347 Nov 14, 2022
347 Nov 14, 2022
A Domain Specific Language (DSL) for building language patterns. These can be later compiled into spaCy patterns, pure regex, or any other format
RITA DSL This is a language, loosely based on language Apache UIMA RUTA, focused on writing manual language rules, which compiles into either spaCy co
 60 Sep 26, 2022
60 Sep 26, 2022
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.9k Dec 31, 2022
2.9k Dec 31, 2022
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022

The tool to make NLP datasets ready to use
chazutsu photo from Kaikado, traditional Japanese chazutsu maker chazutsu is the dataset downloader for NLP. import chazutsu r = chazutsu.data
 243 Dec 29, 2022
243 Dec 29, 2022

Neural network models for joint POS tagging and dependency parsing (CoNLL 2017-2018)
Neural Network Models for Joint POS Tagging and Dependency Parsing Implementations of joint models for POS tagging and dependency parsing, as describe
 152 Sep 2, 2022
152 Sep 2, 2022

TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP
TextAttack 🐙 Generating adversarial examples for NLP models [TextAttack Documentation on ReadTheDocs] About • Setup • Usage • Design About TextAttack
 2.2k Jan 3, 2023
2.2k Jan 3, 2023
A2T: Towards Improving Adversarial Training of NLP Models (EMNLP 2021 Findings)
A2T: Towards Improving Adversarial Training of NLP Models This is the source code for the EMNLP 2021 (Findings) paper "Towards Improving Adversarial T
17 Oct 15, 2022

💛 Code and Dataset for our EMNLP 2021 paper: "Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes"
Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes Official PyTorch implementation and EmoCause evaluatio
 50 Dec 21, 2022
50 Dec 21, 2022
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
 138 Jan 3, 2023
138 Jan 3, 2023
This project converts your human voice input to its text transcript and to an automated voice too.
Human Voice to Automated Voice & Text Introduction: In this project, whenever you'll speak, it will turn your voice into a robot voice and furthermore
 3 Oct 15, 2021
3 Oct 15, 2021
Codename generator using WordNet parts of speech database
codenames Codename generator using WordNet parts of speech database References: https://possiblywrong.wordpress.com/2021/09/13/code-name-generator/ ht
 27 Oct 30, 2022
27 Oct 30, 2022
Natural Language Processing with transformers
we want to create a repo to illustrate usage of transformers in chinese
 763 Dec 27, 2022
763 Dec 27, 2022
IndoBERTweet is the first large-scale pretrained model for Indonesian Twitter. Published at EMNLP 2021 (main conference)
IndoBERTweet 🐦 🇮🇩 1. Paper Fajri Koto, Jey Han Lau, and Timothy Baldwin. IndoBERTweet: A Pretrained Language Model for Indonesian Twitter with Effe
 40 Nov 30, 2022
40 Nov 30, 2022
Code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition"
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
67 Dec 1, 2022
Code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
This repository contains the code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
 28 Nov 10, 2022
28 Nov 10, 2022
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless.
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless. This is the official Roboflow python package that interfaces with the Roboflow API.
 52 Dec 23, 2022
52 Dec 23, 2022
Augmenty is an augmentation library based on spaCy for augmenting texts.
Augmenty: The cherry on top of your NLP pipeline Augmenty is an augmentation library based on spaCy for augmenting texts. Besides a wide array of high
 124 Dec 29, 2022
124 Dec 29, 2022

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE 以数据为中心的AI测评(DataCLUE) DataCLUE: A Chinese Data-centric Language Evaluation Benchmark 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE)的背景 任务描述 任务描述 实验结果
 135 Dec 22, 2022
135 Dec 22, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
7.6k Jan 1, 2023

Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition
Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition Official implementation of the Efficient Conforme
 145 Dec 30, 2022
145 Dec 30, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022

Control the classic General Instrument SP0256-AL2 speech chip and AY-3-8910 sound generator with a Raspberry Pi and this Python library.
GI-Pi Control the classic General Instrument SP0256-AL2 speech chip and AY-3-8910 sound generator with a Raspberry Pi and this Python library. The SP0
 8 Dec 15, 2021
8 Dec 15, 2021

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022
This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation". It is intended to be used for normalizing / cleaning Bengali and English text.
normalizer This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch
23 Nov 30, 2022
An easy way to build PyTorch datasets. Modularly build datasets and automatically cache processed results
EasyDatas An easy way to build PyTorch datasets. Modularly build datasets and automatically cache processed results Installation pip install git+https
 4 Dec 14, 2021
4 Dec 14, 2021
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

Data augmentation for NLP, accepted at EMNLP 2021 Findings
AEDA: An Easier Data Augmentation Technique for Text Classification This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Techni
 81 Dec 9, 2022
81 Dec 9, 2022
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks A Transformer-based library for SocialNLP classification tasks. Currently
 298 Jan 7, 2023
298 Jan 7, 2023

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022

TorchIO is a Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
 1.6k Jan 6, 2023
1.6k Jan 6, 2023
Implementation of "A Deep Learning Loss Function based on Auditory Power Compression for Speech Enhancement" by pytorch
This repository is used to suspend the results of our paper "A Deep Learning Loss Function based on Auditory Power Compression for Speech Enhancement"
 19 Sep 30, 2022
19 Sep 30, 2022
The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal and to generate far-field speech data using room impulse response data from BUT Speech@FIT Reverb Database.
Add_noise_and_rir_to_speech The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal
 7 Oct 30, 2022
7 Oct 30, 2022
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
297 Dec 29, 2022

OpenCVのGrabCut()を利用したセマンティックセグメンテーション向けアノテーションツール(Annotation tool using GrabCut() of OpenCV. It can be used to create datasets for semantic segmentation.)
[Japanese/English] GrabCut-Annotation-Tool GrabCut-Annotation-Tool.mp4 OpenCVのGrabCut()を利用したアノテーションツールです。 セマンティックセグメンテーション向けのデータセット作成にご使用いただけます。 ※Grab
 30 Nov 18, 2022
30 Nov 18, 2022