988 Repositories
Python stereo-vision Libraries
HybVIO visual-inertial odometry and SLAM system
HybVIO A visual-inertial odometry system with an optional SLAM module. This is a research-oriented codebase, which has been published for the purposes
 320 Jan 3, 2023
320 Jan 3, 2023
labelpix is a graphical image labeling interface for drawing bounding boxes
Welcome to labelpix 👋 labelpix is a graphical image labeling interface for drawing bounding boxes. 🏠 Homepage Install pip install -r requirements.tx
 26 May 24, 2022
26 May 24, 2022
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
 105 Jan 8, 2022
105 Jan 8, 2022

Official repository for the paper F, B, Alpha Matting
FBA Matting Official repository for the paper F, B, Alpha Matting. This paper and project is under heavy revision for peer reviewed publication, and s
 404 Jan 5, 2023
404 Jan 5, 2023

The code for the NeurIPS 2021 paper "A Unified View of cGANs with and without Classifiers".
Energy-based Conditional Generative Adversarial Network (ECGAN) This is the code for the NeurIPS 2021 paper "A Unified View of cGANs with and without
 11 Nov 25, 2021
11 Nov 25, 2021
Code of TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation
TVT Code of TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation Datasets: Digit: MNIST, SVHN, USPS Object: Office, Office-Home, Vi
 37 Dec 15, 2022
37 Dec 15, 2022

Source code for CVPR 2020 paper "Learning to Forget for Meta-Learning"
L2F - Learning to Forget for Meta-Learning Sungyong Baik, Seokil Hong, Kyoung Mu Lee Source code for CVPR 2020 paper "Learning to Forget for Meta-Lear
 29 May 22, 2022
29 May 22, 2022
🔥RandLA-Net in Tensorflow (CVPR 2020, Oral & IEEE TPAMI 2021)
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds (CVPR 2020) This is the official implementation of RandLA-Net (CVPR2020, Oral
 1k Dec 30, 2022
1k Dec 30, 2022

Pytorch reimplementation of PSM-Net: "Pyramid Stereo Matching Network"
This is a Pytorch Lightning version PSMNet which is based on JiaRenChang/PSMNet. use python main.py to start training. PSM-Net Pytorch reimplementatio
 1 Nov 25, 2021
1 Nov 25, 2021
OpenMMLab Computer Vision Foundation
English | 简体中文 Introduction MMCV is a foundational library for computer vision research and supports many research projects as below: MMCV: OpenMMLab
 4.6k Jan 9, 2023
4.6k Jan 9, 2023

A minimal solution to hand motion capture from a single color camera at over 100fps. Easy to use, plug to run.
Minimal Hand A minimal solution to hand motion capture from a single color camera at over 100fps. Easy to use, plug to run. This project provides the
 824 Jan 7, 2023
824 Jan 7, 2023
YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet )
Yolo v4, v3 and v2 for Windows and Linux (neural networks for object detection) Paper YOLO v4: https://arxiv.org/abs/2004.10934 Paper Scaled YOLO v4:
 20.2k Jan 9, 2023
20.2k Jan 9, 2023

A hybrid SOTA solution of LiDAR panoptic segmentation with C++ implementations of point cloud clustering algorithms. ICCV21, Workshop on Traditional Computer Vision in the Age of Deep Learning
ICCVW21-TradiCV-Survey-of-LiDAR-Cluster Motivation In contrast to popular end-to-end deep learning LiDAR panoptic segmentation solutions, we propose a
 103 Nov 22, 2022
103 Nov 22, 2022

A TensorFlow 2.x implementation of Masked Autoencoders Are Scalable Vision Learners
Masked Autoencoders Are Scalable Vision Learners A TensorFlow implementation of Masked Autoencoders Are Scalable Vision Learners [1]. Our implementati
 59 Dec 10, 2022
59 Dec 10, 2022

Official PyTorch implementation of "Meta-Learning with Task-Adaptive Loss Function for Few-Shot Learning" (ICCV2021 Oral)
MeTAL - Meta-Learning with Task-Adaptive Loss Function for Few-Shot Learning (ICCV2021 Oral) Sungyong Baik, Janghoon Choi, Heewon Kim, Dohee Cho, Jaes
44 Dec 29, 2022

R interface to fast.ai
R interface to fastai The fastai package provides R wrappers to fastai. The fastai library simplifies training fast and accurate neural nets using mod
 113 Dec 20, 2022
113 Dec 20, 2022
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
An Agnostic Object Detection Framework IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-q
 790 Jan 5, 2023
790 Jan 5, 2023
Official Implementation of "Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras"
Multi Camera Pig Tracking Official Implementation of Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras CVPR2021 CV4Animals Workshop P
 44 Jan 6, 2023
44 Jan 6, 2023
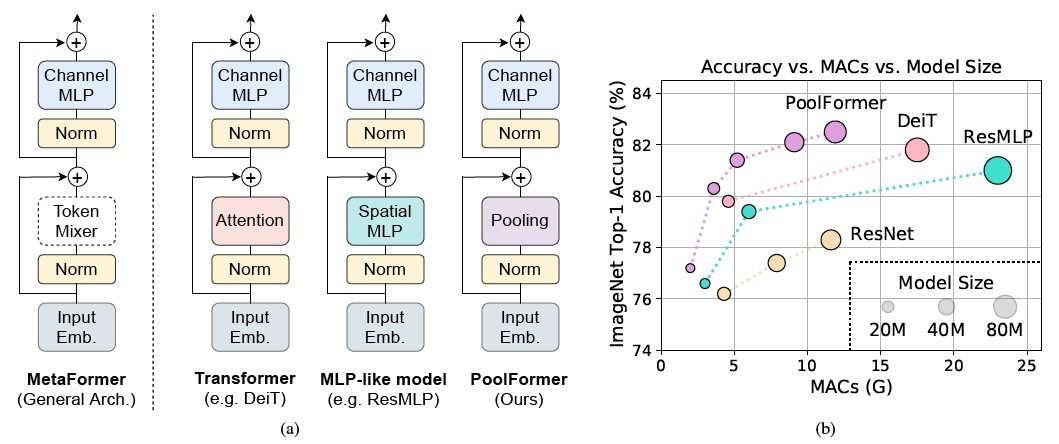
PoolFormer: MetaFormer is Actually What You Need for Vision
PoolFormer: MetaFormer is Actually What You Need for Vision (arXiv) This is a PyTorch implementation of PoolFormer proposed by our paper "MetaFormer i
 1k Dec 30, 2022
1k Dec 30, 2022
FedCV: A Federated Learning Framework for Diverse Computer Vision Tasks
FedCV: A Federated Learning Framework for Diverse Computer Vision Tasks Image Classification Dataset: Google Landmark, COCO, ImageNet Model: Efficient
 62 Dec 10, 2022
62 Dec 10, 2022
Unofficial keras(tensorflow) implementation of MAE model from Masked Autoencoders Are Scalable Vision Learners
MAE-keras Unofficial keras(tensorflow) implementation of MAE model described in 'Masked Autoencoders Are Scalable Vision Learners'. This work has been
 11 Jun 12, 2022
11 Jun 12, 2022

Tensorflow 2.x implementation of Vision-Transformer model
Vision Transformer Unofficial Tensorflow 2.x implementation of the Transformer based Image Classification model proposed by the paper AN IMAGE IS WORT
 16 Jul 20, 2022
16 Jul 20, 2022

PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition, CVPR 2018
PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place
 294 Dec 12, 2022
294 Dec 12, 2022
COLMAP - Structure-from-Motion and Multi-View Stereo
COLMAP About COLMAP is a general-purpose Structure-from-Motion (SfM) and Multi-View Stereo (MVS) pipeline with a graphical and command-line interface.
 4.7k Jan 7, 2023
4.7k Jan 7, 2023

Current state of supervised and unsupervised depth completion methods
Awesome Depth Completion Table of Contents About Sparse-to-Dense Depth Completion Current State of Depth Completion Unsupervised VOID Benchmark Superv
 224 Dec 28, 2022
224 Dec 28, 2022

Multi-modal Vision Transformers Excel at Class-agnostic Object Detection
Multi-modal Vision Transformers Excel at Class-agnostic Object Detection
 206 Jan 4, 2023
206 Jan 4, 2023

Detectron2 for Document Layout Analysis
Detectron2 trained on PubLayNet dataset This repo contains the training configurations, code and trained models trained on PubLayNet dataset using Det
 163 Nov 21, 2022
163 Nov 21, 2022

Open source simulator for autonomous vehicles built on Unreal Engine / Unity, from Microsoft AI & Research
Welcome to AirSim AirSim is a simulator for drones, cars and more, built on Unreal Engine (we now also have an experimental Unity release). It is open
13.8k Jan 5, 2023

TransMorph: Transformer for Medical Image Registration
TransMorph: Transformer for Medical Image Registration keywords: Vision Transformer, Swin Transformer, convolutional neural networks, image registrati
 180 Jan 7, 2023
180 Jan 7, 2023
Deep Learning with PyTorch made easy 🚀 !
Deep Learning with PyTorch made easy 🚀 ! Carefree? carefree-learn aims to provide CAREFREE usages for both users and developers. It also provides a c
 381 Dec 22, 2022
381 Dec 22, 2022
TensorFlow implementation of Barlow Twins (Barlow Twins: Self-Supervised Learning via Redundancy Reduction)
Barlow-Twins-TF This repository implements Barlow Twins (Barlow Twins: Self-Supervised Learning via Redundancy Reduction) in TensorFlow and demonstrat
 36 Sep 14, 2022
36 Sep 14, 2022
Lacmus is a cross-platform application that helps to find people who are lost in the forest using computer vision and neural networks.
lacmus The program for searching through photos from the air of lost people in the forest using Retina Net neural nwtwork. The project is being develo
 168 Dec 27, 2022
168 Dec 27, 2022
PyTorch Connectomics: segmentation toolbox for EM connectomics
Introduction The field of connectomics aims to reconstruct the wiring diagram of the brain by mapping the neural connections at the level of individua
 132 Dec 26, 2022
132 Dec 26, 2022
How to use TensorLayer
How to use TensorLayer While research in Deep Learning continues to improve the world, we use a bunch of tricks to implement algorithms with TensorLay
 349 Dec 7, 2022
349 Dec 7, 2022
Source code and notebooks to reproduce experiments and benchmarks on Bias Faces in the Wild (BFW).
Face Recognition: Too Bias, or Not Too Bias? Robinson, Joseph P., Gennady Livitz, Yann Henon, Can Qin, Yun Fu, and Samson Timoner. "Face recognition:
 41 Dec 12, 2022
41 Dec 12, 2022

Lab Materials for MIT 6.S191: Introduction to Deep Learning
This repository contains all of the code and software labs for MIT 6.S191: Introduction to Deep Learning! All lecture slides and videos are available
 5.6k Dec 26, 2022
5.6k Dec 26, 2022

Apply different text recognition services to images of handwritten documents.
Handprint The Handwritten Page Recognition Test is a command-line program that invokes HTR (handwritten text recognition) services on images of docume
 117 Jan 2, 2023
117 Jan 2, 2023

Implementation EfficientDet: Scalable and Efficient Object Detection in PyTorch
Implementation EfficientDet: Scalable and Efficient Object Detection in PyTorch
 1.4k Dec 29, 2022
1.4k Dec 29, 2022
kyle's vision of how datadog's python client should look
kyle's datadog python vision/proposal not for production use See examples/comprehensive.py for a mostly working example of the proposed API. 📈 🐶 ❤️
 2 Nov 21, 2021
2 Nov 21, 2021

This repository includes the official project for the paper: TransMix: Attend to Mix for Vision Transformers.
TransMix: Attend to Mix for Vision Transformers This repository includes the official project for the paper: TransMix: Attend to Mix for Vision Transf
 32 Nov 21, 2021
32 Nov 21, 2021
A deep learning object detector framework written in Python for supporting Land Search and Rescue Missions.
AIR: Aerial Inspection RetinaNet for supporting Land Search and Rescue Missions AIR is a deep learning based object detection solution to automate the
 13 Dec 22, 2022
13 Dec 22, 2022
This repository includes the official project for the paper: TransMix: Attend to Mix for Vision Transformers.
TransMix: Attend to Mix for Vision Transformers This repository includes the official project for the paper: TransMix: Attend to Mix for Vision Transf
130 Jan 1, 2023

A very simple baseline to estimate 2D & 3D SMPL-compatible keypoints from a single color image.
Minimal Body A very simple baseline to estimate 2D & 3D SMPL-compatible keypoints from a single color image. The model file is only 51.2 MB and runs a
49 Dec 5, 2022

An pytorch implementation of Masked Autoencoders Are Scalable Vision Learners
An pytorch implementation of Masked Autoencoders Are Scalable Vision Learners This is a coarse version for MAE, only make the pretrain model, the fine
 214 Dec 29, 2022
214 Dec 29, 2022
Official PyTorch implementation of DD3D: Is Pseudo-Lidar needed for Monocular 3D Object detection? (ICCV 2021), Dennis Park*, Rares Ambrus*, Vitor Guizilini, Jie Li, and Adrien Gaidon.
DD3D: "Is Pseudo-Lidar needed for Monocular 3D Object detection?" Install // Datasets // Experiments // Models // License // Reference Full video Offi
 364 Dec 27, 2022
364 Dec 27, 2022
PyTorch implementation of Masked Autoencoders Are Scalable Vision Learners for self-supervised ViT.
MAE for Self-supervised ViT Introduction This is an unofficial PyTorch implementation of Masked Autoencoders Are Scalable Vision Learners for self-sup
 36 Oct 30, 2022
36 Oct 30, 2022
AgeGuesser: deep learning based age estimation system. Powered by EfficientNet and Yolov5
AgeGuesser AgeGuesser is an end-to-end, deep-learning based Age Estimation system, presented at the CAIP 2021 conference. You can find the related pap
 5 Nov 10, 2022
5 Nov 10, 2022
Generating Videos with Scene Dynamics
Generating Videos with Scene Dynamics This repository contains an implementation of Generating Videos with Scene Dynamics by Carl Vondrick, Hamed Pirs
 706 Jan 4, 2023
706 Jan 4, 2023
Stacked Generative Adversarial Networks
Stacked Generative Adversarial Networks This repository contains code for the paper "Stacked Generative Adversarial Networks", CVPR 2017. Part of the
 241 May 7, 2022
241 May 7, 2022

MoCoGAN: Decomposing Motion and Content for Video Generation
MoCoGAN: Decomposing Motion and Content for Video Generation This repository contains an implementation and further details of MoCoGAN: Decomposing Mo
 514 Dec 18, 2022
514 Dec 18, 2022

🔥3D-RecGAN in Tensorflow (ICCV Workshops 2017)
3D Object Reconstruction from a Single Depth View with Adversarial Learning Bo Yang, Hongkai Wen, Sen Wang, Ronald Clark, Andrew Markham, Niki Trigoni
 125 Nov 26, 2022
125 Nov 26, 2022

Official Chainer implementation of GP-GAN: Towards Realistic High-Resolution Image Blending (ACMMM 2019, oral)
GP-GAN: Towards Realistic High-Resolution Image Blending (ACMMM 2019, oral) [Project] [Paper] [Demo] [Related Work: A2RL (for Auto Image Cropping)] [C
 402 Dec 27, 2022
402 Dec 27, 2022
![[CVPR 2016] Unsupervised Feature Learning by Image Inpainting using GANs](https://github.com/pathak22/context-encoder/raw/master/images/teaser.jpg)
[CVPR 2016] Unsupervised Feature Learning by Image Inpainting using GANs
Context Encoders: Feature Learning by Inpainting CVPR 2016 [Project Website] [Imagenet Results] Sample results on held-out images: This is the trainin
 829 Dec 31, 2022
829 Dec 31, 2022

Software that can generate photos from paintings, turn horses into zebras, perform style transfer, and more.
CycleGAN PyTorch | project page | paper Torch implementation for learning an image-to-image translation (i.e. pix2pix) without input-output pairs, for
 11.5k Dec 30, 2022
11.5k Dec 30, 2022

Image-to-image translation with conditional adversarial nets
pix2pix Project | Arxiv | PyTorch Torch implementation for learning a mapping from input images to output images, for example: Image-to-Image Translat
 9.3k Jan 8, 2023
9.3k Jan 8, 2023
A simple interface for editing natural photos with generative neural networks.
Neural Photo Editor A simple interface for editing natural photos with generative neural networks. This repository contains code for the paper "Neural
 2.1k Dec 29, 2022
2.1k Dec 29, 2022

Interactive Image Generation via Generative Adversarial Networks
iGAN: Interactive Image Generation via Generative Adversarial Networks Project | Youtube | Paper Recent projects: [pix2pix]: Torch implementation for
3.9k Dec 23, 2022
FCOS: Fully Convolutional One-Stage Object Detection (ICCV'19)
FCOS: Fully Convolutional One-Stage Object Detection This project hosts the code for implementing the FCOS algorithm for object detection, as presente
 3.1k Jan 5, 2023
3.1k Jan 5, 2023

Powerful and efficient Computer Vision Annotation Tool (CVAT)
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 1, 2023
8.6k Jan 1, 2023

🔎 Super-scale your images and run experiments with Residual Dense and Adversarial Networks.
Image Super-Resolution (ISR) The goal of this project is to upscale and improve the quality of low resolution images. This project contains Keras impl
 4k Jan 8, 2023
4k Jan 8, 2023

Gesture Volume Control Using OpenCV and MediaPipe
This Project Uses OpenCV and MediaPipe Hand solutions to identify hands and Change system volume by taking thumb and index finger positions
 6 Sep 12, 2022
6 Sep 12, 2022
Official implementation for "Image Quality Assessment using Contrastive Learning"
Image Quality Assessment using Contrastive Learning Pavan C. Madhusudana, Neil Birkbeck, Yilin Wang, Balu Adsumilli and Alan C. Bovik This is the offi
 67 Dec 30, 2022
67 Dec 30, 2022
Implementation of the master's thesis "Temporal copying and local hallucination for video inpainting".
Temporal copying and local hallucination for video inpainting This repository contains the implementation of my master's thesis "Temporal copying and
 1 Dec 2, 2022
1 Dec 2, 2022

Pytorch implementation of forward and inverse Haar Wavelets 2D
Pytorch implementation of forward and inverse Haar Wavelets 2D
 9 Oct 30, 2022
9 Oct 30, 2022
A clean and extensible PyTorch implementation of Masked Autoencoders Are Scalable Vision Learners
A clean and extensible PyTorch implementation of Masked Autoencoders Are Scalable Vision Learners A PyTorch re-implementation of Mask Autoencoder trai
 23 Dec 13, 2022
23 Dec 13, 2022

PyTorch implementation of MulMON
MulMON This repository contains a PyTorch implementation of the paper: Learning Object-Centric Representations of Multi-object Scenes from Multiple Vi
 16 Nov 3, 2022
16 Nov 3, 2022

Summary of related papers on visual attention
This repo is built for paper: Attention Mechanisms in Computer Vision: A Survey paper Vision-Attention-Papers Channel attention Spatial attention Temp
 2.1k Dec 30, 2022
2.1k Dec 30, 2022
Open source hardware and software platform to build a small scale self driving car.
Donkeycar is minimalist and modular self driving library for Python. It is developed for hobbyists and students with a focus on allowing fast experimentation and easy community contributions.
 2.4k Jan 4, 2023
2.4k Jan 4, 2023
🚪✊Knock Knock: Get notified when your training ends with only two additional lines of code
Knock Knock A small library to get a notification when your training is complete or when it crashes during the process with two additional lines of co
 2.5k Jan 7, 2023
2.5k Jan 7, 2023

Gated-Shape CNN for Semantic Segmentation (ICCV 2019)
GSCNN This is the official code for: Gated-SCNN: Gated Shape CNNs for Semantic Segmentation Towaki Takikawa, David Acuna, Varun Jampani, Sanja Fidler
 859 Dec 26, 2022
859 Dec 26, 2022
UPSNet: A Unified Panoptic Segmentation Network
UPSNet: A Unified Panoptic Segmentation Network Introduction UPSNet is initially described in a CVPR 2019 oral paper. Disclaimer This repository is te
 622 Dec 26, 2022
622 Dec 26, 2022

Learning to Adapt Structured Output Space for Semantic Segmentation, CVPR 2018 (spotlight)
Learning to Adapt Structured Output Space for Semantic Segmentation Pytorch implementation of our method for adapting semantic segmentation from the s
 782 Dec 30, 2022
782 Dec 30, 2022

A Kitti Road Segmentation model implemented in tensorflow.
KittiSeg KittiSeg performs segmentation of roads by utilizing an FCN based model. The model achieved first place on the Kitti Road Detection Benchmark
 890 Jan 4, 2023
890 Jan 4, 2023

Real-time Joint Semantic Reasoning for Autonomous Driving
MultiNet MultiNet is able to jointly perform road segmentation, car detection and street classification. The model achieves real-time speed and state-
518 Dec 12, 2022
Keras implementation of Real-Time Semantic Segmentation on High-Resolution Images
Keras-ICNet [paper] Keras implementation of Real-Time Semantic Segmentation on High-Resolution Images. Training in progress! Requisites Python 3.6.3 K
 87 Dec 16, 2022
87 Dec 16, 2022

TensorFlow implementation of ENet
TensorFlow-ENet TensorFlow implementation of ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. This model was tested on th
 255 Oct 17, 2022
255 Oct 17, 2022
TensorFlow implementation of ENet, trained on the Cityscapes dataset.
segmentation TensorFlow implementation of ENet (https://arxiv.org/pdf/1606.02147.pdf) based on the official Torch implementation (https://github.com/e
 248 Dec 16, 2022
248 Dec 16, 2022
Fully convolutional networks for semantic segmentation
FCN-semantic-segmentation Simple end-to-end semantic segmentation using fully convolutional networks [1]. Takes a pretrained 34-layer ResNet [2], remo
 186 Dec 25, 2022
186 Dec 25, 2022

Chainer Implementation of Fully Convolutional Networks. (Training code to reproduce the original result is available.)
fcn - Fully Convolutional Networks Chainer implementation of Fully Convolutional Networks. Installation pip install fcn Inference Inference is done as
 218 Oct 27, 2022
218 Oct 27, 2022
TorchCV: A PyTorch-Based Framework for Deep Learning in Computer Vision
TorchCV: A PyTorch-Based Framework for Deep Learning in Computer Vision @misc{you2019torchcv, author = {Ansheng You and Xiangtai Li and Zhen Zhu a
 2.2k Jan 6, 2023
2.2k Jan 6, 2023
SegNet-like Autoencoders in TensorFlow
SegNet SegNet is a TensorFlow implementation of the segmentation network proposed by Kendall et al., with cool features like strided deconvolution, a
 66 Nov 5, 2021
66 Nov 5, 2021

Semantic segmentation models, datasets and losses implemented in PyTorch.
Semantic Segmentation in PyTorch Semantic Segmentation in PyTorch Requirements Main Features Models Datasets Losses Learning rate schedulers Data augm
 1.3k Jan 7, 2023
1.3k Jan 7, 2023

Anime Face Detector using mmdet and mmpose
Anime Face Detector This is an anime face detector using mmdetection and mmpose. (To avoid copyright issues, I use generated images by the TADNE model
 198 Jan 7, 2023
198 Jan 7, 2023

History Aware Multimodal Transformer for Vision-and-Language Navigation
History Aware Multimodal Transformer for Vision-and-Language Navigation This repository is the official implementation of History Aware Multimodal Tra
 46 Nov 23, 2022
46 Nov 23, 2022
Unofficial PyTorch implementation of Masked Autoencoders Are Scalable Vision Learners
Unofficial PyTorch implementation of Masked Autoencoders Are Scalable Vision Learners This repository is built upon BEiT, thanks very much! Now, we on
 2.3k Jan 4, 2023
2.3k Jan 4, 2023
Coursework project for DIP class. The goal is to use vision to guide the Dashgo robot through two traffic cones in bright color.
Coursework project for DIP class. The goal is to use vision to guide the Dashgo robot through two traffic cones in bright color.
 3 Oct 24, 2022
3 Oct 24, 2022

ML for NLP and Computer Vision.
Sparrow is our open-source ML product. It runs on Skipper MLOps infrastructure.
 2 Nov 28, 2021
2 Nov 28, 2021
History Aware Multimodal Transformer for Vision-and-Language Navigation
History Aware Multimodal Transformer for Vision-and-Language Navigation This repository is the official implementation of History Aware Multimodal Tra
46 Nov 23, 2022
A program that uses computer vision to detect hand gestures, used for controlling movie players.
HandGestureDetection This program uses a Haar Cascade algorithm to detect the presence of your hand, and then passes it on to a self-created and self-
 2 Nov 22, 2022
2 Nov 22, 2022
A free, multiplatform SDK for real-time facial motion capture using blendshapes, and rigid head pose in 3D space from any RGB camera, photo, or video.
mocap4face by Facemoji mocap4face by Facemoji is a free, multiplatform SDK for real-time facial motion capture based on Facial Action Coding System or
 591 Dec 27, 2022
591 Dec 27, 2022

This repo. is an implementation of ACFFNet, which is accepted for in Image and Vision Computing.
Attention-Guided-Contextual-Feature-Fusion-Network-for-Salient-Object-Detection This repo. is an implementation of ACFFNet, which is accepted for in I
 5 Nov 21, 2022
5 Nov 21, 2022

Multi View Stereo on Internet Images
Evaluating MVS in a CPC Scenario This repository contains the set of artficats used for the ENGN8601/8602 research project. The thesis emphasizes on t
 1 Nov 10, 2021
1 Nov 10, 2021

Investigating automatic navigation towards standard US views integrating MARL with the virtual US environment developed in CT2US simulation
AutomaticUSnavigation Investigating automatic navigation towards standard US views integrating MARL with the virtual US environment developed in CT2US
 6 Dec 5, 2022
6 Dec 5, 2022

Image Segmentation using U-Net, U-Net with skip connections and M-Net architectures
Brain-Image-Segmentation Segmentation of brain tissues in MRI image has a number of applications in diagnosis, surgical planning, and treatment of bra
 8 Oct 27, 2022
8 Oct 27, 2022

Official Code Release for "TIP-Adapter: Training-free clIP-Adapter for Better Vision-Language Modeling"
Official Code Release for "TIP-Adapter: Training-free clIP-Adapter for Better Vision-Language Modeling" Pipeline of Tip-Adapter Tip-Adapter can provid
 187 Dec 28, 2022
187 Dec 28, 2022

Laser device for neutralizing - mosquitoes, weeds and pests
Laser device for neutralizing - mosquitoes, weeds and pests (in progress) Here I will post information for creating a laser device. A warning!! How It
 1k Jan 2, 2023
1k Jan 2, 2023

A set of tools to pre-calibrate and calibrate (multi-focus) plenoptic cameras (e.g., a Raytrix R12) based on the libpleno.
COMPOTE: Calibration Of Multi-focus PlenOpTic camEra. COMPOTE is a set of tools to pre-calibrate and calibrate (multifocus) plenoptic cameras (e.g., a
 4 May 10, 2022
4 May 10, 2022

Certified Patch Robustness via Smoothed Vision Transformers
Certified Patch Robustness via Smoothed Vision Transformers This repository contains the code for replicating the results of our paper: Certified Patc
 35 Dec 14, 2022
35 Dec 14, 2022
[ICCV 2021 Oral] Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Just Ask: Learning to Answer Questions from Millions of Narrated Videos Webpage • Demo • Paper This repository provides the code for our paper, includ
 87 Jan 5, 2023
87 Jan 5, 2023
![[ICCV'21] Pri3D: Can 3D Priors Help 2D Representation Learning?](https://github.com/Sekunde/Pri3D/raw/main/assets/pri3d.jpg)
[ICCV'21] Pri3D: Can 3D Priors Help 2D Representation Learning?
Pri3D: Can 3D Priors Help 2D Representation Learning? [ICCV 2021] Pri3D leverages 3D priors for downstream 2D image understanding tasks: during pre-tr
 124 Jan 6, 2023
124 Jan 6, 2023