401 Repositories
Python visual-localization Libraries
Code for Greedy Gradient Ensemble for Visual Question Answering (ICCV 2021, Oral)
Greedy Gradient Ensemble for De-biased VQA Code release for "Greedy Gradient Ensemble for Robust Visual Question Answering" (ICCV 2021, Oral). GGE can
 21 Jun 29, 2022
21 Jun 29, 2022
This repo holds codes of the ICCV21 paper: Visual Alignment Constraint for Continuous Sign Language Recognition.
VAC_CSLR This repo holds codes of the paper: Visual Alignment Constraint for Continuous Sign Language Recognition.(ICCV 2021) [paper] Prerequisites Th
 64 Dec 19, 2022
64 Dec 19, 2022
PyTorch implementation of Spiking Neural Networks trained on surrogate gradient & BPTT using snntorch.
snn-localization repo PyTorch implementation of Spiking Neural Networks trained on surrogate gradient & BPTT using snntorch. Install Dependencies Orig
 1 Jan 6, 2022
1 Jan 6, 2022
A small python library that helps you to generate localization strings for your mobile projects.
LocalizationUtiltiy A small python library that helps you to generate localization strings for your mobile projects. This small script aims to help yo
 1 Nov 12, 2021
1 Nov 12, 2021

Code for BMVC2021 "MOS: A Low Latency and Lightweight Framework for Face Detection, Landmark Localization, and Head Pose Estimation"
MOS-Multi-Task-Face-Detect Introduction This repo is the official implementation of "MOS: A Low Latency and Lightweight Framework for Face Detection,
 104 Dec 8, 2022
104 Dec 8, 2022

Distilling Motion Planner Augmented Policies into Visual Control Policies for Robot Manipulation (CoRL 2021)
Distilling Motion Planner Augmented Policies into Visual Control Policies for Robot Manipulation [Project website] [Paper] This project is a PyTorch i
 6 Feb 28, 2022
6 Feb 28, 2022

SW components and demos for visual kinship recognition. An emphasis is put on the FIW dataset-- data loaders, benchmarks, results in summary.
FIW Data Development Kit Table of Contents Introduction Families In the Wild Database Publications Organization To Do License Getting Involved Introdu
 12 Jun 4, 2022
12 Jun 4, 2022

A treasure chest for visual recognition powered by PaddlePaddle
简体中文 | English PaddleClas 简介 飞桨图像识别套件PaddleClas是飞桨为工业界和学术界所准备的一个图像识别任务的工具集,助力使用者训练出更好的视觉模型和应用落地。 近期更新 2021.11.1 发布PP-ShiTu技术报告,新增饮料识别demo 2021.10.23 发
 4.6k Dec 31, 2022
4.6k Dec 31, 2022
The code for MM2021 paper "Multi-Level Counterfactual Contrast for Visual Commonsense Reasoning"
The Code for MM2021 paper "Multi-Level Counterfactual Contrast for Visual Commonsense Reasoning" Setting up and using the repo Get the dataset. Follow
 4 Apr 20, 2022
4 Apr 20, 2022
[IROS2021] NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
NYU-VPR This repository provides the experiment code for the paper Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymiza
 22 Sep 28, 2022
22 Sep 28, 2022

Code for the paper "Zero-shot Natural Language Video Localization" (ICCV2021, Oral).
Zero-shot Natural Language Video Localization (ZSNLVL) by Pseudo-Supervised Video Localization (PSVL) This repository is for Zero-shot Natural Languag
 37 Dec 27, 2022
37 Dec 27, 2022

Dynamic Visual Reasoning by Learning Differentiable Physics Models from Video and Language (NeurIPS 2021)
VRDP (NeurIPS 2021) Dynamic Visual Reasoning by Learning Differentiable Physics Models from Video and Language Mingyu Ding, Zhenfang Chen, Tao Du, Pin
 36 Sep 20, 2022
36 Sep 20, 2022
Dist2Dec: A Simplicial Neural Network for Homology Localization
Dist2Dec: A Simplicial Neural Network for Homology Localization
 6 Jun 12, 2022
6 Jun 12, 2022
Code Release for the paper "TriBERT: Full-body Human-centric Audio-visual Representation Learning for Visual Sound Separation"
TriBERT This repository contains the code for the NeurIPS 2021 paper titled "TriBERT: Full-body Human-centric Audio-visual Representation Learning for
 8 Aug 31, 2022
8 Aug 31, 2022
Audio Visual Emotion Recognition using TDA
Audio Visual Emotion Recognition using TDA RAVDESS database with two datasets analyzed: Video and Audio dataset: Audio-Dataset: https://www.kaggle.com
 3 May 11, 2022
3 May 11, 2022

Official implementation of NeurIPS 2021 paper "Contextual Similarity Aggregation with Self-attention for Visual Re-ranking"
CSA: Contextual Similarity Aggregation with Self-attention for Visual Re-ranking PyTorch training code for CSA (Contextual Similarity Aggregation). We
 19 Oct 21, 2022
19 Oct 21, 2022

The official codes for the ICCV2021 Oral presentation "Rethinking Counting and Localization in Crowds: A Purely Point-Based Framework"
P2PNet (ICCV2021 Oral Presentation) This repository contains codes for the official implementation in PyTorch of P2PNet as described in Rethinking Cou
 208 Dec 26, 2022
208 Dec 26, 2022
This repository contains code and data for "On the Multimodal Person Verification Using Audio-Visual-Thermal Data"
trimodal_person_verification This repository contains the code, and preprocessed dataset featured in "A Study of Multimodal Person Verification Using
 7 Aug 31, 2022
7 Aug 31, 2022

A Context-aware Visual Attention-based training pipeline for Object Detection from a Webpage screenshot!
CoVA: Context-aware Visual Attention for Webpage Information Extraction Abstract Webpage information extraction (WIE) is an important step to create k
 41 Jan 1, 2023
41 Jan 1, 2023

Efficient Training of Visual Transformers with Small Datasets
Official codes for "Efficient Training of Visual Transformers with Small Datasets", NerIPS 2021.
 112 Dec 25, 2022
112 Dec 25, 2022
Official implementation of NeurIPS 2021 paper "Contextual Similarity Aggregation with Self-attention for Visual Re-ranking"
CSA: Contextual Similarity Aggregation with Self-attention for Visual Re-ranking PyTorch training code for CSA (Contextual Similarity Aggregation). We
19 Oct 21, 2022

This repository is the official implementation of Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regularized Fine-Tuning (NeurIPS21).
Core-tuning This repository is the official implementation of ``Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regular
 18 Dec 17, 2022
18 Dec 17, 2022
Code for the bachelors-thesis flaky fault localization
Flaky_Fault_Localization Scripts for the Bachelors-Thesis: "Flaky Fault Localization" by Christian Kasberger. The thesis examines the usefulness of sp
 1 Oct 26, 2021
1 Oct 26, 2021
VOneNet: CNNs with a Primary Visual Cortex Front-End
VOneNet: CNNs with a Primary Visual Cortex Front-End A family of biologically-inspired Convolutional Neural Networks (CNNs). VOneNets have the followi
 99 Dec 22, 2022
99 Dec 22, 2022

BMVC 2021: This is the github repository for "Few Shot Temporal Action Localization using Query Adaptive Transformers" accepted in British Machine Vision Conference (BMVC) 2021, Virtual
FS-QAT: Few Shot Temporal Action Localization using Query Adaptive Transformer Accepted as Poster in BMVC 2021 This is an official implementation in P
 14 Dec 9, 2022
14 Dec 9, 2022
The official PyTorch implementation of paper BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition Boyan Zhou, Quan Cui, Xiu-Shen Wei*, Zhao-Min Chen This repo
 616 Dec 21, 2022
616 Dec 21, 2022

JittorVis - Visual understanding of deep learning models
JittorVis: Visual understanding of deep learning model JittorVis is an open-source library for understanding the inner workings of Jittor models by vi
 182 Jan 6, 2023
182 Jan 6, 2023

A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning
CLEVR Dataset Generation This is the code used to generate the CLEVR dataset as described in the paper: CLEVR: A Diagnostic Dataset for Compositional
 503 Jan 4, 2023
503 Jan 4, 2023
pytorch implementation of "Contrastive Multiview Coding", "Momentum Contrast for Unsupervised Visual Representation Learning", and "Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination"
Unofficial implementation: MoCo: Momentum Contrast for Unsupervised Visual Representation Learning (Paper) InsDis: Unsupervised Feature Learning via N
 16 Nov 4, 2020
16 Nov 4, 2020

Code for "Localization with Sampling-Argmax", NeurIPS 2021
Localization with Sampling-Argmax [Paper] [arXiv] [Project Page] Localization with Sampling-Argmax Jiefeng Li, Tong Chen, Ruiqi Shi, Yujing Lou, Yong-
 71 Dec 17, 2022
71 Dec 17, 2022

Official implementation of deep-multi-trajectory-based single object tracking (IEEE T-CSVT 2021).
DeepMTA_PyTorch Officical PyTorch Implementation of "Dynamic Attention-guided Multi-TrajectoryAnalysis for Single Object Tracking", Xiao Wang, Zhe Che
 7 Dec 3, 2022
7 Dec 3, 2022

Official PyTorch implementation of PICCOLO: Point-Cloud Centric Omnidirectional Localization (ICCV 2021)
Official PyTorch implementation of PICCOLO: Point-Cloud Centric Omnidirectional Localization (ICCV 2021)
 16 Nov 19, 2022
16 Nov 19, 2022
Official implementation of A cappella: Audio-visual Singing VoiceSeparation, from BMVC21
Y-Net Official implementation of A cappella: Audio-visual Singing VoiceSeparation, British Machine Vision Conference 2021 Project page: ipcv.github.io
 12 Oct 22, 2022
12 Oct 22, 2022
Official implementation of A cappella: Audio-visual Singing VoiceSeparation, from BMVC21
Y-Net Official implementation of A cappella: Audio-visual Singing VoiceSeparation, British Machine Vision Conference 2021 Project page: ipcv.github.io
12 Oct 22, 2022
The official implementation of CVPR 2021 Paper: Improving Weakly Supervised Visual Grounding by Contrastive Knowledge Distillation.
Improving Weakly Supervised Visual Grounding by Contrastive Knowledge Distillation This repository is the official implementation of CVPR 2021 paper:
 9 Nov 14, 2022
9 Nov 14, 2022
SGoLAM - Simultaneous Goal Localization and Mapping
SGoLAM - Simultaneous Goal Localization and Mapping PyTorch implementation of the MultiON runner-up entry, SGoLAM: Simultaneous Goal Localization and
 10 Jan 5, 2023
10 Jan 5, 2023
Graph Convolutional Networks for Temporal Action Localization (ICCV2019)
Graph Convolutional Networks for Temporal Action Localization This repo holds the codes and models for the PGCN framework presented on ICCV 2019 Graph
 318 Dec 6, 2022
318 Dec 6, 2022

The code is an implementation of Feedback Convolutional Neural Network for Visual Localization and Segmentation.
Feedback Convolutional Neural Network for Visual Localization and Segmentation The code is an implementation of Feedback Convolutional Neural Network
 19 Dec 4, 2022
19 Dec 4, 2022
Code for Efficient Visual Pretraining with Contrastive Detection
Code for DetCon This repository contains code for the ICCV 2021 paper "Efficient Visual Pretraining with Contrastive Detection" by Olivier J. Hénaff,
 56 Nov 13, 2022
56 Nov 13, 2022

Implementation of ICCV21 paper: PnP-DETR: Towards Efficient Visual Analysis with Transformers
Implementation of ICCV 2021 paper: PnP-DETR: Towards Efficient Visual Analysis with Transformers arxiv This repository is based on detr Recently, DETR
 113 Dec 27, 2022
113 Dec 27, 2022
ImageNet-CoG is a benchmark for concept generalization. It provides a full evaluation framework for pre-trained visual representations which measure how well they generalize to unseen concepts.
The ImageNet-CoG Benchmark Project Website Paper (arXiv) Code repository for the ImageNet-CoG Benchmark introduced in the paper "Concept Generalizatio
 23 Oct 9, 2022
23 Oct 9, 2022

Revitalizing CNN Attention via Transformers in Self-Supervised Visual Representation Learning
Revitalizing CNN Attention via Transformers in Self-Supervised Visual Representation Learning This repository is the official implementation of CARE.
 18 Oct 13, 2021
18 Oct 13, 2021
Official repository of PanoAVQA: Grounded Audio-Visual Question Answering in 360° Videos (ICCV 2021)
Pano-AVQA Official repository of PanoAVQA: Grounded Audio-Visual Question Answering in 360° Videos (ICCV 2021) [Paper] [Poster] [Video] Getting Starte
 9 Dec 23, 2022
9 Dec 23, 2022
Repo for EchoVPR: Echo State Networks for Visual Place Recognition
EchoVPR Repo for EchoVPR: Echo State Networks for Visual Place Recognition Currently under development Dirs: data: pre-collected hidden representation
 4 Oct 4, 2022
4 Oct 4, 2022

Official implementation for Multi-Modal Interaction Graph Convolutional Network for Temporal Language Localization in Videos
Multi-modal Interaction Graph Convolutioal Network for Temporal Language Localization in Videos Official implementation for Multi-Modal Interaction Gr
 15 Oct 18, 2022
15 Oct 18, 2022
Revitalizing CNN Attention via Transformers in Self-Supervised Visual Representation Learning
Revitalizing CNN Attention via Transformers in Self-Supervised Visual Representation Learning
89 Dec 2, 2022

Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation
Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation The code repository for "Audio-Visual Generalized Few-Shot Learning with
 3 Jun 27, 2022
3 Jun 27, 2022
COVINS -- A Framework for Collaborative Visual-Inertial SLAM and Multi-Agent 3D Mapping
COVINS -- A Framework for Collaborative Visual-Inertial SLAM and Multi-Agent 3D Mapping Version 1.0 COVINS is an accurate, scalable, and versatile vis
 183 Dec 27, 2022
183 Dec 27, 2022

This is the official pytorch implementation for our ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visual Question Answering" on VQA Task
🌈 ERASOR (RA-L'21 with ICRA Option) Official page of "ERASOR: Egocentric Ratio of Pseudo Occupancy-based Dynamic Object Removal for Static 3D Point C
 225 Dec 29, 2022
225 Dec 29, 2022

Pytorch implementation for our ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visual Question Answering".
TRAnsformer Routing Networks (TRAR) This is an official implementation for ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visu
 49 Nov 10, 2022
49 Nov 10, 2022

A PyTorch implementation of "From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network" (ICCV2021)
From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network The official code of VisionLAN (ICCV2021). VisionLAN successfully a
 81 Dec 12, 2022
81 Dec 12, 2022
Official implementation of Influence-balanced Loss for Imbalanced Visual Classification in PyTorch.
Official implementation of Influence-balanced Loss for Imbalanced Visual Classification in PyTorch.
 70 Jan 3, 2023
70 Jan 3, 2023

We utilize deep reinforcement learning to obtain favorable trajectories for visual-inertial system calibration.
Unified Data Collection for Visual-Inertial Calibration via Deep Reinforcement Learning Update: The lastest code will be updated in this branch. Pleas
 27 Dec 29, 2022
27 Dec 29, 2022
AryaBota: An app to teach Python coding via gradual programming and visual output
AryaBota An app to teach Python coding, that gradually allows students to transition from using commands similar to natural language, to more Pythonic
 5 Feb 8, 2022
5 Feb 8, 2022
A Fast and Accurate One-Stage Approach to Visual Grounding, ICCV 2019 (Oral)
One-Stage Visual Grounding ***** New: Our recent work on One-stage VG is available at ReSC.***** A Fast and Accurate One-Stage Approach to Visual Grou
 118 Dec 5, 2022
118 Dec 5, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
 166 Dec 11, 2022
166 Dec 11, 2022

DSAC* for Visual Camera Re-Localization (RGB or RGB-D)
DSAC* for Visual Camera Re-Localization (RGB or RGB-D) Introduction Installation Data Structure Supported Datasets 7Scenes 12Scenes Cambridge Landmark
 143 Dec 22, 2022
143 Dec 22, 2022

Line as a Visual Sentence: Context-aware Line Descriptor for Visual Localization
Line as a Visual Sentence with LineTR This repository contains the inference code, pretrained model, and demo scripts of the following paper. It suppo
 158 Dec 27, 2022
158 Dec 27, 2022
This reporistory contains the test-dev data of the paper "xGQA: Cross-lingual Visual Question Answering".
This reporistory contains the test-dev data of the paper "xGQA: Cross-lingual Visual Question Answering".
 18 Dec 9, 2022
18 Dec 9, 2022
![[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification](https://github.com/raoyongming/CAL/raw/master/figs/intro.png)
[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Counterfactual Attention Learning Created by Yongming Rao*, Guangyi Chen*, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for ICCV
 90 Dec 31, 2022
90 Dec 31, 2022

Code and data for "Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning" (EMNLP 2021).
GD-VCR Code for Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning (EMNLP 2021). Research Questions and Aims: How well can a model perform o
 24 Oct 13, 2022
24 Oct 13, 2022
Official Implementation of Few-shot Visual Relationship Co-localization
VRC Official implementation of the Few-shot Visual Relationship Co-localization (ICCV 2021) paper project page | paper Requirements Use python = 3.8.
 22 Oct 13, 2022
22 Oct 13, 2022
[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Counterfactual Attention Learning Created by Yongming Rao*, Guangyi Chen*, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for ICCV
89 Dec 18, 2022
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
 1.7k Dec 28, 2022
1.7k Dec 28, 2022

Normalization Matters in Weakly Supervised Object Localization (ICCV 2021)
Normalization Matters in Weakly Supervised Object Localization (ICCV 2021) 99% of the code in this repository originates from this link. ICCV 2021 pap
 10 Feb 1, 2022
10 Feb 1, 2022

Cockpit is a visual and statistical debugger specifically designed for deep learning.
Cockpit: A Practical Debugging Tool for Training Deep Neural Networks
 421 Dec 29, 2022
421 Dec 29, 2022
[ICCV 2021] Released code for Causal Attention for Unbiased Visual Recognition
CaaM This repo contains the codes of training our CaaM on NICO/ImageNet9 dataset. Due to my recent limited bandwidth, this codebase is still messy, wh
 66 Dec 31, 2022
66 Dec 31, 2022

This repo implements a Topological SLAM: Deep Visual Odometry with Long Term Place Recognition (Loop Closure Detection)
This repo implements a topological SLAM system. Deep Visual Odometry (DF-VO) and Visual Place Recognition are combined to form the topological SLAM system.
 32 Jun 23, 2022
32 Jun 23, 2022

🌈 PyTorch Implementation for EMNLP'21 Findings "Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer"
SGLKT-VisDial Pytorch Implementation for the paper: Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer Gi-Cheon Kang, Junseok P
 9 Jul 5, 2022
9 Jul 5, 2022

PaddleViT: State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 2.0+
PaddlePaddle Vision Transformers State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 🤖 PaddlePaddle Visual Transformers (PaddleViT or
 1k Dec 28, 2022
1k Dec 28, 2022

The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation
PointNav-VO The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation Project Page | Paper Table of Contents Setup
 41 Dec 15, 2022
41 Dec 15, 2022
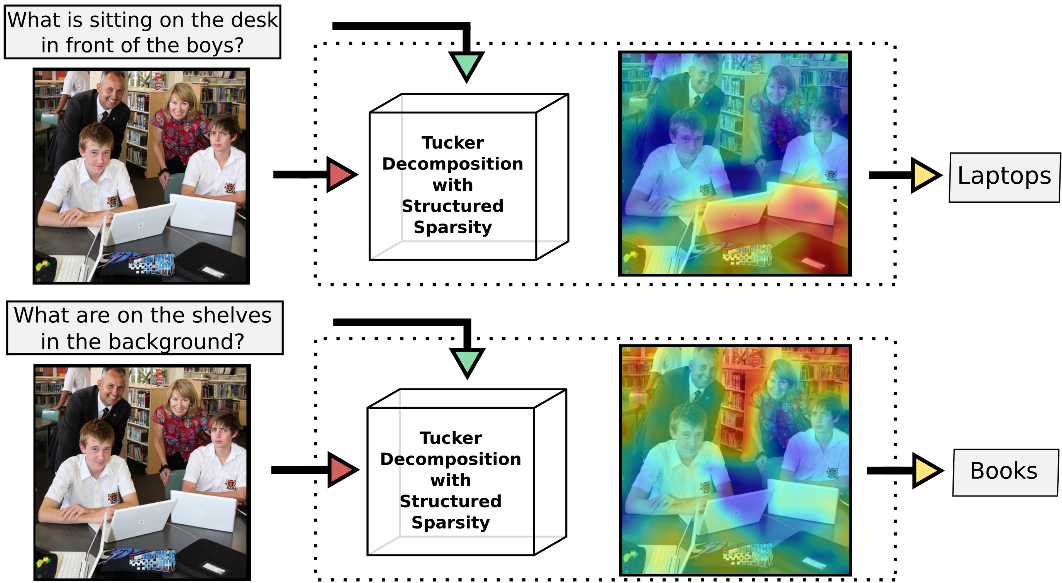
Visual Question Answering in Pytorch
Visual Question Answering in pytorch /!\ New version of pytorch for VQA available here: https://github.com/Cadene/block.bootstrap.pytorch This repo wa
 672 Jan 1, 2023
672 Jan 1, 2023
PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
Improving Visual-Semantic Embeddings with Hard Negatives Code for the image-caption retrieval methods from VSE++: Improving Visual-Semantic Embeddings
 441 Dec 5, 2022
441 Dec 5, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
166 Dec 11, 2022
Official PyTorch code for WACV 2022 paper "CFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows"
CFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows WACV 2022 preprint:https://arxiv.org/abs/2107.1
 156 Dec 28, 2022
156 Dec 28, 2022

Official Pytorch Implementation of 'Learning Action Completeness from Points for Weakly-supervised Temporal Action Localization' (ICCV-21 Oral)
Learning-Action-Completeness-from-Points Official Pytorch Implementation of 'Learning Action Completeness from Points for Weakly-supervised Temporal A
 67 Jan 3, 2023
67 Jan 3, 2023

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022
A management system designed for the employees of MIRAS (Art Gallery). It is used to sell/cancel tickets, book/cancel events and keeps track of all upcoming events.
Art-Galleria-Management-System Its a management system designed for the employees of MIRAS (Art Gallery). Backend : Python Frontend : Django Database
 8 Nov 30, 2022
8 Nov 30, 2022

A weakly-supervised scene graph generation codebase. The implementation of our CVPR2021 paper ``Linguistic Structures as Weak Supervision for Visual Scene Graph Generation''
README.md shall be finished soon. WSSGG 0 Overview 1 Installation 1.1 Faster-RCNN 1.2 Language Parser 1.3 GloVe Embeddings 2 Settings 2.1 VG-GT-Graph
 35 Nov 20, 2022
35 Nov 20, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
 41 Jan 3, 2023
41 Jan 3, 2023

Code release for The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification (TIP 2020)
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification Code release for The Devil is in the Channels: Mutual-Channel
 230 Dec 31, 2022
230 Dec 31, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023
Video Visual Relation Detection (VidVRD) tracklets generation. also for ACM MM Visual Relation Understanding Grand Challenge
VidVRD-tracklets This repository contains codes for Video Visual Relation Detection (VidVRD) tracklets generation based on MEGA and deepSORT. These tr
 25 Dec 21, 2022
25 Dec 21, 2022

Official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers
Visual Parser (ViP) This is the official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers. Key Feature
 117 Dec 11, 2022
117 Dec 11, 2022
DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021)
DPT This repo is the official implementation of DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021). We provide code and model
 111 Dec 21, 2022
111 Dec 21, 2022
This is the code for CVPR 2021 oral paper: Jigsaw Clustering for Unsupervised Visual Representation Learning
JigsawClustering Jigsaw Clustering for Unsupervised Visual Representation Learning Pengguang Chen, Shu Liu, Jiaya Jia Introduction This project provid
 73 Sep 18, 2022
73 Sep 18, 2022

Dataset used in "PlantDoc: A Dataset for Visual Plant Disease Detection" accepted in CODS-COMAD 2020
PlantDoc: A Dataset for Visual Plant Disease Detection This repository contains the Cropped-PlantDoc dataset used for benchmarking classification mode
 109 Dec 29, 2022
109 Dec 29, 2022

This's an implementation of deepmind Visual Interaction Networks paper using pytorch
Visual-Interaction-Networks An implementation of Deepmind visual interaction networks in Pytorch. Introduction For the purpose of understanding the ch
 166 Dec 6, 2022
166 Dec 6, 2022

PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs
PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs This code aims to reproduce results obtained in the paper "Visual F
 93 Aug 17, 2022
93 Aug 17, 2022

Bilinear attention networks for visual question answering
Bilinear Attention Networks This repository is the implementation of Bilinear Attention Networks for the visual question answering and Flickr30k Entit
 506 Nov 29, 2022
506 Nov 29, 2022

source code of “Visual Saliency Transformer” (ICCV2021)
Visual Saliency Transformer (VST) source code for our ICCV 2021 paper “Visual Saliency Transformer” by Nian Liu, Ni Zhang, Kaiyuan Wan, Junwei Han, an
 89 Dec 21, 2022
89 Dec 21, 2022

🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
 7.7k Jan 5, 2023
7.7k Jan 5, 2023

PyTorch implementation of "Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning"
Transparency-by-Design networks (TbD-nets) This repository contains code for replicating the experiments and visualizations from the paper Transparenc
 351 Nov 18, 2022
351 Nov 18, 2022

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022

URIE: Universal Image Enhancementfor Visual Recognition in the Wild
URIE: Universal Image Enhancementfor Visual Recognition in the Wild This is the implementation of the paper "URIE: Universal Image Enhancement for Vis
 43 Sep 12, 2022
43 Sep 12, 2022
improvement of CLIP features over the traditional resnet features on the visual question answering, image captioning, navigation and visual entailment tasks.
CLIP-ViL In our paper "How Much Can CLIP Benefit Vision-and-Language Tasks?", we show the improvement of CLIP features over the traditional resnet fea
 310 Dec 28, 2022
310 Dec 28, 2022
STMTrack: Template-free Visual Tracking with Space-time Memory Networks
STMTrack This is the official implementation of the paper: STMTrack: Template-free Visual Tracking with Space-time Memory Networks. Setup Prepare Anac
 62 Dec 21, 2022
62 Dec 21, 2022

Delving into Localization Errors for Monocular 3D Object Detection, CVPR'2021
Delving into Localization Errors for Monocular 3D Detection By Xinzhu Ma, Yinmin Zhang, Dan Xu, Dongzhan Zhou, Shuai Yi, Haojie Li, Wanli Ouyang. Intr
 124 Jan 4, 2023
124 Jan 4, 2023
![[CVPR 2021] A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts](https://github.com/gyhandy/Visual-Reasoning-eXplanation/raw/main/docs/Fig-1.png)
[CVPR 2021] A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts
Visual-Reasoning-eXplanation [CVPR 2021 A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts] Project Page | Vid
 54 Dec 21, 2022
54 Dec 21, 2022

Codes for TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised Object Localization.
TS-CAM: Token Semantic Coupled Attention Map for Weakly SupervisedObject Localization This is the official implementaion of paper TS-CAM: Token Semant
 112 Jan 2, 2023
112 Jan 2, 2023