179 Repositories
Python Ocr-Denoiser Libraries

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022

Automatic number plate recognition using tech: Yolo, OCR, Scene text detection, scene text recognation, flask, torch
Automatic Number Plate Recognition Automatic Number Plate Recognition (ANPR) is the process of reading the characters on the plate with various optica
 52 Dec 22, 2022
52 Dec 22, 2022

Optical Character Recognition + Instance Segmentation for russian and english languages
Распознавание рукописного текста в школьных тетрадях Соревнование, проводимое в рамках олимпиады НТО, разработанное Сбером. Платформа ODS. Результаты
 21 Dec 19, 2022
21 Dec 19, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
 327 Jan 1, 2023
327 Jan 1, 2023
Read Japanese manga inside browser with selectable text.
mokuro Read Japanese manga with selectable text inside a browser. See demo: https://kha-white.github.io/manga-demo mokuro_demo.mp4 Demo contains excer
170 Dec 27, 2022

Comparison-of-OCR (KerasOCR, PyTesseract,EasyOCR)
Optical Character Recognition OCR (Optical Character Recognition) is a technology that enables the conversion of document types such as scanned paper
21 Dec 25, 2022
Digitalizing-Prescription-Image - PIRDS - Prescription Image Recognition and Digitalizing System is a OCR make with Tensorflow
Digitalizing-Prescription-Image PIRDS - Prescription Image Recognition and Digit
 2 May 11, 2022
2 May 11, 2022
Select range and every time the screen changes, OCR is activated.
ASOCR(Auto Screen OCR) Select range and every time you press Space key, OCR is activated. 範囲を選ぶと、あなたがスペースキーを押すたびに、画面が変わる度にOCRが起動します。 usage1: simple OC
 1 Feb 13, 2022
1 Feb 13, 2022

OCR, Object Detection, Number Plate, Real Time
README.md PrePareded anaconda env requirements.txt clova AI → deep text recognition → trained weights (ex, .pth) wpod-net weights (ex, .h5 , .json) ht
 7 Dec 6, 2022
7 Dec 6, 2022
Python tool that takes the OCR.space JSON output as input and draws a text overlay on top of the image.
OCR.space OCR Result Checker = Draw OCR overlay on top of image Python tool that takes the OCR.space JSON output as input, and draws an overlay on to
 4 Oct 18, 2022
4 Oct 18, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
327 Jan 1, 2023
This pyhton script converts a pdf to Image then using tesseract as OCR engine converts Image to Text
Script_Convertir_PDF_IMG_TXT Este script de pyhton convierte un pdf en Imagen luego utilizando tesseract como motor OCR convierte la Imagen a Texto. p
 1 Jan 27, 2022
1 Jan 27, 2022
Simple and understandable swin-transformer OCR project
swin-transformer-ocr ocr with swin-transformer Overview Simple and understandable swin-transformer OCR project. The model in this repository heavily r
 67 Dec 31, 2022
67 Dec 31, 2022

OCR-ID-Card VietNamese (new id-card)
OCR-ID-Card VietNamese (new id-card) run project: download 2 file weights and pu
 12 Jun 15, 2022
12 Jun 15, 2022
OCR-D wrapper for detectron2 based segmentation models
ocrd_detectron2 OCR-D wrapper for detectron2 based segmentation models Introduction Installation Usage OCR-D processor interface ocrd-detectron2-segm
 13 Dec 6, 2022
13 Dec 6, 2022

Meta Self-learning for Multi-Source Domain Adaptation: A Benchmark
Meta Self-Learning for Multi-Source Domain Adaptation: A Benchmark Project | Arxiv | YouTube | | Abstract In recent years, deep learning-based methods
 188 Dec 12, 2022
188 Dec 12, 2022
Ddddocr - 通用验证码识别OCR pypi版
带带弟弟OCR通用验证码识别SDK免费开源版 今天ddddocr又更新啦! 当前版本为1.3.1 想必很多做验证码的新手,一定头疼碰到点选类型的图像,做样本费时
 4.4k Dec 31, 2022
4.4k Dec 31, 2022
A bot that plays TFT using OCR. Keeps track of bench, board, items, and plays the user defined team comp.
NOTES: To ensure best results, make sure you are running this on a computer that has decent specs. 1920x1080 fullscreen is required in League, game mu
 125 Dec 30, 2022
125 Dec 30, 2022
Fine tuning keras-ocr python package with custom synthetic dataset from scratch
OCR-Pipeline-with-Keras The keras-ocr package generally consists of two parts: a Detector and a Recognizer: Detector is responsible for creating bound
 1 Jan 5, 2022
1 Jan 5, 2022

A supercharged version of paperless: scan, index and archive all your physical documents
Paperless-ng Paperless (click me) is an application by Daniel Quinn and contributors that indexes your scanned documents and allows you to easily sear
 5.3k Jan 9, 2023
5.3k Jan 9, 2023
Omdena-abuja-anpd - Automatic Number Plate Detection for the security of lives and properties using Computer Vision.
Omdena-abuja-anpd - Automatic Number Plate Detection for the security of lives and properties using Computer Vision.
 1 Jan 1, 2022
1 Jan 1, 2022

IDCARD-VERIFYING-SYSTEM - The "IDCARD VERIFYING SYSTEM" uses the Google's latest version of Tesseract OCR[Optical Character Recognition]
IDCARD VERIFYING SYSTEM The "IDCARD VERIFYING SYSTEM" uses the Google's latest v
 1 Dec 31, 2021
1 Dec 31, 2021
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. ocrmypdf
 8k Jan 8, 2023
8k Jan 8, 2023

Highlight Translator can help you translate the words quickly and accurately.
Highlight Translator can help you translate the words quickly and accurately. By only highlighting, copying, or screenshoting the content you want to translate anywhere on your computer (ex. PDF, PPT, WORD etc.), the translated results will then be automatically displayed before you.
 48 Dec 21, 2022
48 Dec 21, 2022
This wrapper now has async support, its basically the same except it uses asyncio
This is a python wrapper for my api api_url = "https://api.dhravya.me/" This wrapper now has async support, its basically the same except it uses asyn
 5 Mar 10, 2022
5 Mar 10, 2022

A tool combining EasyOCR and LaMa to automatically detect text and replace it with an inpainted background.
EasyLaMa (WIP) This is a tool combining EasyOCR and LaMa to automatically detect text and replace it with an inpainted background. Installation For GP
 3 Sep 17, 2022
3 Sep 17, 2022
轻量级公式 OCR 小工具:一键识别各类公式图片,并转换为 LaTeX 格式
QC-Formula | 青尘公式 OCR 介绍 轻量级开源公式 OCR 小工具:一键识别公式图片,并转换为 LaTeX 格式。 支持从 电脑本地 导入公式图片;(后续版本将支持直接从网页导入图片) 公式图片支持 .png / .jpg / .bmp,大小为 4M 以内均可; 支持印刷体及手写体,前
 26 Jan 7, 2023
26 Jan 7, 2023
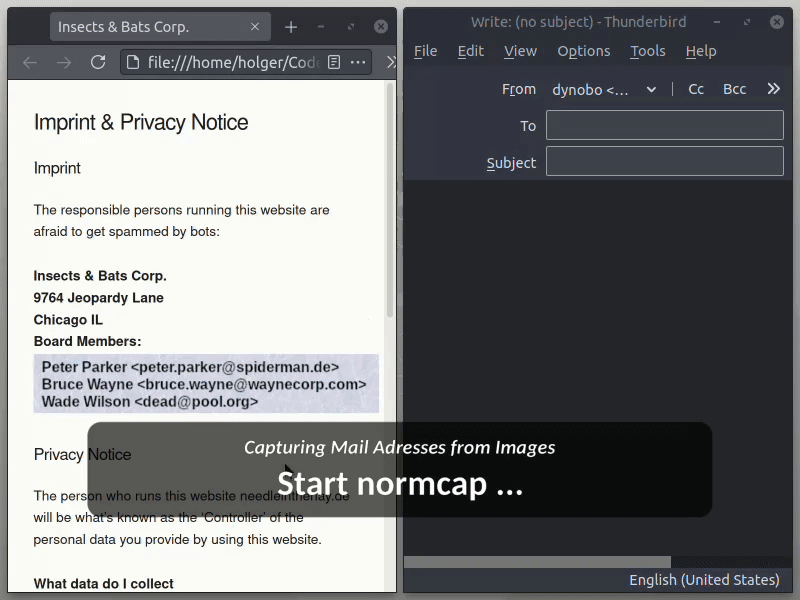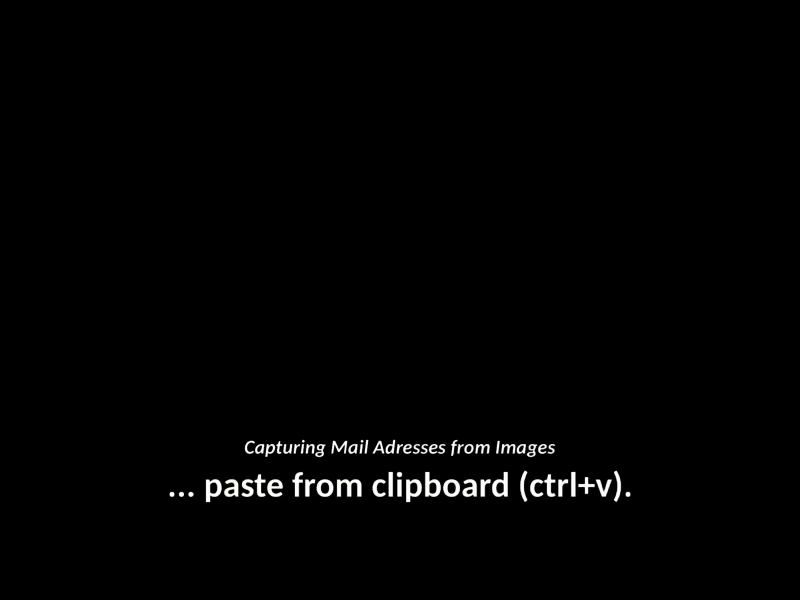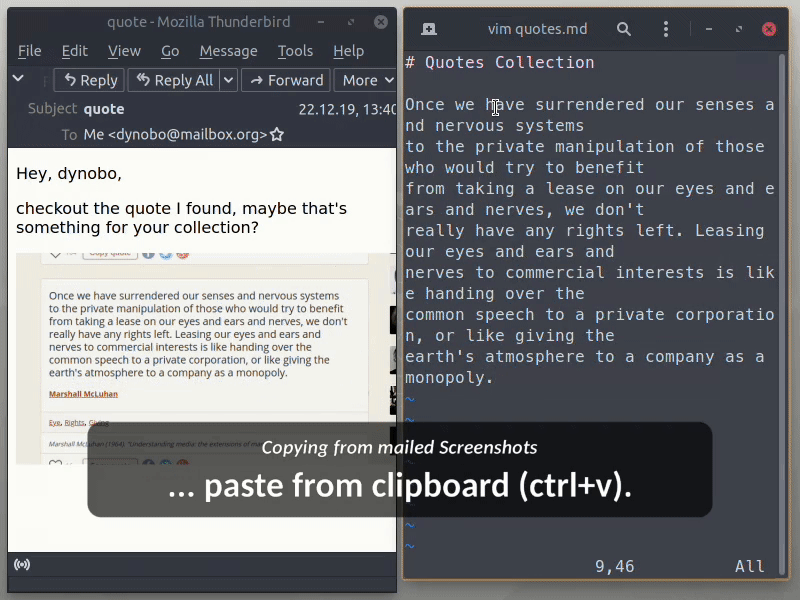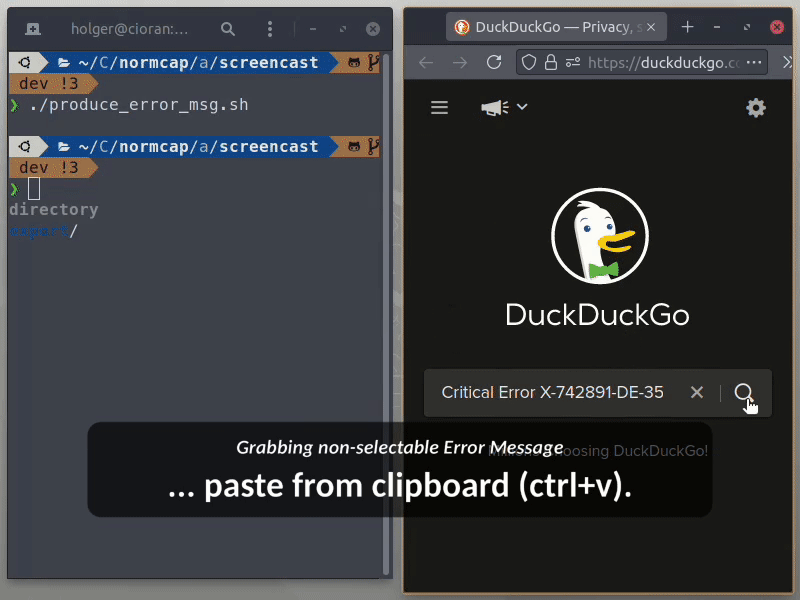
OCR powered screen-capture tool to capture information instead of images
NormCap OCR powered screen-capture tool to capture information instead of images. Links: Repo | PyPi | Releases | Changelog | FAQs Content: Quickstart
 575 Dec 31, 2022
575 Dec 31, 2022
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
 3k Jan 2, 2023
3k Jan 2, 2023
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
Demo processor to illustrate OCR-D Python API
ocrd_vandalize/ Demo processor to illustrate the OCR-D/core Python API Description :TODO: write docs :) Installation From PyPI pip3 install ocrd_vanda
 5 May 5, 2022
5 May 5, 2022
Educational application aimed at automating user-defined workflows for the mobile game, "Granblue Fantasy", using a variety of CV technologies in the backend such as OpenCV, PyAutoGUI and EasyOCR and a frontend coded in Typescript.
Granblue Automation using Template Matching (It is like Full Auto, but with Full Customization!) Discord here: https://discord.gg/5Yv4kqjAbm Android v
 71 Dec 30, 2022
71 Dec 30, 2022

Convert PDF/Image to TXT using EasyOcr - the best OCR engine available!
PDFImage2TXT - DOWNLOAD INSTALLER HERE What can you do with it? Convert scanned PDFs to TXT. Convert scanned Documents to TXT. No coding required!! In
 2 Feb 22, 2022
2 Feb 22, 2022

A little but useful tool to explore OCR data extracted with `pytesseract` and `opencv`
Screenshot OCR Tool Extracting data from screen time screenshots in iOS and Android. We are exploring 3 options: Simple OCR with no text position usin
 1 Dec 7, 2021
1 Dec 7, 2021
FOTS Pytorch Implementation
News!!! Recognition branch now is added into model. The whole project has beed optimized and refactored. ICDAR Dataset SynthText 800K Dataset detectio
 599 Dec 19, 2022
599 Dec 19, 2022
Indonesian ID Card OCR using tesseract OCR
KTP OCR Indonesian ID Card OCR using tesseract OCR KTP OCR is python-flask with tesseract web application to convert Indonesian ID Card to text / JSON
 5 Dec 6, 2021
5 Dec 6, 2021

The open source extract transaction infomation by using OCR.
Transaction OCR Mã nguồn trích xuất thông tin transaction từ file scaned pdf, ở đây tôi lựa chọn tài liệu sao kê công khai của Thuy Tien. Mã nguồn có
 18 Jun 2, 2022
18 Jun 2, 2022
OpenMMLab Text Detection, Recognition and Understanding Toolbox
Introduction English | 简体中文 MMOCR is an open-source toolbox based on PyTorch and mmdetection for text detection, text recognition, and the correspondi
 3k Jan 7, 2023
3k Jan 7, 2023

OCR Streamlit App is used to extract text from images using python's easyocr, pytorch and streamlit packages
OCR-Streamlit-App OCR Streamlit App is used to extract text from images using python's easyocr, pytorch and streamlit packages OCR app gets an image a
 5 Apr 5, 2022
5 Apr 5, 2022

Apply different text recognition services to images of handwritten documents.
Handprint The Handwritten Page Recognition Test is a command-line program that invokes HTR (handwritten text recognition) services on images of docume
 117 Jan 2, 2023
117 Jan 2, 2023
OCR of Chicago 1909 Renumbering Plan
Requirements: Python 3 (probably at least 3.4) pipenv (pip3 install pipenv) tesseract (brew install tesseract, at least if you have a mac and homebrew
 2 Nov 21, 2021
2 Nov 21, 2021

This is a GUI for scrapping PDFs with the help of optical character recognition making easier than ever to scrape PDFs.
pdf-scraper-with-ocr With this tool I am aiming to facilitate the work of those who need to scrape PDFs either by hand or using tools that doesn't imp
 75 Oct 21, 2022
75 Oct 21, 2022

OCR Post Correction for Endangered Language Texts
📌 Coming soon: an update to the software including features from our paper on semi-supervised OCR post-correction, to be published in the Transaction
 96 Dec 31, 2022
96 Dec 31, 2022
Python-based tools for document analysis and OCR
ocropy OCRopus is a collection of document analysis programs, not a turn-key OCR system. In order to apply it to your documents, you may need to do so
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
 176 Nov 28, 2022
176 Nov 28, 2022
Tools for manipulating and evaluating the hOCR format for representing multi-lingual OCR results by embedding them into HTML.
hocr-tools About About the code Installation System-wide with pip System-wide from source virtualenv Available Programs hocr-check -- check the hOCR f
285 Dec 8, 2022

Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
 1.2k Dec 29, 2022
1.2k Dec 29, 2022
Classical OCR DCNN reproduction based on PaddlePaddle framework.
Paddle-SVHN Classical OCR DCNN reproduction based on PaddlePaddle framework. This project reproduces Multi-digit Number Recognition from Street View I
 1 Nov 12, 2021
1 Nov 12, 2021
This is a implementation of CRAFT OCR method
This is a implementation of CRAFT OCR method
 0 Nov 1, 2021
0 Nov 1, 2021
This is a GUI for scrapping PDFs with the help of optical character recognition making easier than ever to scrape PDFs.
pdf-scraper-with-ocr With this tool I am aiming to facilitate the work of those who need to scrape PDFs either by hand or using tools that doesn't imp
75 Oct 21, 2022
Dirty, ugly, and hopefully useful OCR of Facebook Papers docs released by Gizmodo
Quick and Dirty OCR of Facebook Papers Gizmodo has been working through the Facebook Papers and releasing the docs that they process and review. As lu
 2 Oct 28, 2021
2 Oct 28, 2021
Generate custom detailed survey paper with topic clustered sections and proper citations, from just a single query in just under 30 mins !!
Auto-Research A no-code utility to generate a detailed well-cited survey with topic clustered sections (draft paper format) and other interesting arti
 20 Dec 14, 2022
20 Dec 14, 2022
A Vietnamese personal card OCR website built with Django.
Django VietCardOCR Installation Creation of virtual environments is done by executing the command venv: python -m venv venv That will create a new fol
 4 Sep 4, 2021
4 Sep 4, 2021
Convolutional Recurrent Neural Network (CRNN) for image-based sequence recognition.
Convolutional Recurrent Neural Network This software implements the Convolutional Recurrent Neural Network (CRNN), a combination of CNN, RNN and CTC l
 2k Dec 31, 2022
2k Dec 31, 2022

Key information extraction from invoice document with Graph Convolution Network
Key Information Extraction from Scanned Invoices Key information extraction from invoice document with Graph Convolution Network Related blog post fro
 39 Dec 16, 2022
39 Dec 16, 2022

Machine Leaning applied to denoise images to improve OCR Accuracy
Machine Learning to Denoise Images for Better OCR Accuracy This project is an adaptation of this tutorial and used only for learning purposes: https:/
 2 Nov 16, 2022
2 Nov 16, 2022
A bot that extract text from images using the Tesseract OCR.
Text from image (OCR) @ocr_text_bot A simple bot to extract text from images. Usage What do I need? A AWS key configured locally, see here. NodeJS. I
 4 Aug 6, 2021
4 Aug 6, 2021

Use Youdao OCR API to covert your clipboard image to text.
Alfred Clipboard OCR 注:本仓库基于 oott123/alfred-clipboard-ocr 的逻辑用 Python 重写,换用了有道 AI 的 API,准确率更高,有效防止百度导致隐私泄露等问题,并且有道 AI 初始提供的 50 元体验金对于其资费而言个人用户基本可以永久使用
 6 Sep 19, 2022
6 Sep 19, 2022
Usando o Amazon Textract como OCR para Extração de Dados no DynamoDB
dio-live-textract2 Repositório de código para o live coding do dia 05/10/2021 sobre extração de dados estruturados e gravação em banco de dados a part
 0 Jan 19, 2022
0 Jan 19, 2022

Ground truth data for the Optical Character Recognition of Historical Classical Commentaries.
OCR Ground Truth for Historical Commentaries The dataset OCR ground truth for historical commentaries (GT4HistComment) was created from the public dom
 3 Sep 8, 2022
3 Sep 8, 2022
a micro OCR network with 0.07mb params.
MicroOCR a micro OCR network with 0.07mb params. Layer (type) Output Shape Param # Conv2d-1 [-1, 64, 8,
 29 Aug 6, 2022
29 Aug 6, 2022
Programa que viabiliza a OCR (Optical Character Reading - leitura óptica de caracteres) de um PDF.
Este programa tem o intuito de ser um modificador de arquivos PDF. Os arquivos PDFs podem ser 3: PDFs verdadeiros - em que podem ser selecionados o ti
 2 Oct 11, 2021
2 Oct 11, 2021
It is a image ocr tool using the Tesseract-OCR engine with the pytesseract package and has a GUI.
OCR-Tool It is a image ocr tool made in Python using the Tesseract-OCR engine with the pytesseract package and has a GUI. This is my second ever pytho
 4 Jul 11, 2022
4 Jul 11, 2022

METS/ALTO OCR enhancing tool by the National Library of Luxembourg (BnL)
Nautilus-OCR The National Library of Luxembourg (BnL) started its first initiative in digitizing newspapers, with layout recognition and OCR on articl
 36 Dec 5, 2022
36 Dec 5, 2022

Gradient Step Denoiser for convergent Plug-and-Play
Source code for the paper "Gradient Step Denoiser for convergent Plug-and-Play"
 11 Sep 17, 2022
11 Sep 17, 2022
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
 1.5k Jan 1, 2023
1.5k Jan 1, 2023
A Screen Translator/OCR Translator made by using Python and Tesseract, the user interface are made using Tkinter. All code written in python.
About An OCR translator tool. Made by me by utilizing Tesseract, compiled to .exe using pyinstaller. I made this program to learn more about python. I
 41 Dec 30, 2022
41 Dec 30, 2022

Generate text line images for training deep learning OCR model (e.g. CRNN)
Generate text line images for training deep learning OCR model (e.g. CRNN)
 532 Jan 6, 2023
532 Jan 6, 2023
一个多语言支持、易使用的 OCR 项目。An easy-to-use OCR project with multilingual support.
AgentOCR 简介 AgentOCR 是一个基于 PaddleOCR 和 ONNXRuntime 项目开发的一个使用简单、调用方便的 OCR 项目 本项目目前包含 Python Package 【AgentOCR】 和 OCR 标注软件 【AgentOCRLabeling】 使用指南 Pytho
 98 Nov 10, 2022
98 Nov 10, 2022

pix2tex: Using a ViT to convert images of equations into LaTeX code.
The goal of this project is to create a learning based system that takes an image of a math formula and returns corresponding LaTeX code.
 2.6k Dec 30, 2022
2.6k Dec 30, 2022

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
235 Dec 22, 2022

Official implementation of SynthTIGER (Synthetic Text Image GEneratoR) ICDAR 2021
🐯 SynthTIGER: Synthetic Text Image GEneratoR Official implementation of SynthTIGER | Paper | Datasets Moonbin Yim1, Yoonsik Kim1, Han-cheol Cho1, Sun
 256 Jan 5, 2023
256 Jan 5, 2023

A dataset for online Arabic calligraphy
Calliar Calliar is a dataset for Arabic calligraphy. The dataset consists of 2500 json files that contain strokes manually annotated for Arabic callig
 114 Dec 28, 2022
114 Dec 28, 2022
Some Boring Research About Products Recognition 、Duplicate Img Detection、Img Stitch、OCR
Products Recognition 介绍 商品识别,围绕在复杂的商场零售场景中,识别出货架图像中的商品信息。主要组成部分: 重复图像检测。【更新进度 4/10】 图像拼接。【更新进度 0/10】 目标检测。【更新进度 0/10】 商品识别。【更新进度 1/10】 OCR。【更新进度 1/10】
 18 Jan 27, 2022
18 Jan 27, 2022
A cross platform OCR Library based on PaddleOCR & OnnxRuntime
A cross platform OCR Library based on PaddleOCR & OnnxRuntime
 767 Jan 9, 2023
767 Jan 9, 2023

PyTorch code of my ICDAR 2021 paper Vision Transformer for Fast and Efficient Scene Text Recognition (ViTSTR)
Vision Transformer for Fast and Efficient Scene Text Recognition (ICDAR 2021) ViTSTR is a simple single-stage model that uses a pre-trained Vision Tra
 198 Dec 27, 2022
198 Dec 27, 2022

HiFi-GAN: High Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks
HiFiGAN Denoiser This is a Unofficial Pytorch implementation of the paper HiFi-GAN: High Fidelity Denoising and Dereverberation Based on Speech Deep F
 134 Dec 27, 2022
134 Dec 27, 2022
OpenMMLab Text Detection, Recognition and Understanding Toolbox
Introduction English | 简体中文 MMOCR is an open-source toolbox based on PyTorch and mmdetection for text detection, text recognition, and the correspondi
3k Jan 7, 2023
Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
176 Nov 28, 2022
Code for the paper "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021)
MASTER-PyTorch PyTorch reimplementation of "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021). This projec
 255 Dec 29, 2022
255 Dec 29, 2022

Layout Parser is a deep learning based tool for document image layout analysis tasks.
A Python Library for Document Layout Understanding
 3.4k Dec 30, 2022
3.4k Dec 30, 2022
![git《Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser》(2021) GitHub: [fig5]](https://github.com/happycaoyue/Pseudo-ISP/raw/main/img/3.png)
git《Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser》(2021) GitHub: [fig5]
Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser Abstract The success of deep denoisers on real-world colo
 51 Nov 22, 2022
51 Nov 22, 2022
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. ocrmypdf # it's a scriptable c
 7.9k Jan 3, 2023
7.9k Jan 3, 2023

Convolutional Recurrent Neural Networks(CRNN) for Scene Text Recognition
CRNN_Tensorflow This is a TensorFlow implementation of a Deep Neural Network for scene text recognition. It is mainly based on the paper "An End-to-En
 1000 Dec 27, 2022
1000 Dec 27, 2022
An expandable and scalable OCR pipeline
Overview Nidaba is the central controller for the entire OGL OCR pipeline. It oversees and automates the process of converting raw images into citable
 81 Jan 4, 2023
81 Jan 4, 2023

A simple OCR API server, seriously easy to be deployed by Docker, on Heroku as well
ocrserver Simple OCR server, as a small working sample for gosseract. Try now here https://ocr-example.herokuapp.com/, and deploy your own now. Deploy
 541 Dec 28, 2022
541 Dec 28, 2022
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023

Detect text blocks and OCR poorly scanned PDFs in bulk. Python module available via pip.
doc2text doc2text extracts higher quality text by fixing common scan errors Developing text corpora can be a massive pain in the butt. Much of the tex
 1.3k Jan 4, 2023
1.3k Jan 4, 2023

An OCR evaluation tool
dinglehopper dinglehopper is an OCR evaluation tool and reads ALTO, PAGE and text files. It compares a ground truth (GT) document page with a OCR resu
 40 Dec 20, 2022
40 Dec 20, 2022

Text recognition (optical character recognition) with deep learning methods.
What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis | paper | training and evaluation data | failure cases and cle
3.2k Jan 4, 2023

TedEval: A Fair Evaluation Metric for Scene Text Detectors
TedEval: A Fair Evaluation Metric for Scene Text Detectors Official Python 3 implementation of TedEval | paper | slides Chae Young Lee, Youngmin Baek,
167 Nov 20, 2022
The CIS OCR PostCorrectionTool
The CIS OCR Post Correction Tool PoCoTo Source code for the Java-based PoCoTo client enabling fast interactive batch corrections of complete OCR error
 36 Dec 15, 2022
36 Dec 15, 2022
Toolbox for OCR post-correction
Ochre Ochre is a toolbox for OCR post-correction. Please note that this software is experimental and very much a work in progress! Overview of OCR pos
 117 Nov 10, 2022
117 Nov 10, 2022

Binarize document images
Binarization Binarization for document images Examples Introduction This tool performs document image binarization (i.e. transform colour/grayscale to
48 Jan 2, 2023
Pre-Recognize Library - library with algorithms for improving OCR quality.
PRLib - Pre-Recognition Library. The main aim of the library - prepare image for recogntion. Image processing can really help to improve recognition q
 80 Dec 30, 2022
80 Dec 30, 2022

Generate text images for training deep learning ocr model
New version release:https://github.com/oh-my-ocr/text_renderer Text Renderer Generate text images for training deep learning OCR model (e.g. CRNN). Su
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

A synthetic data generator for text recognition
TextRecognitionDataGenerator A synthetic data generator for text recognition What is it for? Generating text image samples to train an OCR software. N
 2.5k Jan 4, 2023
2.5k Jan 4, 2023
list all open dataset about ocr.
ocr-open-dataset list all open dataset about ocr. printed dataset year Born-Digital Images (Web and Email) 2011-2015 COCO-Text 2017 Text Extraction fr
 95 Nov 24, 2022
95 Nov 24, 2022
Tools for manipulating and evaluating the hOCR format for representing multi-lingual OCR results by embedding them into HTML.
hocr-tools About About the code Installation System-wide with pip System-wide from source virtualenv Available Programs hocr-check -- check the hOCR f
285 Dec 8, 2022
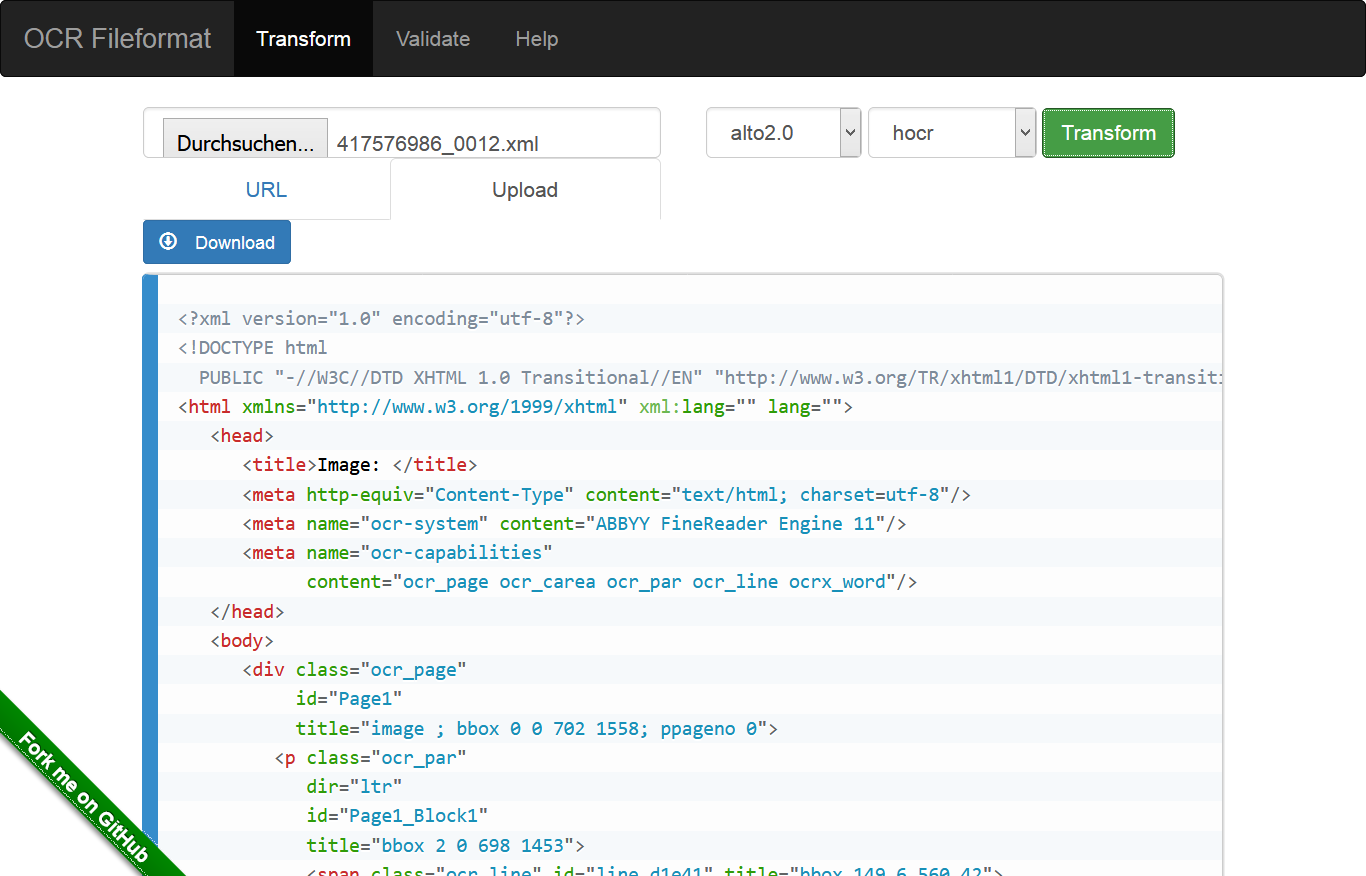
Validate and transform various OCR file formats (hOCR, ALTO, PAGE, FineReader)
ocr-fileformat Validate and transform between OCR file formats (hOCR, ALTO, PAGE, FineReader) Installation Docker System-wide Usage CLI GUI API Transf
 152 Dec 20, 2022
152 Dec 20, 2022