1357 Repositories
Python self-critical-sequence-training Libraries
PyTorch implementation of MoCo v3 for self-supervised ResNet and ViT.
MoCo v3 for Self-supervised ResNet and ViT Introduction This is a PyTorch implementation of MoCo v3 for self-supervised ResNet and ViT. The original M
 887 Jan 8, 2023
887 Jan 8, 2023

Official implementation of the ICCV 2021 paper "Conditional DETR for Fast Training Convergence".
The DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings and that the spatial embeddings make minor contributions, increasing the need for high-quality content embeddings and thus increasing the training difficulty.
 281 Dec 30, 2022
281 Dec 30, 2022

Dynamic Divide-and-Conquer Adversarial Training for Robust Semantic Segmentation (ICCV2021)
Dynamic Divide-and-Conquer Adversarial Training for Robust Semantic Segmentation This is a pytorch project for the paper Dynamic Divide-and-Conquer Ad
 29 Nov 21, 2022
29 Nov 21, 2022
A Code that can make your Discord Account 24/7 on Voice Channels!
Voicecord Make your Discord Account Online 24/7 on Voice Channels! A Code written in Python that helps you to keep your account 24/7 on Voice Channels
 229 Jan 7, 2023
229 Jan 7, 2023
LONG-TERM SERIES FORECASTING WITH QUERYSELECTOR – EFFICIENT MODEL OF SPARSEATTENTION
Query Selector Here you can find code and data loaders for the paper https://arxiv.org/pdf/2107.08687v1.pdf . Query Selector is a novel approach to sp
 62 Dec 17, 2022
62 Dec 17, 2022
Unofficial pytorch implementation for Self-critical Sequence Training for Image Captioning. and others.
An Image Captioning codebase This is a codebase for image captioning research. It supports: Self critical training from Self-critical Sequence Trainin
 906 Jan 3, 2023
906 Jan 3, 2023

IAST: Instance Adaptive Self-training for Unsupervised Domain Adaptation (ECCV 2020)
This repo is the official implementation of our paper "Instance Adaptive Self-training for Unsupervised Domain Adaptation". The purpose of this repo is to better communicate with you and respond to your questions. This repo is almost the same with Another-Version, and you can also refer to that version.
 84 Dec 12, 2022
84 Dec 12, 2022
Ongoing research training transformer language models at scale, including: BERT & GPT-2
What is this fork of Megatron-LM and Megatron-DeepSpeed This is a detached fork of https://github.com/microsoft/Megatron-DeepSpeed, which in itself is
 316 Jan 3, 2023
316 Jan 3, 2023

We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.
An Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering Papers with code | Paper Nikola Zubić Pietro Lio University
 213 Dec 27, 2022
213 Dec 27, 2022

This is an official implementation for "Self-Supervised Learning with Swin Transformers".
Self-Supervised Learning with Vision Transformers By Zhenda Xie*, Yutong Lin*, Zhuliang Yao, Zheng Zhang, Qi Dai, Yue Cao and Han Hu This repo is the
 529 Jan 2, 2023
529 Jan 2, 2023

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023
Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training.
Updates (2020/06/21) Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training. Pyr
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023

Partial implementation of ODE-GAN technique from the paper Training Generative Adversarial Networks by Solving Ordinary Differential Equations
ODE GAN (Prototype) in PyTorch Partial implementation of ODE-GAN technique from the paper Training Generative Adversarial Networks by Solving Ordinary
 15 Feb 10, 2022
15 Feb 10, 2022
This repository contains the code for "Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based Bias in NLP".
Self-Diagnosis and Self-Debiasing This repository contains the source code for Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based
 62 Dec 12, 2022
62 Dec 12, 2022

By default, networkx has problems with drawing self-loops in graphs.
By default, networkx has problems with drawing self-loops in graphs. It makes it hard to draw a graph with self-loops or to make a nicely looking chord diagram. This repository provides some code to draw self-loops nicely
 5 Jan 6, 2022
5 Jan 6, 2022

Code for generating a single image pretraining dataset
Single Image Pretraining of Visual Representations As shown in the paper A critical analysis of self-supervision, or what we can learn from a single i
 12 Dec 19, 2022
12 Dec 19, 2022
Video Contrastive Learning with Global Context
Video Contrastive Learning with Global Context (VCLR) This is the official PyTorch implementation of our VCLR paper. Install dependencies environments
 143 Dec 26, 2022
143 Dec 26, 2022

Pytorch implementation of CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generation"
MUST-GAN Code | paper The Pytorch implementation of our CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generat
 46 Dec 26, 2022
46 Dec 26, 2022
A Code that can make your Discord Account 24/7!
Online-Forever Make your Discord Account Online 24/7! A Code written in Python that helps you to keep your account 24/7. The main.py is the main file.
556 Dec 29, 2022
An implementation for `Text2Event: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction`
Text2Event An implementation for Text2Event: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction Please contact Yaojie Lu (@
 153 Jan 7, 2023
153 Jan 7, 2023
ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge (ManiSkill Challenge), a large-scale learning-from-demonstrations benchmark for object manipulation.
ManiSkill-Learn ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge, a large-scale learning-from-dem
 48 Dec 30, 2022
48 Dec 30, 2022

Code for paper "ASAP-Net: Attention and Structure Aware Point Cloud Sequence Segmentation"
ASAP-Net This project implements ASAP-Net of paper ASAP-Net: Attention and Structure Aware Point Cloud Sequence Segmentation (BMVC2020). Overview We i
 26 Aug 25, 2022
26 Aug 25, 2022

Implementation of the paper All Labels Are Not Created Equal: Enhancing Semi-supervision via Label Grouping and Co-training
SemCo The official pytorch implementation of the paper All Labels Are Not Created Equal: Enhancing Semi-supervision via Label Grouping and Co-training
 42 Nov 14, 2022
42 Nov 14, 2022
A library for uncertainty representation and training in neural networks.
Epistemic Neural Networks A library for uncertainty representation and training in neural networks. Introduction Many applications in deep learning re
 211 Dec 12, 2022
211 Dec 12, 2022

An official implementation of the paper Exploring Sequence Feature Alignment for Domain Adaptive Detection Transformers
Sequence Feature Alignment (SFA) By Wen Wang, Yang Cao, Jing Zhang, Fengxiang He, Zheng-jun Zha, Yonggang Wen, and Dacheng Tao This repository is an o
 79 Dec 24, 2022
79 Dec 24, 2022

Implementation of the paper "Self-Promoted Prototype Refinement for Few-Shot Class-Incremental Learning"
Self-Promoted Prototype Refinement for Few-Shot Class-Incremental Learning This is the implementation of the paper "Self-Promoted Prototype Refinement
 78 Dec 2, 2022
78 Dec 2, 2022
Object-aware Contrastive Learning for Debiased Scene Representation
Object-aware Contrastive Learning Official PyTorch implementation of "Object-aware Contrastive Learning for Debiased Scene Representation" by Sangwoo
 43 Dec 14, 2022
43 Dec 14, 2022
Universal End2End Training Platform, including pre-training, classification tasks, machine translation, and etc.
背景 安装教程 快速上手 (一)预训练模型 (二)机器翻译 (三)文本分类 TenTrans 进阶 1. 多语言机器翻译 2. 跨语言预训练 背景 TrenTrans是一个统一的端到端的多语言多任务预训练平台,支持多种预训练方式,以及序列生成和自然语言理解任务。 安装教程 git clone git
 42 Dec 20, 2022
42 Dec 20, 2022

A collection of interactive machine-learning experiments: 🏋️models training + 🎨models demo
🤖 Interactive Machine Learning experiments: 🏋️models training + 🎨models demo
 1.4k Jan 6, 2023
1.4k Jan 6, 2023

MASS: Masked Sequence to Sequence Pre-training for Language Generation
MASS: Masked Sequence to Sequence Pre-training for Language Generation
 1.1k Dec 17, 2022
1.1k Dec 17, 2022

In-Place Activated BatchNorm for Memory-Optimized Training of DNNs
In-Place Activated BatchNorm In-Place Activated BatchNorm for Memory-Optimized Training of DNNs In-Place Activated BatchNorm (InPlace-ABN) is a novel
 1.3k Dec 29, 2022
1.3k Dec 29, 2022

A PyTorch Implementation of Gated Graph Sequence Neural Networks (GGNN)
A PyTorch Implementation of GGNN This is a PyTorch implementation of the Gated Graph Sequence Neural Networks (GGNN) as described in the paper Gated G
 427 Dec 13, 2022
427 Dec 13, 2022
Proximal Backpropagation - a neural network training algorithm that takes implicit instead of explicit gradient steps
Proximal Backpropagation Proximal Backpropagation (ProxProp) is a neural network training algorithm that takes implicit instead of explicit gradient s
 40 Dec 17, 2022
40 Dec 17, 2022
Sequence modeling benchmarks and temporal convolutional networks
Sequence Modeling Benchmarks and Temporal Convolutional Networks (TCN) This repository contains the experiments done in the work An Empirical Evaluati
 3.5k Jan 3, 2023
3.5k Jan 3, 2023

LogDeep is an open source deeplearning-based log analysis toolkit for automated anomaly detection.
LogDeep is an open source deeplearning-based log analysis toolkit for automated anomaly detection.
 279 Dec 13, 2022
279 Dec 13, 2022

A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
 488 Nov 28, 2022
488 Nov 28, 2022

A pytorch implementation of Detectron. Both training from scratch and inferring directly from pretrained Detectron weights are available.
Use this instead: https://github.com/facebookresearch/maskrcnn-benchmark A Pytorch Implementation of Detectron Example output of e2e_mask_rcnn-R-101-F
 2.8k Dec 29, 2022
2.8k Dec 29, 2022

Implementation of H-Transformer-1D, Hierarchical Attention for Sequence Learning
H-Transformer-1D Implementation of H-Transformer-1D, Transformer using hierarchical Attention for sequence learning with subquadratic costs. For now,
 123 Nov 17, 2022
123 Nov 17, 2022

Code release for "Self-Tuning for Data-Efficient Deep Learning" (ICML 2021)
Self-Tuning for Data-Efficient Deep Learning This repository contains the implementation code for paper: Self-Tuning for Data-Efficient Deep Learning
 101 Dec 11, 2022
101 Dec 11, 2022

Code for paper "Which Training Methods for GANs do actually Converge? (ICML 2018)"
GAN stability This repository contains the experiments in the supplementary material for the paper Which Training Methods for GANs do actually Converg
 884 Nov 11, 2022
884 Nov 11, 2022

ReSSL: Relational Self-Supervised Learning with Weak Augmentation
ReSSL: Relational Self-Supervised Learning with Weak Augmentation This repository contains PyTorch evaluation code, training code and pretrained model
 45 Oct 25, 2022
45 Oct 25, 2022
This is an official implementation of "Polarized Self-Attention: Towards High-quality Pixel-wise Regression"
Polarized Self-Attention: Towards High-quality Pixel-wise Regression This is an official implementation of: Huajun Liu, Fuqiang Liu, Xinyi Fan and Don
 212 Jan 8, 2023
212 Jan 8, 2023

Code for the ICML 2021 paper "Bridging Multi-Task Learning and Meta-Learning: Towards Efficient Training and Effective Adaptation", Haoxiang Wang, Han Zhao, Bo Li.
Bridging Multi-Task Learning and Meta-Learning Code for the ICML 2021 paper "Bridging Multi-Task Learning and Meta-Learning: Towards Efficient Trainin
 57 Dec 15, 2022
57 Dec 15, 2022

Spatial Contrastive Learning for Few-Shot Classification (SCL)
This repo contains the official implementation of Spatial Contrastive Learning for Few-Shot Classification (SCL), which presents of a novel contrastive learning method applied to few-shot image classification in order to learn more general purpose embeddings, and facilitate the test-time adaptation to novel visual categories.
 34 Dec 25, 2022
34 Dec 25, 2022

TilinGNN: Learning to Tile with Self-Supervised Graph Neural Network (SIGGRAPH 2020)
TilinGNN: Learning to Tile with Self-Supervised Graph Neural Network (SIGGRAPH 2020) About The goal of our research problem is illustrated below: give
 59 Dec 9, 2022
59 Dec 9, 2022

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
 67 Nov 14, 2022
67 Nov 14, 2022
Deduplicating Training Data Makes Language Models Better
Deduplicating Training Data Makes Language Models Better This repository contains code to deduplicate language model datasets as descrbed in the paper
 431 Dec 27, 2022
431 Dec 27, 2022

Locally Enhanced Self-Attention: Rethinking Self-Attention as Local and Context Terms
LESA Introduction This repository contains the official implementation of Locally Enhanced Self-Attention: Rethinking Self-Attention as Local and Cont
 20 Dec 31, 2021
20 Dec 31, 2021
Reference implementation of code generation projects from Facebook AI Research. General toolkit to apply machine learning to code, from dataset creation to model training and evaluation. Comes with pretrained models.
This repository is a toolkit to do machine learning for programming languages. It implements tokenization, dataset preprocessing, model training and m
408 Jan 1, 2023

A PyTorch implementation of ViTGAN based on paper ViTGAN: Training GANs with Vision Transformers.
ViTGAN: Training GANs with Vision Transformers A PyTorch implementation of ViTGAN based on paper ViTGAN: Training GANs with Vision Transformers. Refer
 127 Dec 23, 2022
127 Dec 23, 2022
A Fast Sequence Transducer Implementation with PyTorch Bindings
transducer A Fast Sequence Transducer Implementation with PyTorch Bindings. The corresponding publication is Sequence Transduction with Recurrent Neur
 184 Dec 18, 2022
184 Dec 18, 2022
Pervasive Attention: 2D Convolutional Networks for Sequence-to-Sequence Prediction
This is a fork of Fairseq(-py) with implementations of the following models: Pervasive Attention - 2D Convolutional Neural Networks for Sequence-to-Se
 490 Dec 15, 2022
490 Dec 15, 2022

An implementation of DeepMind's Relational Recurrent Neural Networks in PyTorch.
relational-rnn-pytorch An implementation of DeepMind's Relational Recurrent Neural Networks (Santoro et al. 2018) in PyTorch. Relational Memory Core (
 241 Nov 18, 2022
241 Nov 18, 2022
[ICLR'19] Trellis Networks for Sequence Modeling
TrellisNet for Sequence Modeling This repository contains the experiments done in paper Trellis Networks for Sequence Modeling by Shaojie Bai, J. Zico
460 Oct 13, 2022

A certifiable defense against adversarial examples by training neural networks to be provably robust
DiffAI v3 DiffAI is a system for training neural networks to be provably robust and for proving that they are robust. The system was developed for the
 202 Dec 13, 2022
202 Dec 13, 2022

A PyTorch implementation of "Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks" (KDD 2019).
ClusterGCN ⠀⠀ A PyTorch implementation of "Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks" (KDD 2019). A
 697 Dec 27, 2022
697 Dec 27, 2022
PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022
Self-training for Few-shot Transfer Across Extreme Task Differences
Self-training for Few-shot Transfer Across Extreme Task Differences (STARTUP) Introduction This repo contains the official implementation of the follo
 33 Oct 31, 2022
33 Oct 31, 2022
PyTorch implementation of our Adam-NSCL algorithm from our CVPR2021 (oral) paper "Training Networks in Null Space for Continual Learning"
Adam-NSCL This is a PyTorch implementation of Adam-NSCL algorithm for continual learning from our CVPR2021 (oral) paper: Title: Training Networks in N
 34 Dec 21, 2022
34 Dec 21, 2022

EsViT: Efficient self-supervised Vision Transformers
Efficient Self-Supervised Vision Transformers (EsViT) PyTorch implementation for EsViT, built with two techniques: A multi-stage Transformer architect
352 Dec 25, 2022
StackRec: Efficient Training of Very Deep Sequential Recommender Models by Iterative Stacking
StackRec: Efficient Training of Very Deep Sequential Recommender Models by Iterative Stacking Datasets You can download datasets that have been pre-pr
 25 May 29, 2022
25 May 29, 2022

Official repository for the paper, MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding.
MidiBERT-Piano Authors: Yi-Hui (Sophia) Chou, I-Chun (Bronwin) Chen Introduction This is the official repository for the paper, MidiBERT-Piano: Large-
 137 Dec 15, 2022
137 Dec 15, 2022
AlphaNet Improved Training of Supernet with Alpha-Divergence
AlphaNet: Improved Training of Supernet with Alpha-Divergence This repository contains our PyTorch training code, evaluation code and pretrained model
87 Oct 10, 2022
official implemntation for "Contrastive Learning with Stronger Augmentations"
CLSA CLSA is a self-supervised learning methods which focused on the pattern learning from strong augmentations. Copyright (C) 2020 Xiao Wang, Guo-Jun
 47 Nov 29, 2022
47 Nov 29, 2022

Self-supervised Deep LiDAR Odometry for Robotic Applications
DeLORA: Self-supervised Deep LiDAR Odometry for Robotic Applications Overview Paper: link Video: link ICRA Presentation: link This is the correspondin
 181 Dec 29, 2022
181 Dec 29, 2022
ONNX Runtime for PyTorch accelerates PyTorch model training using ONNX Runtime.
Accelerate PyTorch models with ONNX Runtime
 270 Dec 24, 2022
270 Dec 24, 2022
Решения, подсказки, тесты и утилиты для тренировки по алгоритмам от Яндекса.
Решения и подсказки к тренировке по алгоритмам от Яндекса Что есть внутри Решения с подсказками и комментариями; рекомендую сначала смотреть md файл п
 50 Dec 26, 2022
50 Dec 26, 2022

S2-BNN: Bridging the Gap Between Self-Supervised Real and 1-bit Neural Networks via Guided Distribution Calibration (CVPR 2021)
S2-BNN (Self-supervised Binary Neural Networks Using Distillation Loss) This is the official pytorch implementation of our paper: "S2-BNN: Bridging th
 52 Dec 24, 2022
52 Dec 24, 2022

A self hosted slack bot to conduct standups & generate reports.
StandupMonkey A self hosted slack bot to conduct standups & generate reports. Report Bug · Request Feature Installation Install already hosted bot (Us
 69 Jan 1, 2023
69 Jan 1, 2023

IJCAI2020 & IJCV 2020 :city_sunrise: Unsupervised Scene Adaptation with Memory Regularization in vivo
Seg_Uncertainty In this repo, we provide the code for the two papers, i.e., MRNet:Unsupervised Scene Adaptation with Memory Regularization in vivo, IJ
 348 Jan 5, 2023
348 Jan 5, 2023

PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models Code accompanying CVPR'20 paper of the same title. Paper lin
 7k Dec 30, 2022
7k Dec 30, 2022

An implementation of the AlphaZero algorithm for Gomoku (also called Gobang or Five in a Row)
AlphaZero-Gomoku This is an implementation of the AlphaZero algorithm for playing the simple board game Gomoku (also called Gobang or Five in a Row) f
 2.8k Dec 26, 2022
2.8k Dec 26, 2022
Self Driving RC Car Code
Derp Learning Derp Learning is a Python package that collects data, trains models, and then controls an RC car for track racing. Hardware You will nee
 39 Dec 7, 2022
39 Dec 7, 2022

The Medical Detection Toolkit contains 2D + 3D implementations of prevalent object detectors such as Mask R-CNN, Retina Net, Retina U-Net, as well as a training and inference framework focused on dealing with medical images.
The Medical Detection Toolkit contains 2D + 3D implementations of prevalent object detectors such as Mask R-CNN, Retina Net, Retina U-Net, as well as a training and inference framework focused on dealing with medical images.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
HyperPose is a library for building high-performance custom pose estimation applications.
HyperPose is a library for building high-performance custom pose estimation applications.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

Here is the implementation of our paper S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations.
S2VC Here is the implementation of our paper S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations. In thi
 81 Dec 15, 2022
81 Dec 15, 2022

2021-MICCAI-Progressively Normalized Self-Attention Network for Video Polyp Segmentation
2021-MICCAI-Progressively Normalized Self-Attention Network for Video Polyp Segmentation Authors: Ge-Peng Ji*, Yu-Cheng Chou*, Deng-Ping Fan, Geng Che
 85 Dec 30, 2022
85 Dec 30, 2022
Code for 'Self-Guided and Cross-Guided Learning for Few-shot segmentation. (CVPR' 2021)'
SCL Introduction Code for 'Self-Guided and Cross-Guided Learning for Few-shot segmentation. (CVPR' 2021)' We evaluated our approach using two baseline
 34 Oct 8, 2022
34 Oct 8, 2022

Implementation of Self-supervised Graph-level Representation Learning with Local and Global Structure (ICML 2021).
Self-supervised Graph-level Representation Learning with Local and Global Structure Introduction This project is an implementation of ``Self-supervise
 50 Dec 9, 2022
50 Dec 9, 2022
Piotr - IoT firmware emulation instrumentation for training and research
Piotr: Pythonic IoT exploitation and Research Introduction to Piotr Piotr is an emulation helper for Qemu that provides a convenient way to create, sh
 51 Nov 9, 2022
51 Nov 9, 2022
![[Preprint]](https://github.com/VITA-Group/SViTE/raw/main/Figs/res.png)
[Preprint] "Chasing Sparsity in Vision Transformers: An End-to-End Exploration" by Tianlong Chen, Yu Cheng, Zhe Gan, Lu Yuan, Lei Zhang, Zhangyang Wang
Chasing Sparsity in Vision Transformers: An End-to-End Exploration Codes for [Preprint] Chasing Sparsity in Vision Transformers: An End-to-End Explora
 64 Dec 8, 2022
64 Dec 8, 2022
WAGMA-SGD is a decentralized asynchronous SGD for distributed deep learning training based on model averaging.
WAGMA-SGD is a decentralized asynchronous SGD based on wait-avoiding group model averaging. The synchronization is relaxed by making the collectives externally-triggerable, namely, a collective can be initiated without requiring that all the processes enter it. It partially reduces the data within non-overlapping groups of process, improving the parallel scalability.
 6 Jun 18, 2022
6 Jun 18, 2022
Bagua is a flexible and performant distributed training algorithm development framework.
Bagua is a flexible and performant distributed training algorithm development framework.
 786 Dec 17, 2022
786 Dec 17, 2022

Heimdall watchtower automatically sends you emails to notify you of the latest progress of your deep learning programs.
This software automatically sends you emails to notify you of the latest progress of your deep learning programs.
 22 Dec 6, 2021
22 Dec 6, 2021

Spectral Tensor Train Parameterization of Deep Learning Layers
Spectral Tensor Train Parameterization of Deep Learning Layers This repository is the official implementation of our AISTATS 2021 paper titled "Spectr
 12 Oct 23, 2022
12 Oct 23, 2022

Python library to decrypt Airtag reports, as well as a InfluxDB/Grafana self-hosted dashboard example
Openhaystack-python This python daemon will allow you to gather your Openhaystack-based airtag reports and display them on a Grafana dashboard. You ca
 19 Jan 3, 2023
19 Jan 3, 2023
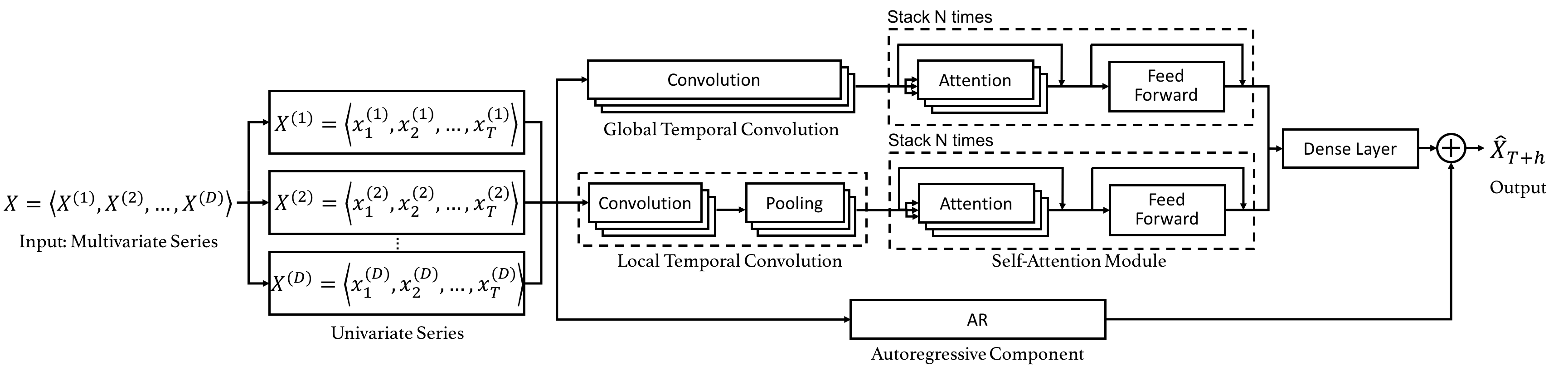
Code for the CIKM 2019 paper "DSANet: Dual Self-Attention Network for Multivariate Time Series Forecasting".
Dual Self-Attention Network for Multivariate Time Series Forecasting 20.10.26 Update: Due to the difficulty of installation and code maintenance cause
 223 Dec 16, 2022
223 Dec 16, 2022
Code for the paper "Balancing Training for Multilingual Neural Machine Translation, ACL 2020"
Balancing Training for Multilingual Neural Machine Translation Implementation of the paper Balancing Training for Multilingual Neural Machine Translat
 21 May 18, 2022
21 May 18, 2022
A highly sophisticated sequence-to-sequence model for code generation
CoderX A proof-of-concept AI system by Graham Neubig (June 30, 2021). About CoderX CoderX is a retrieval-based code generation AI system reminiscent o
 39 Aug 3, 2021
39 Aug 3, 2021
Shared code for training sentence embeddings with Flax / JAX
flax-sentence-embeddings This repository will be used to share code for the Flax / JAX community event to train sentence embeddings on 1B+ training pa
 23 Dec 30, 2022
23 Dec 30, 2022
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
 197 Nov 26, 2022
197 Nov 26, 2022
This is the code for our KILT leaderboard submission to the T-REx and zsRE tasks. It includes code for training a DPR model then continuing training with RAG.
KGI (Knowledge Graph Induction) for slot filling This is the code for our KILT leaderboard submission to the T-REx and zsRE tasks. It includes code fo
 72 Jan 6, 2023
72 Jan 6, 2023
Official code of paper "PGT: A Progressive Method for Training Models on Long Videos" on CVPR2021
PGT Code for paper PGT: A Progressive Method for Training Models on Long Videos. Install Run pip install -r requirements.txt. Run python setup.py buil
 27 Mar 30, 2022
27 Mar 30, 2022

This is the official repo for TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transformations at CVPR'21. According to some product reasons, we are not planning to release the training/testing codes and models. However, we will release the dataset and the scripts to prepare the dataset.
TransFill-Reference-Inpainting This is the official repo for TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transf
 80 Dec 8, 2022
80 Dec 8, 2022
The source codes for ACL 2021 paper 'BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data'
BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data This repository provides the implementation details for
 124 Dec 27, 2022
124 Dec 27, 2022
Meltano: ELT for the DataOps era. Meltano is open source, self-hosted, CLI-first, debuggable, and extensible.
Meltano is open source, self-hosted, CLI-first, debuggable, and extensible. Pipelines are code, ready to be version c
 625 Jan 2, 2023
625 Jan 2, 2023

YoloV5 implemented by TensorFlow2 , with support for training, evaluation and inference.
Efficient implementation of YOLOV5 in TensorFlow2
 202 Jan 6, 2023
202 Jan 6, 2023
nnDetection is a self-configuring framework for 3D (volumetric) medical object detection which can be applied to new data sets without manual intervention. It includes guides for 12 data sets that were used to develop and evaluate the performance of the proposed method.
What is nnDetection? Simultaneous localisation and categorization of objects in medical images, also referred to as medical object detection, is of hi
365 Jan 9, 2023

Orthogonal Over-Parameterized Training
The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is of great importance. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. See our previous work -- MHE for an in-depth introduction.
 11 Apr 18, 2022
11 Apr 18, 2022