335 Repositories
Python visual-inertial-odometry Libraries

Official repository of ICCV21 paper "Viewpoint Invariant Dense Matching for Visual Geolocalization"
Viewpoint Invariant Dense Matching for Visual Geolocalization: PyTorch implementation This is the implementation of the ICCV21 paper: G Berton, C. Mas
 44 Jan 3, 2023
44 Jan 3, 2023
![MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020]](https://github.com/uniBruce/Mead/raw/master/Figures/mead.png)
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020]
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020] by Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wa
 112 Dec 28, 2022
112 Dec 28, 2022

Code for Talking Face Generation by Adversarially Disentangled Audio-Visual Representation (AAAI 2019)
Talking Face Generation by Adversarially Disentangled Audio-Visual Representation (AAAI 2019) We propose Disentangled Audio-Visual System (DAVS) to ad
 750 Dec 23, 2022
750 Dec 23, 2022
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning. CVPR 2018
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning Tensorflow code and models for the paper: Large Scale Fine-Grained Categ
 187 Oct 1, 2022
187 Oct 1, 2022
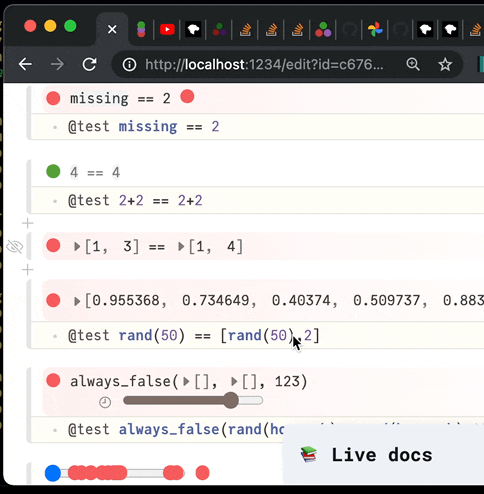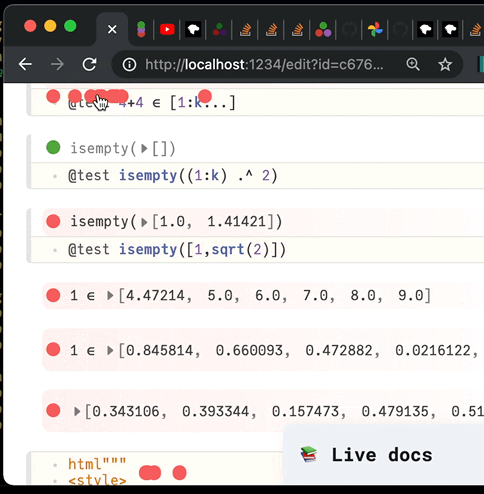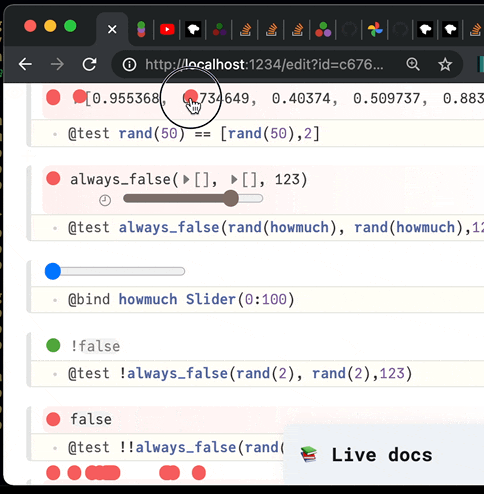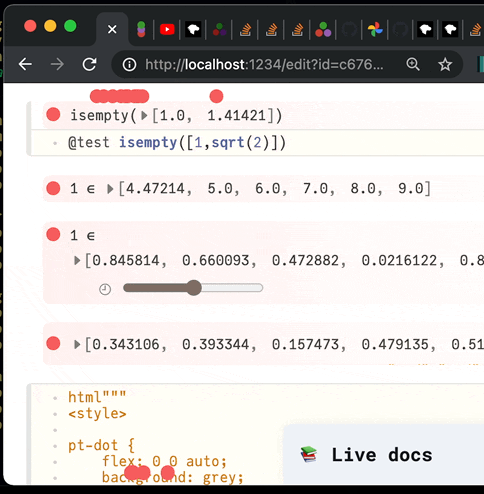
✔️ Visual, reactive testing library for Julia. Time machine included.
PlutoTest.jl (alpha release) Visual, reactive testing library for Julia A macro @test that you can use to verify your code's correctness. But instead
 68 Dec 20, 2022
68 Dec 20, 2022
A Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities
MPT A Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities. Implementation for our AAAI 2022 paper: Multi-
 4 May 8, 2022
4 May 8, 2022
Code of the paper "Shaping Visual Representations with Attributes for Few-Shot Learning (ASL)".
Shaping Visual Representations with Attributes for Few-Shot Learning This code implements the Shaping Visual Representations with Attributes for Few-S
 9 Sep 1, 2022
9 Sep 1, 2022
🦎 A NeoVim plugin for highlighting visual selections like in a normal document editor!
🦎 HighStr.nvim A NeoVim plugin for highlighting visual selections like in a normal document editor! Demo TL;DR HighStr.nvim is a NeoVim plugin writte
 222 Jan 3, 2023
222 Jan 3, 2023
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022
Make visual music sheets for thatskygame (graphical representations of the Sky keyboard)
sky-python-music-sheet-maker This program lets you make visual music sheets for Sky: Children of the Light. It will ask you a few questions, and does
 21 Aug 26, 2022
21 Aug 26, 2022
Official Implementation of SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations
Official Implementation of SimIPU SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations Since
 37 Dec 1, 2022
37 Dec 1, 2022

Visual Adversarial Imitation Learning using Variational Models (VMAIL)
Visual Adversarial Imitation Learning using Variational Models (VMAIL) This is the official implementation of the NeurIPS 2021 paper. Project website
 14 Nov 18, 2022
14 Nov 18, 2022

A concise grammar of interactive graphics, built on Vega.
Vega-Lite Vega-Lite provides a higher-level grammar for visual analysis that generates complete Vega specifications. You can find more details, docume
 4k Jan 8, 2023
4k Jan 8, 2023

Tensorflow 2 implementations of the C-SimCLR and C-BYOL self-supervised visual representation methods from "Compressive Visual Representations" (NeurIPS 2021)
Compressive Visual Representations This repository contains the source code for our paper, Compressive Visual Representations. We developed informatio
 30 Nov 23, 2022
30 Nov 23, 2022

ICRA 2021 - Robust Place Recognition using an Imaging Lidar
Robust Place Recognition using an Imaging Lidar A place recognition package using high-resolution imaging lidar. For best performance, a lidar equippe
 293 Dec 27, 2022
293 Dec 27, 2022

Class-Balanced Loss Based on Effective Number of Samples. CVPR 2019
Class-Balanced Loss Based on Effective Number of Samples Tensorflow code for the paper: Class-Balanced Loss Based on Effective Number of Samples Yin C
546 Jan 8, 2023
[CVPR 2020] Rethinking Class-Balanced Methods for Long-Tailed Visual Recognition from a Domain Adaptation Perspective
Rethinking Class-Balanced Methods for Long-Tailed Visual Recognition from a Domain Adaptation Perspective [Arxiv] This is PyTorch implementation of th
 22 Nov 19, 2022
22 Nov 19, 2022
![[NeurIPS 2020] Code for the paper](https://github.com/jiawei-ren/BalancedMetaSoftmax/raw/main/cifar-10.png)
[NeurIPS 2020] Code for the paper "Balanced Meta-Softmax for Long-Tailed Visual Recognition"
Balanced Meta-Softmax Code for the paper Balanced Meta-Softmax for Long-Tailed Visual Recognition Jiawei Ren, Cunjun Yu, Shunan Sheng, Xiao Ma, Haiyu
 65 Dec 21, 2022
65 Dec 21, 2022
[CVPR 2021] MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition
MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition (CVPR 2021) arXiv Prerequisite PyTorch = 1.2.0 Python3 torchvision PIL argpar
 51 Nov 11, 2022
51 Nov 11, 2022
This repository contains code for the paper "Disentangling Label Distribution for Long-tailed Visual Recognition", published at CVPR' 2021
Disentangling Label Distribution for Long-tailed Visual Recognition (CVPR 2021) Arxiv link Blog post This codebase is built on Causal Norm. Install co
 85 Oct 18, 2022
85 Oct 18, 2022

Official PyTorch Implementation of GAN-Supervised Dense Visual Alignment
GAN-Supervised Dense Visual Alignment — Official PyTorch Implementation Paper | Project Page | Video This repo contains training, evaluation and visua
 944 Jan 7, 2023
944 Jan 7, 2023
![[AAAI2022] Source code for our paper《Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning》](https://github.com/mettyz/SSVC/raw/main/asset/sample.gif)
[AAAI2022] Source code for our paper《Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning》
SSVC The source code for paper [Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning] samples of the
 7 Oct 26, 2022
7 Oct 26, 2022
HIVE: Evaluating the Human Interpretability of Visual Explanations
HIVE: Evaluating the Human Interpretability of Visual Explanations Project Page | Paper This repo provides the code for HIVE, a human evaluation frame
 16 Dec 13, 2022
16 Dec 13, 2022
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks - Official Project Page This repository contains the code develope
 1.7k Dec 18, 2022
1.7k Dec 18, 2022

A visual dataflow programming language for sklearn
Persimmon What is it? Persimmon is a visual dataflow language for creating sklearn pipelines. It represents functions as blocks, inputs and outputs ar
 194 Jan 4, 2023
194 Jan 4, 2023

OpenCodeBlocks an open-source tool for modular visual programing in python
OpenCodeBlocks OpenCodeBlocks is an open-source tool for modular visual programing in python ! Although for now the tool is in Beta and features are c
 1.1k Jan 6, 2023
1.1k Jan 6, 2023

Direct LiDAR Odometry: Fast Localization with Dense Point Clouds
Direct LiDAR Odometry: Fast Localization with Dense Point Clouds DLO is a lightweight and computationally-efficient frontend LiDAR odometry solution w
 369 Dec 30, 2022
369 Dec 30, 2022

Code for ICLR 2020 paper "VL-BERT: Pre-training of Generic Visual-Linguistic Representations".
VL-BERT By Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. This repository is an official implementation of the paper VL-BERT:
 698 Dec 18, 2022
698 Dec 18, 2022

Research Code for NeurIPS 2020 Spotlight paper "Large-Scale Adversarial Training for Vision-and-Language Representation Learning": UNITER adversarial training part
VILLA: Vision-and-Language Adversarial Training This is the official repository of VILLA (NeurIPS 2020 Spotlight). This repository currently supports
 109 Dec 31, 2022
109 Dec 31, 2022
![[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations](https://github.com/kdexd/virtex/raw/master/docs/_static/system_figure.jpg)
[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations
VirTex: Learning Visual Representations from Textual Annotations Karan Desai and Justin Johnson University of Michigan CVPR 2021 arxiv.org/abs/2006.06
 533 Dec 24, 2022
533 Dec 24, 2022

A Fast Knowledge Distillation Framework for Visual Recognition
FKD: A Fast Knowledge Distillation Framework for Visual Recognition Official PyTorch implementation of paper A Fast Knowledge Distillation Framework f
 129 Dec 24, 2022
129 Dec 24, 2022
PyTorch implementation of paper A Fast Knowledge Distillation Framework for Visual Recognition.
FKD: A Fast Knowledge Distillation Framework for Visual Recognition Official PyTorch implementation of paper A Fast Knowledge Distillation Framework f
129 Dec 24, 2022

A unified 3D Transformer Pipeline for visual synthesis
Overview This is the official repo for the paper: NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion. NÜWA is a unified multimodal p
 2.6k Jan 6, 2023
2.6k Jan 6, 2023
Predicting Event Memorability from Contextual Visual Semantics
Predicting Event Memorability from Contextual Visual Semantics
 0 Oct 6, 2021
0 Oct 6, 2021

PyTorch implementation of "Debiased Visual Question Answering from Feature and Sample Perspectives" (NeurIPS 2021)
D-VQA We provide the PyTorch implementation for Debiased Visual Question Answering from Feature and Sample Perspectives (NeurIPS 2021). Dependencies P
 19 Dec 22, 2022
19 Dec 22, 2022
This is a short program that takes the input from your microphone and uses OpenGL to draw a live colourful pattern
Visual-Music This is a short program that takes the input from your microphone and uses OpenGL to draw a live colourful pattern Installation and Setup
 1 Dec 26, 2021
1 Dec 26, 2021

Toward a Visual Concept Vocabulary for GAN Latent Space, ICCV 2021
Toward a Visual Concept Vocabulary for GAN Latent Space Code and data from the ICCV 2021 paper Sarah Schwettmann, Evan Hernandez, David Bau, Samuel Kl
 13 Dec 23, 2022
13 Dec 23, 2022

Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic [Paper] [Colab is coming soon] Approach Example Usage To r
 6 Dec 1, 2021
6 Dec 1, 2021
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic [Paper] [Colab is coming soon] Approach Example Usage To r
170 Jan 3, 2023

PyTorch code of paper "LiVLR: A Lightweight Visual-Linguistic Reasoning Framework for Video Question Answering"
LiVLR-VideoQA We propose a Lightweight Visual-Linguistic Reasoning framework (LiVLR) for VideoQA. The overview of LiVLR: Evaluation on MSRVTT-QA Datas
 7 Dec 30, 2022
7 Dec 30, 2022
A fast, dataset-agnostic, deep visual search engine for digital art history
imgs.ai imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings. It utilizes modern
 5 Dec 14, 2022
5 Dec 14, 2022

A dual benchmarking study of visual forgery and visual forensics techniques
A dual benchmarking study of facial forgery and facial forensics In recent years, visual forgery has reached a level of sophistication that humans can
 8 Jul 6, 2022
8 Jul 6, 2022

This repository contains all code and data for the Inside Out Visual Place Recognition task
Inside Out Visual Place Recognition This repository contains code and instructions to reproduce the results for the Inside Out Visual Place Recognitio
 15 May 21, 2022
15 May 21, 2022
HybVIO visual-inertial odometry and SLAM system
HybVIO A visual-inertial odometry system with an optional SLAM module. This is a research-oriented codebase, which has been published for the purposes
 320 Jan 3, 2023
320 Jan 3, 2023
Learning Convolutional Neural Networks with Interactive Visualization.
CNN Explainer An interactive visualization system designed to help non-experts learn about Convolutional Neural Networks (CNNs) For more information,
 6.3k Jan 1, 2023
6.3k Jan 1, 2023
Code for database and frontend of webpage for Neural Fields in Visual Computing and Beyond.
Neural Fields in Visual Computing—Complementary Webpage This is based on the amazing MiniConf project from Hendrik Strobelt and Sasha Rush—thank you!
 29 Nov 30, 2022
29 Nov 30, 2022
Revisiting Video Saliency: A Large-scale Benchmark and a New Model (CVPR18, PAMI19)
DHF1K =========================================================================== Wenguan Wang, J. Shen, M.-M Cheng and A. Borji, Revisiting Video Sal
 126 Dec 3, 2022
126 Dec 3, 2022
A unified 3D Transformer Pipeline for visual synthesis
Overview This is the official repo for the paper: "NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion". NÜWA is a unified multimodal
2.6k Jan 3, 2023
![PyTorch implementation for the visual prior component (i.e. perception module) of the Visually Grounded Physics Learner [Li et al., 2020].](https://github.com/ToruOwO/VGPL-Visual-Prior/raw/public/imgs/MassRope.gif)
PyTorch implementation for the visual prior component (i.e. perception module) of the Visually Grounded Physics Learner [Li et al., 2020].
VGPL-Visual-Prior PyTorch implementation for the visual prior component (i.e. perception module) of the Visually Grounded Physics Learner (VGPL). Give
 8 Dec 29, 2022
8 Dec 29, 2022
Repo for our ICML21 paper Unsupervised Learning of Visual 3D Keypoints for Control
Unsupervised Learning of Visual 3D Keypoints for Control [Project Website] [Paper] Boyuan Chen1, Pieter Abbeel1, Deepak Pathak2 1UC Berkeley 2Carnegie
 34 Jul 22, 2022
34 Jul 22, 2022

Creating multimodal multitask models
Fusion Brain Challenge The English version of the document can be found here. Обновления 01.11 Мы выкладываем пример данных, аналогичных private test
 43 Nov 28, 2022
43 Nov 28, 2022
Falcon: Interactive Visual Analysis for Big Data
Falcon: Interactive Visual Analysis for Big Data Crossfilter millions of records without latencies. This project is work in progress and not documente
803 Dec 27, 2022
An improvement of FasterGICP: Acceptance-rejection Sampling based 3D Lidar Odometry
fasterGICP This package is an improvement of fast_gicp Please cite our paper if possible. W. Jikai, M. Xu, F. Farzin, D. Dai and Z. Chen, "FasterGICP:
 79 Dec 31, 2022
79 Dec 31, 2022
![[NeurIPS 2021 Spotlight] Code for Learning to Compose Visual Relations](https://github.com/nanlliu/compose-visual-relations/raw/master/samples/generation_samples.gif)
[NeurIPS 2021 Spotlight] Code for Learning to Compose Visual Relations
Learning to Compose Visual Relations This is the pytorch codebase for the NeurIPS 2021 Spotlight paper Learning to Compose Visual Relations. Demo Imag
 88 Jan 4, 2023
88 Jan 4, 2023
Visual Memorability for Robotic Interestingness via Unsupervised Online Learning (ECCV 2020 Oral and TRO)
Visual Interestingness Refer to the project description for more details. This code based on the following paper. Chen Wang, Yuheng Qiu, Wenshan Wang,
 36 Sep 8, 2022
36 Sep 8, 2022

Blind visual quality assessment on 360° Video based on progressive learning
Blind visual quality assessment on omnidirectional or 360 video (ProVQA) Blind VQA for 360° Video via Progressively Learning from Pixels, Frames and V
 5 Jan 6, 2023
5 Jan 6, 2023

Implementation of DocFormer: End-to-End Transformer for Document Understanding, a multi-modal transformer based architecture for the task of Visual Document Understanding (VDU)
DocFormer - PyTorch Implementation of DocFormer: End-to-End Transformer for Document Understanding, a multi-modal transformer based architecture for t
 171 Jan 6, 2023
171 Jan 6, 2023
Towards Calibrated Model for Long-Tailed Visual Recognition from Prior Perspective
Towards Calibrated Model for Long-Tailed Visual Recognition from Prior Perspective Zhengzhuo Xu, Zenghao Chai, Chun Yuan This is the PyTorch implement
 16 Dec 15, 2022
16 Dec 15, 2022

SalGAN: Visual Saliency Prediction with Generative Adversarial Networks
SalGAN: Visual Saliency Prediction with Adversarial Networks Junting Pan Cristian Canton Ferrer Kevin McGuinness Noel O'Connor Jordi Torres Elisa Sayr
 347 Nov 22, 2022
347 Nov 22, 2022

PyTorch implementation of MulMON
MulMON This repository contains a PyTorch implementation of the paper: Learning Object-Centric Representations of Multi-object Scenes from Multiple Vi
 16 Nov 3, 2022
16 Nov 3, 2022

LIMEcraft: Handcrafted superpixel selectionand inspection for Visual eXplanations
LIMEcraft LIMEcraft: Handcrafted superpixel selectionand inspection for Visual eXplanations The LIMEcraft algorithm is an explanatory method based on
 4 Aug 1, 2022
4 Aug 1, 2022

Summary of related papers on visual attention
This repo is built for paper: Attention Mechanisms in Computer Vision: A Survey paper Vision-Attention-Papers Channel attention Spatial attention Temp
 2.1k Dec 30, 2022
2.1k Dec 30, 2022

RRxIO - Robust Radar Visual/Thermal Inertial Odometry: Robust and accurate state estimation even in challenging visual conditions.
RRxIO - Robust Radar Visual/Thermal Inertial Odometry RRxIO offers robust and accurate state estimation even in challenging visual conditions. RRxIO c
 64 Dec 29, 2022
64 Dec 29, 2022

A "finish the lyrics" game using Spotify, YouTube Transcript, and YouTube Search APIs, coupled with visual machine learning
Singify Introducing Singify, the party game! Challenge your friend to who knows songs better. Play random songs from your very own Spotify playlist an
 4 Nov 19, 2021
4 Nov 19, 2021
Visual Interaction with Code - A portable visual debugger for python
VIC Visual Interaction with Code A simple tool for debugging and interacting with running python code. This tool is designed to make it easy to inspec
 1 Nov 16, 2021
1 Nov 16, 2021

PyTorch implementation for paper "Full-Body Visual Self-Modeling of Robot Morphologies".
Full-Body Visual Self-Modeling of Robot Morphologies Boyuan Chen, Robert Kwiatkowskig, Carl Vondrick, Hod Lipson Columbia University Project Website |
 32 Jan 2, 2023
32 Jan 2, 2023
Generative Art Using Neural Visual Grammars and Dual Encoders
Generative Art Using Neural Visual Grammars and Dual Encoders Arnheim 1 The original algorithm from the paper Generative Art Using Neural Visual Gramm
 231 Jan 5, 2023
231 Jan 5, 2023

ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning. In ICCV, 2021.
ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning This repository contains the code for our ICCV 202
 28 Nov 8, 2022
28 Nov 8, 2022
SAT: 2D Semantics Assisted Training for 3D Visual Grounding, ICCV 2021 (Oral)
SAT: 2D Semantics Assisted Training for 3D Visual Grounding SAT: 2D Semantics Assisted Training for 3D Visual Grounding by Zhengyuan Yang, Songyang Zh
 22 Nov 30, 2022
22 Nov 30, 2022
![[AAAI-2021] Visual Boundary Knowledge Translation for Foreground Segmentation](https://user-images.githubusercontent.com/6896182/141064192-3dad4369-7307-459a-8bb3-5e9d639239af.png)
[AAAI-2021] Visual Boundary Knowledge Translation for Foreground Segmentation
Trans-Net Code for (Visual Boundary Knowledge Translation for Foreground Segmentation, AAAI2021). [https://ojs.aaai.org/index.php/AAAI/article/view/16
 2 Mar 4, 2022
2 Mar 4, 2022

Python Indent - Correct python indentation in Visual Studio Code.
Python Indent Correct python indentation in Visual Studio Code. See the extension on the VSCode Marketplace and its source code on GitHub. Please cons
 57 Dec 15, 2022
57 Dec 15, 2022

C++ Environment InitiatorVisual Studio Code C / C++ Environment Initiator
Visual Studio Code C / C++ Environment Initiator Latest Version : v 1.0.1(2021/11/08) .exe link here About : Visual Studio Code에서 C/C++환경을 MinGW GCC/G
 2 Dec 19, 2021
2 Dec 19, 2021
A Differentiable Recipe for Learning Visual Non-Prehensile Planar Manipulation
A Differentiable Recipe for Learning Visual Non-Prehensile Planar Manipulation This repository contains the source code of the paper A Differentiable
 2 May 5, 2022
2 May 5, 2022

This codebase proposes modular light python and pytorch implementations of several LiDAR Odometry methods
pyLiDAR-SLAM This codebase proposes modular light python and pytorch implementations of several LiDAR Odometry methods, which can easily be evaluated
 208 Dec 16, 2022
208 Dec 16, 2022
[ICCV 2021 Oral] Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Just Ask: Learning to Answer Questions from Millions of Narrated Videos Webpage • Demo • Paper This repository provides the code for our paper, includ
 87 Jan 5, 2023
87 Jan 5, 2023
A collection of differentiable SVD methods and also the official implementation of the ICCV21 paper "Why Approximate Matrix Square Root Outperforms Accurate SVD in Global Covariance Pooling?"
Differentiable SVD Introduction This repository contains: The official Pytorch implementation of ICCV21 paper Why Approximate Matrix Square Root Outpe
 32 Dec 25, 2022
32 Dec 25, 2022
Code for Greedy Gradient Ensemble for Visual Question Answering (ICCV 2021, Oral)
Greedy Gradient Ensemble for De-biased VQA Code release for "Greedy Gradient Ensemble for Robust Visual Question Answering" (ICCV 2021, Oral). GGE can
 21 Jun 29, 2022
21 Jun 29, 2022
This repo holds codes of the ICCV21 paper: Visual Alignment Constraint for Continuous Sign Language Recognition.
VAC_CSLR This repo holds codes of the paper: Visual Alignment Constraint for Continuous Sign Language Recognition.(ICCV 2021) [paper] Prerequisites Th
 64 Dec 19, 2022
64 Dec 19, 2022

Codes for CVPR2021 paper "PWCLO-Net: Deep LiDAR Odometry in 3D Point Clouds Using Hierarchical Embedding Mask Optimization"
PWCLO-Net: Deep LiDAR Odometry in 3D Point Clouds Using Hierarchical Embedding Mask Optimization (CVPR 2021) This is the official implementation of PW
 42 Dec 18, 2022
42 Dec 18, 2022

Distilling Motion Planner Augmented Policies into Visual Control Policies for Robot Manipulation (CoRL 2021)
Distilling Motion Planner Augmented Policies into Visual Control Policies for Robot Manipulation [Project website] [Paper] This project is a PyTorch i
 6 Feb 28, 2022
6 Feb 28, 2022

SW components and demos for visual kinship recognition. An emphasis is put on the FIW dataset-- data loaders, benchmarks, results in summary.
FIW Data Development Kit Table of Contents Introduction Families In the Wild Database Publications Organization To Do License Getting Involved Introdu
 12 Jun 4, 2022
12 Jun 4, 2022

A treasure chest for visual recognition powered by PaddlePaddle
简体中文 | English PaddleClas 简介 飞桨图像识别套件PaddleClas是飞桨为工业界和学术界所准备的一个图像识别任务的工具集,助力使用者训练出更好的视觉模型和应用落地。 近期更新 2021.11.1 发布PP-ShiTu技术报告,新增饮料识别demo 2021.10.23 发
 4.6k Dec 31, 2022
4.6k Dec 31, 2022
The code for MM2021 paper "Multi-Level Counterfactual Contrast for Visual Commonsense Reasoning"
The Code for MM2021 paper "Multi-Level Counterfactual Contrast for Visual Commonsense Reasoning" Setting up and using the repo Get the dataset. Follow
 4 Apr 20, 2022
4 Apr 20, 2022
[IROS2021] NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
NYU-VPR This repository provides the experiment code for the paper Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymiza
 22 Sep 28, 2022
22 Sep 28, 2022

Dynamic Visual Reasoning by Learning Differentiable Physics Models from Video and Language (NeurIPS 2021)
VRDP (NeurIPS 2021) Dynamic Visual Reasoning by Learning Differentiable Physics Models from Video and Language Mingyu Ding, Zhenfang Chen, Tao Du, Pin
 36 Sep 20, 2022
36 Sep 20, 2022
Code Release for the paper "TriBERT: Full-body Human-centric Audio-visual Representation Learning for Visual Sound Separation"
TriBERT This repository contains the code for the NeurIPS 2021 paper titled "TriBERT: Full-body Human-centric Audio-visual Representation Learning for
 8 Aug 31, 2022
8 Aug 31, 2022
Audio Visual Emotion Recognition using TDA
Audio Visual Emotion Recognition using TDA RAVDESS database with two datasets analyzed: Video and Audio dataset: Audio-Dataset: https://www.kaggle.com
 3 May 11, 2022
3 May 11, 2022

Official implementation of NeurIPS 2021 paper "Contextual Similarity Aggregation with Self-attention for Visual Re-ranking"
CSA: Contextual Similarity Aggregation with Self-attention for Visual Re-ranking PyTorch training code for CSA (Contextual Similarity Aggregation). We
 19 Oct 21, 2022
19 Oct 21, 2022
This repository contains code and data for "On the Multimodal Person Verification Using Audio-Visual-Thermal Data"
trimodal_person_verification This repository contains the code, and preprocessed dataset featured in "A Study of Multimodal Person Verification Using
 7 Aug 31, 2022
7 Aug 31, 2022

A Context-aware Visual Attention-based training pipeline for Object Detection from a Webpage screenshot!
CoVA: Context-aware Visual Attention for Webpage Information Extraction Abstract Webpage information extraction (WIE) is an important step to create k
 41 Jan 1, 2023
41 Jan 1, 2023

Efficient Training of Visual Transformers with Small Datasets
Official codes for "Efficient Training of Visual Transformers with Small Datasets", NerIPS 2021.
 112 Dec 25, 2022
112 Dec 25, 2022
Official implementation of NeurIPS 2021 paper "Contextual Similarity Aggregation with Self-attention for Visual Re-ranking"
CSA: Contextual Similarity Aggregation with Self-attention for Visual Re-ranking PyTorch training code for CSA (Contextual Similarity Aggregation). We
19 Oct 21, 2022

This repository is the official implementation of Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regularized Fine-Tuning (NeurIPS21).
Core-tuning This repository is the official implementation of ``Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regular
 18 Dec 17, 2022
18 Dec 17, 2022
VOneNet: CNNs with a Primary Visual Cortex Front-End
VOneNet: CNNs with a Primary Visual Cortex Front-End A family of biologically-inspired Convolutional Neural Networks (CNNs). VOneNets have the followi
 99 Dec 22, 2022
99 Dec 22, 2022
The official PyTorch implementation of paper BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition Boyan Zhou, Quan Cui, Xiu-Shen Wei*, Zhao-Min Chen This repo
 616 Dec 21, 2022
616 Dec 21, 2022

JittorVis - Visual understanding of deep learning models
JittorVis: Visual understanding of deep learning model JittorVis is an open-source library for understanding the inner workings of Jittor models by vi
 182 Jan 6, 2023
182 Jan 6, 2023

A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning
CLEVR Dataset Generation This is the code used to generate the CLEVR dataset as described in the paper: CLEVR: A Diagnostic Dataset for Compositional
 503 Jan 4, 2023
503 Jan 4, 2023
pytorch implementation of "Contrastive Multiview Coding", "Momentum Contrast for Unsupervised Visual Representation Learning", and "Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination"
Unofficial implementation: MoCo: Momentum Contrast for Unsupervised Visual Representation Learning (Paper) InsDis: Unsupervised Feature Learning via N
16 Nov 4, 2020

Official implementation of deep-multi-trajectory-based single object tracking (IEEE T-CSVT 2021).
DeepMTA_PyTorch Officical PyTorch Implementation of "Dynamic Attention-guided Multi-TrajectoryAnalysis for Single Object Tracking", Xiao Wang, Zhe Che
 7 Dec 3, 2022
7 Dec 3, 2022
Official implementation of A cappella: Audio-visual Singing VoiceSeparation, from BMVC21
Y-Net Official implementation of A cappella: Audio-visual Singing VoiceSeparation, British Machine Vision Conference 2021 Project page: ipcv.github.io
 12 Oct 22, 2022
12 Oct 22, 2022