926 Repositories
Python memory-efficient-attention Libraries
STMTrack: Template-free Visual Tracking with Space-time Memory Networks
STMTrack This is the official implementation of the paper: STMTrack: Template-free Visual Tracking with Space-time Memory Networks. Setup Prepare Anac
 62 Dec 21, 2022
62 Dec 21, 2022
efficient neural audio synthesis in the waveform domain
neural waveshaping synthesis real-time neural audio synthesis in the waveform domain paper • website • colab • audio by Ben Hayes, Charalampos Saitis,
 169 Dec 23, 2022
169 Dec 23, 2022
LiDAR R-CNN: An Efficient and Universal 3D Object Detector
LiDAR R-CNN: An Efficient and Universal 3D Object Detector Introduction This is the official code of LiDAR R-CNN: An Efficient and Universal 3D Object
 295 Jan 5, 2023
295 Jan 5, 2023
Plug and play transformer you can find network structure and official complete code by clicking List
Plug-and-play Module Plug and play transformer you can find network structure and official complete code by clicking List The following is to quickly
 8 Mar 27, 2022
8 Mar 27, 2022

A collection of 100 Deep Learning images and visualizations
A collection of Deep Learning images and visualizations. The project has been developed by the AI Summer team and currently contains almost 100 images.
 65 Sep 12, 2022
65 Sep 12, 2022

S2-BNN: Bridging the Gap Between Self-Supervised Real and 1-bit Neural Networks via Guided Distribution Calibration (CVPR 2021)
S2-BNN (Self-supervised Binary Neural Networks Using Distillation Loss) This is the official pytorch implementation of our paper: "S2-BNN: Bridging th
 52 Dec 24, 2022
52 Dec 24, 2022

PyTorch code for our paper "Image Super-Resolution with Non-Local Sparse Attention" (CVPR2021).
Image Super-Resolution with Non-Local Sparse Attention This repository is for NLSN introduced in the following paper "Image Super-Resolution with Non-
 143 Dec 28, 2022
143 Dec 28, 2022
A collection of 100 Deep Learning images and visualizations
A collection of Deep Learning images and visualizations. The project has been developed by the AI Summer team and currently contains almost 100 images.
65 Sep 12, 2022

IJCAI2020 & IJCV 2020 :city_sunrise: Unsupervised Scene Adaptation with Memory Regularization in vivo
Seg_Uncertainty In this repo, we provide the code for the two papers, i.e., MRNet:Unsupervised Scene Adaptation with Memory Regularization in vivo, IJ
 348 Jan 5, 2023
348 Jan 5, 2023

Official PyTorch implementation of UACANet: Uncertainty Aware Context Attention for Polyp Segmentation
UACANet: Uncertainty Aware Context Attention for Polyp Segmentation Official pytorch implementation of UACANet: Uncertainty Aware Context Attention fo
 85 Dec 14, 2022
85 Dec 14, 2022

2021-MICCAI-Progressively Normalized Self-Attention Network for Video Polyp Segmentation
2021-MICCAI-Progressively Normalized Self-Attention Network for Video Polyp Segmentation Authors: Ge-Peng Ji*, Yu-Cheng Chou*, Deng-Ping Fan, Geng Che
 85 Dec 30, 2022
85 Dec 30, 2022

MemStream: Memory-Based Anomaly Detection in Multi-Aspect Streams with Concept Drift
MemStream Implementation of MemStream: Memory-Based Anomaly Detection in Multi-Aspect Streams with Concept Drift . Siddharth Bhatia, Arjit Jain, Shivi
 61 Dec 2, 2022
61 Dec 2, 2022

Code for KDD'20 "An Efficient Neighborhood-based Interaction Model for Recommendation on Heterogeneous Graph"
Heterogeneous INteract and aggreGatE (GraphHINGE) This is a pytorch implementation of GraphHINGE model. This is the experiment code in the following w
 69 Nov 24, 2022
69 Nov 24, 2022

Codes for TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised Object Localization.
TS-CAM: Token Semantic Coupled Attention Map for Weakly SupervisedObject Localization This is the official implementaion of paper TS-CAM: Token Semant
 112 Jan 2, 2023
112 Jan 2, 2023
![[Preprint]](https://github.com/VITA-Group/SViTE/raw/main/Figs/res.png)
[Preprint] "Chasing Sparsity in Vision Transformers: An End-to-End Exploration" by Tianlong Chen, Yu Cheng, Zhe Gan, Lu Yuan, Lei Zhang, Zhangyang Wang
Chasing Sparsity in Vision Transformers: An End-to-End Exploration Codes for [Preprint] Chasing Sparsity in Vision Transformers: An End-to-End Explora
 64 Dec 8, 2022
64 Dec 8, 2022
Selective Wavelet Attention Learning for Single Image Deraining
SWAL Code for Paper "Selective Wavelet Attention Learning for Single Image Deraining" Prerequisites Python 3 PyTorch Models We provide the models trai
 9 Jun 17, 2022
9 Jun 17, 2022
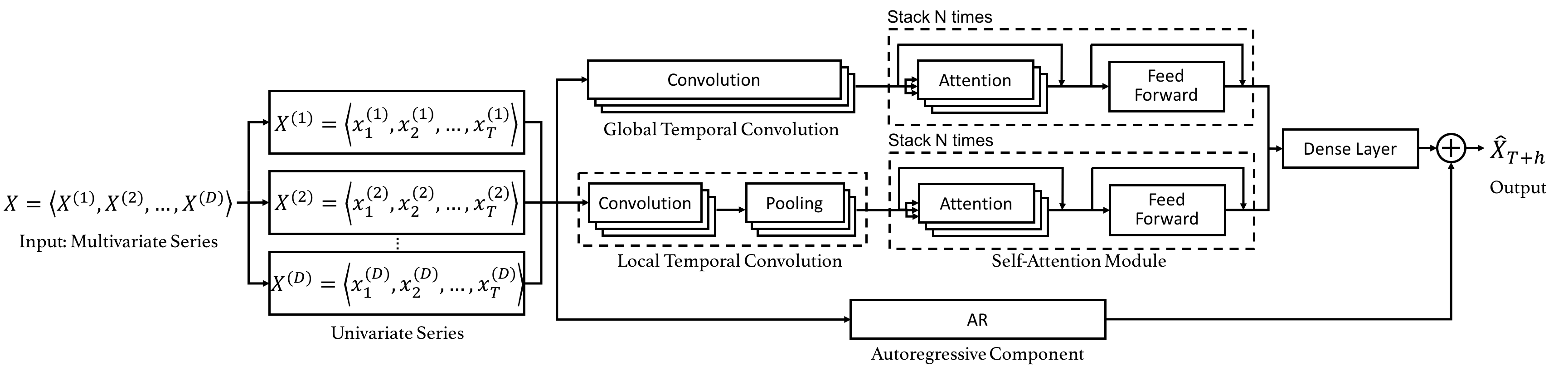
Code for the CIKM 2019 paper "DSANet: Dual Self-Attention Network for Multivariate Time Series Forecasting".
Dual Self-Attention Network for Multivariate Time Series Forecasting 20.10.26 Update: Due to the difficulty of installation and code maintenance cause
 223 Dec 16, 2022
223 Dec 16, 2022
ElegantRL is featured with lightweight, efficient and stable, for researchers and practitioners.
Lightweight, efficient and stable implementations of deep reinforcement learning algorithms using PyTorch. 🔥
 2.5k Jan 8, 2023
2.5k Jan 8, 2023

Code implementation of Data Efficient Stagewise Knowledge Distillation paper.
Data Efficient Stagewise Knowledge Distillation Table of Contents Data Efficient Stagewise Knowledge Distillation Table of Contents Requirements Image
 112 Dec 2, 2022
112 Dec 2, 2022

Multi-Task Temporal Shift Attention Networks for On-Device Contactless Vitals Measurement (NeurIPS 2020)
MTTS-CAN: Multi-Task Temporal Shift Attention Networks for On-Device Contactless Vitals Measurement Paper Xin Liu, Josh Fromm, Shwetak Patel, Daniel M
 106 Dec 30, 2022
106 Dec 30, 2022

An Efficient Implementation of Analytic Mesh Algorithm for 3D Iso-surface Extraction from Neural Networks
AnalyticMesh Analytic Marching is an exact meshing solution from neural networks. Compared to standard methods, it completely avoids geometric and top
 45 Dec 21, 2022
45 Dec 21, 2022

PPLNN is a Primitive Library for Neural Network is a high-performance deep-learning inference engine for efficient AI inferencing
PPLNN is a Primitive Library for Neural Network is a high-performance deep-learning inference engine for efficient AI inferencing
 943 Jan 7, 2023
943 Jan 7, 2023

PyTorch implementation of ARM-Net: Adaptive Relation Modeling Network for Structured Data.
A ready-to-use framework of latest models for structured (tabular) data learning with PyTorch. Applications include recommendation, CRT prediction, healthcare analytics, and etc.
 48 Nov 30, 2022
48 Nov 30, 2022
seno-blockchain is just a fork of Chia, designed to be efficient, decentralized, and secure
seno-blockchain https://seno.uno Seno is just a fork of Chia, designed to be efficient, decentralized, and secure. Here are some of the features and b
 27 Jul 2, 2022
27 Jul 2, 2022

Attention mechanism with MNIST dataset
[TensorFlow] Attention mechanism with MNIST dataset Usage $ python run.py Result Training Loss graph. Test Each figure shows input digit, attention ma
 12 Jun 10, 2022
12 Jun 10, 2022

Shared Attention for Multi-label Zero-shot Learning
Shared Attention for Multi-label Zero-shot Learning Overview This repository contains the implementation of Shared Attention for Multi-label Zero-shot
 26 Dec 14, 2022
26 Dec 14, 2022

codes for paper Combining Dynamic Local Context Focus and Dependency Cluster Attention for Aspect-level sentiment classification
DLCF-DCA codes for paper Combining Dynamic Local Context Focus and Dependency Cluster Attention for Aspect-level sentiment classification. submitted t
 15 Aug 30, 2022
15 Aug 30, 2022

DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
DatasetGAN This is the official code and data release for: DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort Yuxuan Zhang*, Huan Li
 302 Jan 5, 2023
302 Jan 5, 2023
Compositional and Parameter-Efficient Representations for Large Knowledge Graphs
NodePiece - Compositional and Parameter-Efficient Representations for Large Knowledge Graphs NodePiece is a "tokenizer" for reducing entity vocabulary
 107 Jan 4, 2023
107 Jan 4, 2023
FinGAT: A Financial Graph Attention Networkto Recommend Top-K Profitable Stocks
FinGAT: A Financial Graph Attention Networkto Recommend Top-K Profitable Stocks This is our implementation for the paper: FinGAT: A Financial Graph At
 64 Dec 13, 2022
64 Dec 13, 2022
Pretraining Representations For Data-Efficient Reinforcement Learning
Pretraining Representations For Data-Efficient Reinforcement Learning Max Schwarzer, Nitarshan Rajkumar, Michael Noukhovitch, Ankesh Anand, Laurent Ch
 40 Dec 11, 2022
40 Dec 11, 2022

Experiment about Deep Person Re-identification with EfficientNet-v2
We evaluated the baseline with Resnet50 and Efficienet-v2 without using pretrained models. Also Resnet50-IBN-A and Efficientnet-v2 using pretrained on ImageNet. We used two datasets: Market-1501 and CUHK03.
 77 Jan 3, 2023
77 Jan 3, 2023

Episodic Transformer (E.T.) is a novel attention-based architecture for vision-and-language navigation. E.T. is based on a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions.
Episodic Transformers (E.T.) Episodic Transformer for Vision-and-Language Navigation Alexander Pashevich, Cordelia Schmid, Chen Sun Episodic Transform
 62 Dec 24, 2022
62 Dec 24, 2022

LieTransformer: Equivariant Self-Attention for Lie Groups
LieTransformer This repository contains the implementation of the LieTransformer used for experiments in the paper LieTransformer: Equivariant Self-At
 50 Dec 28, 2022
50 Dec 28, 2022

This repository contains all the source code that is needed for the project : An Efficient Pipeline For Bloom’s Taxonomy Using Natural Language Processing and Deep Learning
Pipeline For NLP with Bloom's Taxonomy Using Improved Question Classification and Question Generation using Deep Learning This repository contains all
 9 Jul 17, 2021
9 Jul 17, 2021

Implementation of Uformer, Attention-based Unet, in Pytorch
Uformer - Pytorch Implementation of Uformer, Attention-based Unet, in Pytorch. It will only offer the concat-cross-skip connection. This repository wi
 72 Dec 19, 2022
72 Dec 19, 2022
Official implementation of "SinIR: Efficient General Image Manipulation with Single Image Reconstruction" (ICML 2021)
SinIR (Official Implementation) Requirements To install requirements: pip install -r requirements.txt We used Python 3.7.4 and f-strings which are in
 47 Oct 11, 2022
47 Oct 11, 2022

Official implementation of "SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers"
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers Figure 1: Performance of SegFormer-B0 to SegFormer-B5. Project page
 1.4k Dec 31, 2022
1.4k Dec 31, 2022
A highly efficient, fast, powerful and light-weight anime downloader and streamer for your favorite anime.
AnimDL - Download & Stream Your Favorite Anime AnimDL is an incredibly powerful tool for downloading and streaming anime. Core features Abuses the dev
 759 Jan 8, 2023
759 Jan 8, 2023

Shuffle Attention for MobileNetV3
SA-MobileNetV3 Shuffle Attention for MobileNetV3 Train Run the following command for train model on your own dataset: python train.py --dataset mnist
 36 Dec 28, 2022
36 Dec 28, 2022
EPSANet:An Efficient Pyramid Split Attention Block on Convolutional Neural Network
EPSANet:An Efficient Pyramid Split Attention Block on Convolutional Neural Network This repo contains the official Pytorch implementaion code and conf
 175 Jan 7, 2023
175 Jan 7, 2023
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
 192 Dec 23, 2022
192 Dec 23, 2022
FANet - Real-time Semantic Segmentation with Fast Attention
FANet Real-time Semantic Segmentation with Fast Attention Ping Hu, Federico Perazzi, Fabian Caba Heilbron, Oliver Wang, Zhe Lin, Kate Saenko , Stan Sc
 42 Nov 30, 2022
42 Nov 30, 2022

Official implement of "CAT: Cross Attention in Vision Transformer".
CAT: Cross Attention in Vision Transformer This is official implement of "CAT: Cross Attention in Vision Transformer". Abstract Since Transformer has
 100 Dec 15, 2022
100 Dec 15, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 31 Dec 8, 2022
31 Dec 8, 2022

Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch
Segformer - Pytorch Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch. Install $ pip install segformer-pytorch
208 Dec 25, 2022
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
STCN Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [a
 456 Dec 12, 2022
456 Dec 12, 2022

Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers.
Less is More: Pay Less Attention in Vision Transformers Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers. By
 73 Jan 1, 2023
73 Jan 1, 2023

The official PyTorch implementation of recent paper - SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training
This repository is the official PyTorch implementation of SAINT. Find the paper on arxiv SAINT: Improved Neural Networks for Tabular Data via Row Atte
 284 Dec 21, 2022
284 Dec 21, 2022
Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time.
 360 Dec 28, 2022
360 Dec 28, 2022

Unofficial PyTorch implementation of Attention Free Transformer (AFT) layers by Apple Inc.
aft-pytorch Unofficial PyTorch implementation of Attention Free Transformer's layers by Zhai, et al. [abs, pdf] from Apple Inc. Installation You can i
 184 Dec 12, 2022
184 Dec 12, 2022

PyTorch implementation of Pay Attention to MLPs
gMLP PyTorch implementation of Pay Attention to MLPs. Quickstart Clone this repository. git clone https://github.com/jaketae/g-mlp.git Navigate to th
 34 Dec 13, 2022
34 Dec 13, 2022

DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification Created by Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, Ch
 414 Jan 1, 2023
414 Jan 1, 2023

Deformable DETR is an efficient and fast-converging end-to-end object detector.
Deformable DETR: Deformable Transformers for End-to-End Object Detection.
 2k Jan 5, 2023
2k Jan 5, 2023
Paddle implementation for "Highly Efficient Knowledge Graph Embedding Learning with Closed-Form Orthogonal Procrustes Analysis" (NAACL 2021)
ProcrustEs-KGE Paddle implementation for Highly Efficient Knowledge Graph Embedding Learning with Orthogonal Procrustes Analysis 🙈 A more detailed re
 4 Jun 9, 2021
4 Jun 9, 2021

Efficient Lottery Ticket Finding: Less Data is More
The lottery ticket hypothesis (LTH) reveals the existence of winning tickets (sparse but critical subnetworks) for dense networks, that can be trained in isolation from random initialization to match the latter’s accuracies.
20 Sep 4, 2022
PyTorch Code of "Memory In Memory: A Predictive Neural Network for Learning Higher-Order Non-Stationarity from Spatiotemporal Dynamics"
Memory In Memory Networks It is based on the paper Memory In Memory: A Predictive Neural Network for Learning Higher-Order Non-Stationarity from Spati
 12 May 30, 2022
12 May 30, 2022
External Attention Network
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks paper : https://arxiv.org/abs/2105.02358 EAMLP will come soon Jitto
 357 Dec 11, 2022
357 Dec 11, 2022

Code for the paper "How Attentive are Graph Attention Networks?"
How Attentive are Graph Attention Networks? This repository is the official implementation of How Attentive are Graph Attention Networks?. The PyTorch
 175 Dec 29, 2022
175 Dec 29, 2022

An Efficient Training Approach for Very Large Scale Face Recognition or F²C for simplicity.
Fast Face Classification (F²C) This is the code of our paper An Efficient Training Approach for Very Large Scale Face Recognition or F²C for simplicit
 33 Jun 27, 2021
33 Jun 27, 2021

Attention-driven Robot Manipulation (ARM) which includes Q-attention
Attention-driven Robotic Manipulation (ARM) This codebase is home to: Q-attention: Enabling Efficient Learning for Vision-based Robotic Manipulation I
 84 Dec 29, 2022
84 Dec 29, 2022
Implements MLP-Mixer: An all-MLP Architecture for Vision.
MLP-Mixer-CIFAR10 This repository implements MLP-Mixer as proposed in MLP-Mixer: An all-MLP Architecture for Vision. The paper introduces an all MLP (
 51 Jan 4, 2023
51 Jan 4, 2023
This is the repo for the paper `SumGNN: Multi-typed Drug Interaction Prediction via Efficient Knowledge Graph Summarization'. (published in Bioinformatics'21)
SumGNN: Multi-typed Drug Interaction Prediction via Efficient Knowledge Graph Summarization This is the code for our paper ``SumGNN: Multi-typed Drug
 58 Dec 21, 2022
58 Dec 21, 2022

Implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
CrossViT : Cross-Attention Multi-Scale Vision Transformer for Image Classification This is an unofficial PyTorch implementation of CrossViT: Cross-Att
103 Nov 25, 2022
This is an official implementation for "ResT: An Efficient Transformer for Visual Recognition".
ResT By Qing-Long Zhang and Yu-Bin Yang [State Key Laboratory for Novel Software Technology at Nanjing University] This repo is the official implement
 222 Dec 13, 2022
222 Dec 13, 2022
Official code repository of the paper Learning Associative Inference Using Fast Weight Memory by Schlag et al.
Learning Associative Inference Using Fast Weight Memory This repository contains the offical code for the paper Learning Associative Inference Using F
 18 Oct 12, 2022
18 Oct 12, 2022
An implementation demo of the ICLR 2021 paper Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks in PyTorch.
Neural Attention Distillation This is an implementation demo of the ICLR 2021 paper Neural Attention Distillation: Erasing Backdoor Triggers from Deep
 84 Jan 4, 2023
84 Jan 4, 2023

Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
12.6k Jan 9, 2023
Github project for Attention-guided Temporal Coherent Video Object Matting.
Attention-guided Temporal Coherent Video Object Matting This is the Github project for our paper Attention-guided Temporal Coherent Video Object Matti
 71 Dec 19, 2022
71 Dec 19, 2022

Efficient 6-DoF Grasp Generation in Cluttered Scenes
Contact-GraspNet Contact-GraspNet: Efficient 6-DoF Grasp Generation in Cluttered Scenes Martin Sundermeyer, Arsalan Mousavian, Rudolph Triebel, Dieter
148 Dec 28, 2022
Official implementation for (Show, Attend and Distill: Knowledge Distillation via Attention-based Feature Matching, AAAI-2021)
Show, Attend and Distill: Knowledge Distillation via Attention-based Feature Matching Official pytorch implementation of "Show, Attend and Distill: Kn
 80 Dec 16, 2022
80 Dec 16, 2022

Code for CVPR 2021 oral paper "Exploring Data-Efficient 3D Scene Understanding with Contrastive Scene Contexts"
Exploring Data-Efficient 3D Scene Understanding with Contrastive Scene Contexts The rapid progress in 3D scene understanding has come with growing dem
182 Dec 30, 2022
Code for NAACL 2021 full paper "Efficient Attentions for Long Document Summarization"
LongDocSum Code for NAACL 2021 paper "Efficient Attentions for Long Document Summarization" This repository contains data and models needed to reprodu
 56 Jan 2, 2023
56 Jan 2, 2023
Local Attention - Flax module for Jax
Local Attention - Flax Autoregressive Local Attention - Flax module for Jax Install $ pip install local-attention-flax Usage from jax import random fr
16 Jun 16, 2022

ActNN: Reducing Training Memory Footprint via 2-Bit Activation Compressed Training
ActNN : Activation Compressed Training This is the official project repository for ActNN: Reducing Training Memory Footprint via 2-Bit Activation Comp
 178 Jan 5, 2023
178 Jan 5, 2023

PyTorch code of my ICDAR 2021 paper Vision Transformer for Fast and Efficient Scene Text Recognition (ViTSTR)
Vision Transformer for Fast and Efficient Scene Text Recognition (ICDAR 2021) ViTSTR is a simple single-stage model that uses a pre-trained Vision Tra
 198 Dec 27, 2022
198 Dec 27, 2022
Implementation of Bidirectional Recurrent Independent Mechanisms (Learning to Combine Top-Down and Bottom-Up Signals in Recurrent Neural Networks with Attention over Modules)
BRIMs Bidirectional Recurrent Independent Mechanisms Implementation of the paper Learning to Combine Top-Down and Bottom-Up Signals in Recurrent Neura
 26 May 26, 2022
26 May 26, 2022
PyTorch code for our paper "Attention in Attention Network for Image Super-Resolution"
Under construction... Attention in Attention Network for Image Super-Resolution (A2N) This repository is an PyTorch implementation of the paper "Atten
 71 Dec 30, 2022
71 Dec 30, 2022

Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Parallel Tacotron2 Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
 170 Dec 27, 2022
170 Dec 27, 2022
Contains code for the paper "Vision Transformers are Robust Learners".
Vision Transformers are Robust Learners This repository contains the code for the paper Vision Transformers are Robust Learners by Sayak Paul* and Pin
103 Jan 5, 2023
Binary Passage Retriever (BPR) - an efficient passage retriever for open-domain question answering
BPR Binary Passage Retriever (BPR) is an efficient neural retrieval model for open-domain question answering. BPR integrates a learning-to-hash techni
 147 Dec 7, 2022
147 Dec 7, 2022
Python utility function to communicate with a subprocess using iterables: for when data is too big to fit in memory and has to be streamed
iterable-subprocess Python utility function to communicate with a subprocess using iterables: for when data is too big to fit in memory and has to be
 5 Jul 10, 2022
5 Jul 10, 2022
XtremeDistil framework for distilling/compressing massive multilingual neural network models to tiny and efficient models for AI at scale
XtremeDistilTransformers for Distilling Massive Multilingual Neural Networks ACL 2020 Microsoft Research [Paper] [Video] Releasing [XtremeDistilTransf
 125 Jan 4, 2023
125 Jan 4, 2023

Elara DB is an easy to use, lightweight NoSQL database that can also be used as a fast in-memory cache.
Elara DB is an easy to use, lightweight NoSQL database written for python that can also be used as a fast in-memory cache for JSON-serializable data. Includes various methods and features to manipulate data structures in-memory, protect database files and export data.
 101 Jan 4, 2023
101 Jan 4, 2023

Drone-based Joint Density Map Estimation, Localization and Tracking with Space-Time Multi-Scale Attention Network
DroneCrowd Paper Detection, Tracking, and Counting Meets Drones in Crowds: A Benchmark. Introduction This paper proposes a space-time multi-scale atte
 98 Nov 16, 2022
98 Nov 16, 2022
Python function to stream unzip all the files in a ZIP archive: without loading the entire ZIP file or any of its files into memory at once
Python function to stream unzip all the files in a ZIP archive: without loading the entire ZIP file or any of its files into memory at once
206 Jan 2, 2023
External Attention Network
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks paper : https://arxiv.org/abs/2105.02358 Jittor code will come soon
357 Dec 11, 2022
![[CVPR21] LightTrack: Finding Lightweight Neural Network for Object Tracking via One-Shot Architecture Search](https://github.com/researchmm/LightTrack/raw/main/Archs.gif)
[CVPR21] LightTrack: Finding Lightweight Neural Network for Object Tracking via One-Shot Architecture Search
LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search The official implementation of the paper LightTra
 290 Dec 24, 2022
290 Dec 24, 2022
This is a pytorch implementation of the NeurIPS paper GAN Memory with No Forgetting.
GAN Memory for Lifelong learning This is a pytorch implementation of the NeurIPS paper GAN Memory with No Forgetting. Please consider citing our paper
 43 Dec 27, 2022
43 Dec 27, 2022

Exploring whether attention is necessary for vision transformers
Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet Paper/Report TL;DR We replace the attention layer in a v
 461 Jan 7, 2023
461 Jan 7, 2023
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
8.4k Jan 1, 2023

Reformer, the efficient Transformer, in Pytorch
Reformer, the Efficient Transformer, in Pytorch This is a Pytorch implementation of Reformer https://openreview.net/pdf?id=rkgNKkHtvB It includes LSH
1.8k Dec 30, 2022
Learning Representational Invariances for Data-Efficient Action Recognition
Learning Representational Invariances for Data-Efficient Action Recognition Official PyTorch implementation for Learning Representational Invariances
 27 Nov 22, 2022
27 Nov 22, 2022

Official implementation of "Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets" (CVPR2021)
Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets This is the official implementation of "Towards Good Pract
 52 Nov 22, 2022
52 Nov 22, 2022
Implementation of "Efficient Regional Memory Network for Video Object Segmentation" (Xie et al., CVPR 2021).
RMNet This repository contains the source code for the paper Efficient Regional Memory Network for Video Object Segmentation. Cite this work @inprocee
 76 Dec 14, 2022
76 Dec 14, 2022

Twins: Revisiting the Design of Spatial Attention in Vision Transformers
Twins: Revisiting the Design of Spatial Attention in Vision Transformers Very recently, a variety of vision transformer architectures for dense predic
 482 Dec 18, 2022
482 Dec 18, 2022
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
 15k Jan 2, 2023
15k Jan 2, 2023

AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning
AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning (NeurIPS 2020) Introduction AdaShare is a novel and differentiable approach fo
 94 Dec 22, 2022
94 Dec 22, 2022
Reimplementation of the paper `Human Attention Maps for Text Classification: Do Humans and Neural Networks Focus on the Same Words? (ACL2020)`
Human Attention for Text Classification Re-implementation of the paper Human Attention Maps for Text Classification: Do Humans and Neural Networks Foc
 15 Dec 13, 2021
15 Dec 13, 2021

Official pytorch implementation of Rainbow Memory (CVPR 2021)
Rainbow Memory: Continual Learning with a Memory of Diverse Samples
91 Dec 17, 2022